Time Series Language Model for Descriptive Caption Generation
作者: Mohamed Trabelsi, Aidan Boyd, Jin Cao, Huseyin Uzunalioglu
分类: cs.CL, cs.LG
发布日期: 2025-01-03
💡 一句话要点
提出TSLM:一种用于时间序列描述性字幕生成的时间序列语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列 字幕生成 语言模型 数据增强 跨模态检索
📋 核心要点
- 现有方法在时间序列字幕生成任务中面临数据稀缺的挑战,阻碍了大型语言模型(LLM)的应用。
- TSLM通过上下文提示合成数据生成和跨模态密集检索评分去噪,有效缓解了数据稀缺问题。
- 实验结果表明,TSLM在多个时间序列字幕生成数据集上显著优于现有最先进的方法。
📝 摘要(中文)
为时间序列数据中可观察模式自动生成具有代表性的自然语言描述,可以增强可解释性,简化分析并提高时序数据的跨领域效用。虽然预训练的基础模型在自然语言处理(NLP)和计算机视觉(CV)领域取得了显著进展,但由于数据稀缺,它们在时间序列分析中的应用受到阻碍。尽管已经提出了几种基于大型语言模型(LLM)的时间序列预测方法,但在LLM的背景下,时间序列字幕生成的研究还不够充分。本文介绍了一种专门为时间序列字幕生成而设计的新型时间序列语言模型TSLM。TSLM作为一个编码器-解码器模型运行,利用文本提示和时间序列数据表示来捕获跨多个阶段的细微时间模式,并生成时间序列输入的精确文本描述。TSLM通过首先利用上下文提示合成数据生成,然后通过应用于时间序列-字幕对的新型跨模态密集检索评分来对生成的数据进行去噪,从而解决了时间序列字幕生成中的数据稀缺问题。在各种时间序列字幕生成数据集上的实验结果表明,TSLM在很大程度上优于来自多种数据模态的现有最先进方法。
🔬 方法详解
问题定义:论文旨在解决时间序列数据的描述性字幕生成问题。现有方法,特别是基于大型语言模型的方法,在时间序列字幕生成任务中面临数据稀缺的挑战,限制了其性能和泛化能力。缺乏足够数量的标注数据,使得模型难以学习时间序列模式与自然语言描述之间的对应关系。
核心思路:论文的核心思路是利用大型语言模型的生成能力,通过上下文提示生成合成数据,并使用跨模态检索方法对生成的数据进行去噪,从而缓解数据稀缺问题。这种方法结合了数据增强和数据清洗,旨在提高模型的训练效率和生成质量。
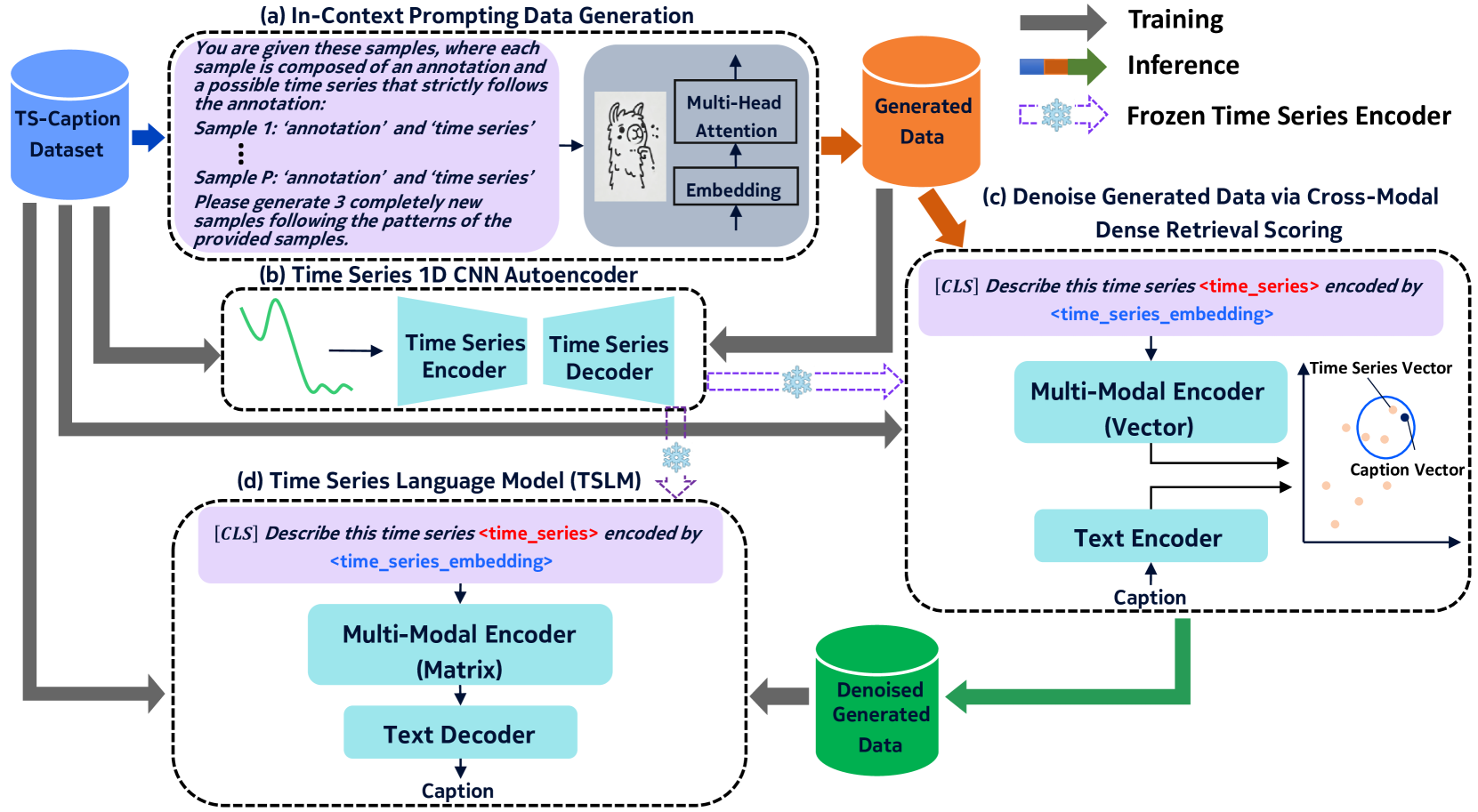
技术框架:TSLM采用编码器-解码器架构。编码器负责将时间序列数据和文本提示转换为统一的表示空间。解码器则基于编码器的输出生成时间序列的描述性字幕。整个框架包含以下主要阶段:1) 上下文提示合成数据生成;2) 跨模态密集检索评分;3) 模型训练。
关键创新:论文的关键创新在于结合了上下文提示的合成数据生成和跨模态密集检索评分。上下文提示允许模型利用少量真实数据生成大量具有多样性的合成数据。跨模态密集检索评分则用于评估合成数据的质量,并去除噪声数据,从而提高模型的训练效果。
关键设计:在上下文提示合成数据生成阶段,论文使用了特定的提示模板,引导大型语言模型生成与时间序列数据相关的描述性字幕。在跨模态密集检索评分阶段,论文设计了一种新的评分函数,该函数考虑了时间序列数据和字幕之间的语义相似性。具体的网络结构和损失函数细节在论文中进行了详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
