Recursive Decomposition of Logical Thoughts: Framework for Superior Reasoning and Knowledge Propagation in Large Language Models
作者: Kaleem Ullah Qasim, Jiashu Zhang, Tariq Alsahfi, Ateeq Ur Rehman Butt
分类: cs.CL, cs.AI, cs.LG, cs.LO
发布日期: 2025-01-03
💡 一句话要点
提出递归逻辑思维分解框架以提升大语言模型推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理能力 知识传播 递归分解 逻辑思维 人工智能 机器学习
📋 核心要点
- 核心问题:现有的大语言模型在复杂推理任务中表现不足,难以有效处理多层次的逻辑推理。
- 方法要点:RDoLT框架通过递归分解任务、选择有效思维和知识传播,提升了推理能力。
- 实验或效果:在GSM8K等基准测试中,RDoLT的准确率达到90.98%,较现有技术提升6.28%。
📝 摘要(中文)
提升大语言模型的推理能力仍然是人工智能领域的一项重要挑战。本文提出了递归逻辑思维分解(RDoLT)框架,显著增强了LLM的推理性能。RDoLT基于三项关键创新:首先,将复杂的推理任务递归分解为逐步复杂的子任务;其次,采用先进的选择和评分机制来识别最有前景的推理思维;最后,集成了一个知识传播模块,模拟人类学习,通过跟踪强弱思维进行信息传播。通过在多个基准测试(如GSM8K、SVAMP、MultiArith等)上的评估,RDoLT在推理任务中表现优异,准确率达到90.98%,超越现有技术6.28%。
🔬 方法详解
问题定义:本文旨在解决大语言模型在复杂推理任务中的不足,现有方法往往无法有效处理多层次的逻辑推理,导致推理能力受限。
核心思路:RDoLT框架的核心思路是将复杂推理任务递归分解为多个逐步复杂的子任务,使得模型能够逐步理解和解决问题,同时通过选择和评分机制优化推理思维的质量。
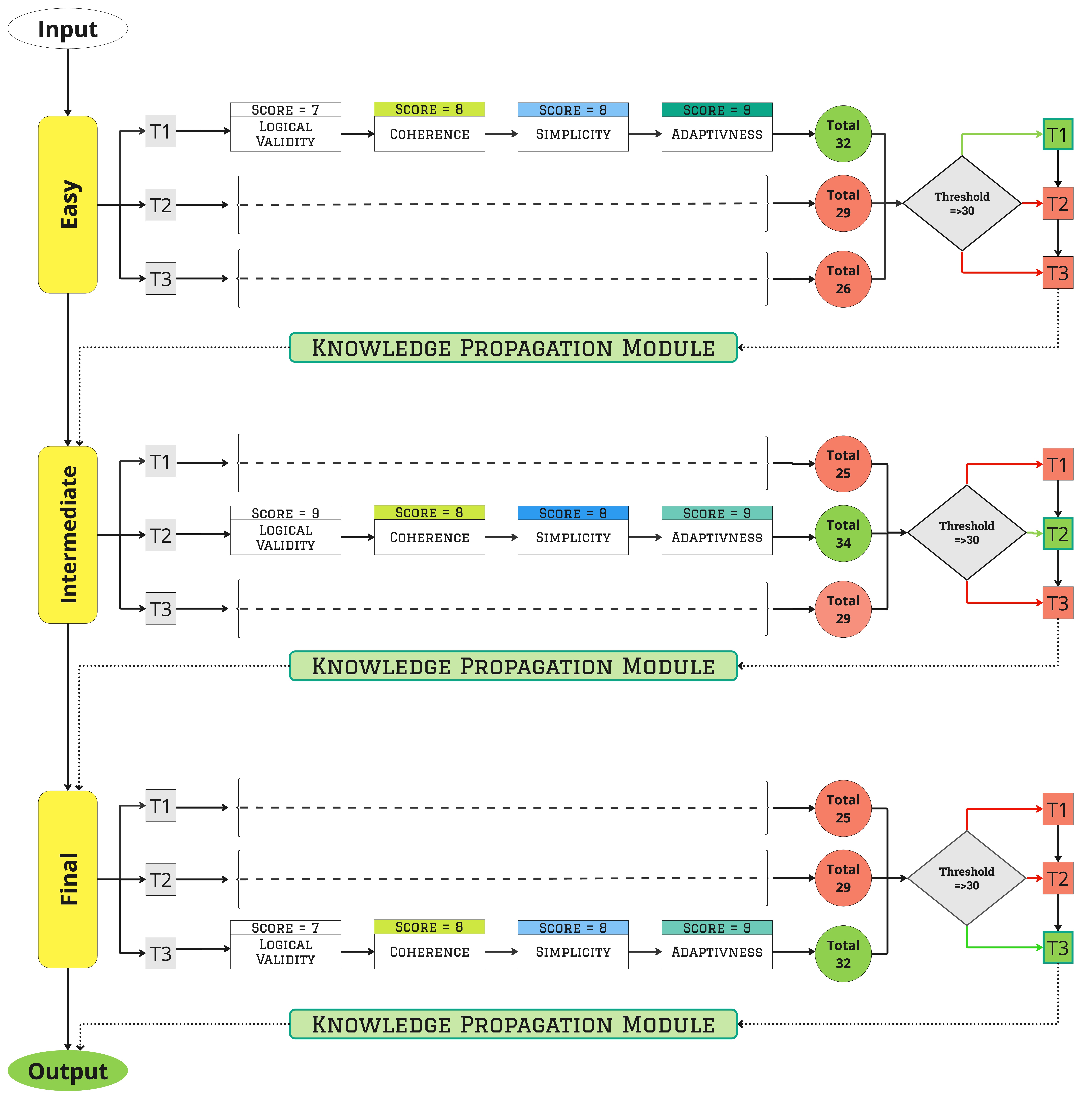
技术框架:RDoLT的整体架构包括三个主要模块:任务递归分解模块、思维选择与评分模块、知识传播模块。任务递归分解模块负责将复杂任务拆解,思维选择与评分模块用于评估和选择最佳推理思维,而知识传播模块则模拟人类学习过程,跟踪思维的强弱以进行信息传播。
关键创新:RDoLT的关键创新在于其递归分解和知识传播机制,这与现有方法的线性推理过程形成鲜明对比,能够更有效地处理复杂推理任务。
关键设计:在设计上,RDoLT采用了动态选择和评分机制,确保模型能够实时评估思维的有效性,并通过知识传播模块强化信息的流动和学习效果。
🖼️ 关键图片

📊 实验亮点
在实验中,RDoLT在GSM8K基准测试中取得了90.98%的准确率,超越了现有技术6.28%。在其他基准测试中,准确率提升幅度在5.5%到6.75%之间,显示出其广泛的适用性和优越性。
🎯 应用场景
该研究的潜在应用领域包括教育、智能问答系统和复杂决策支持等。通过提升大语言模型的推理能力,RDoLT能够在更复杂的场景中提供更准确的答案,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
Enhancing the reasoning capabilities of Large Language Models remains a critical challenge in artificial intelligence. We introduce RDoLT, Recursive Decomposition of Logical Thought prompting, a novel framework that significantly boosts LLM reasoning performance. RDoLT is built on three key innovations: (1) recursively breaking down complex reasoning tasks into sub-tasks of progressive complexity; (2) employing an advanced selection and scoring mechanism to identify the most promising reasoning thoughts; and (3) integrating a knowledge propagation module that mimics human learning by keeping track of strong and weak thoughts for information propagation. Our approach was evaluated across multiple benchmarks, including GSM8K, SVAMP, MultiArith, LastLetterConcatenation, and Gaokao2023 Math. The results demonstrate that RDoLT consistently outperforms existing state-of-the-art techniques, achieving a 90.98 percent accuracy on GSM8K with ChatGPT-4, surpassing state-of-the-art techniques by 6.28 percent. Similar improvements were observed on other benchmarks, with accuracy gains ranging from 5.5 percent to 6.75 percent. These findings highlight RDoLT's potential to advance prompt engineering, offering a more effective and generalizable approach to complex reasoning tasks.