TSLM在多个时间序列字幕生成数据集上取得了显著的性能提升,超越了现有最先进的方法。具体的性能数据和提升幅度在论文中进行了详细报告(未知)。实验结果表明,TSLM能够生成更准确、更具描述性的时间序列字幕,有效提高了时间序列数据的可解释性。
🎯 应用场景
该研究成果可应用于多个领域,例如金融分析、医疗健康、工业监控等。通过自动生成时间序列数据的描述性字幕,可以帮助领域专家更好地理解和分析数据,从而做出更明智的决策。此外,该技术还可以用于构建智能监控系统,自动检测异常事件并生成相应的警报。
📄 摘要(原文)
The automatic generation of representative natural language descriptions for observable patterns in time series data enhances interpretability, simplifies analysis and increases cross-domain utility of temporal data. While pre-trained foundation models have made considerable progress in natural language processing (NLP) and computer vision (CV), their application to time series analysis has been hindered by data scarcity. Although several large language model (LLM)-based methods have been proposed for time series forecasting, time series captioning is under-explored in the context of LLMs. In this paper, we introduce TSLM, a novel time series language model designed specifically for time series captioning. TSLM operates as an encoder-decoder model, leveraging both text prompts and time series data representations to capture subtle temporal patterns across multiple phases and generate precise textual descriptions of time series inputs. TSLM addresses the data scarcity problem in time series captioning by first leveraging an in-context prompting synthetic data generation, and second denoising the generated data via a novel cross-modal dense retrieval scoring applied to time series-caption pairs. Experimental findings on various time series captioning datasets demonstrate that TSLM outperforms existing state-of-the-art approaches from multiple data modalities by a significant margin.