MIRAGE: Exploring How Large Language Models Perform in Complex Social Interactive Environments
作者: Yin Cai, Zhouhong Gu, Zhaohan Du, Zheyu Ye, Shaosheng Cao, Yiqian Xu, Hongwei Feng, Ping Chen
分类: cs.CL
发布日期: 2025-01-03 (更新: 2026-01-18)
🔗 代码/项目: GITHUB
💡 一句话要点
MIRAGE:构建复杂社交互动环境,评估大型语言模型在角色扮演中的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 角色扮演 社交互动 评估框架 信任倾向 线索调查 人机交互 多智能体
📋 核心要点
- 现有大型语言模型在复杂社交互动环境中的角色扮演能力评估不足,缺乏统一的评测基准。
- MIRAGE框架通过构建多重宇宙谋杀之谜游戏,模拟复杂的人类社交互动,为LLM的角色扮演能力提供综合评估。
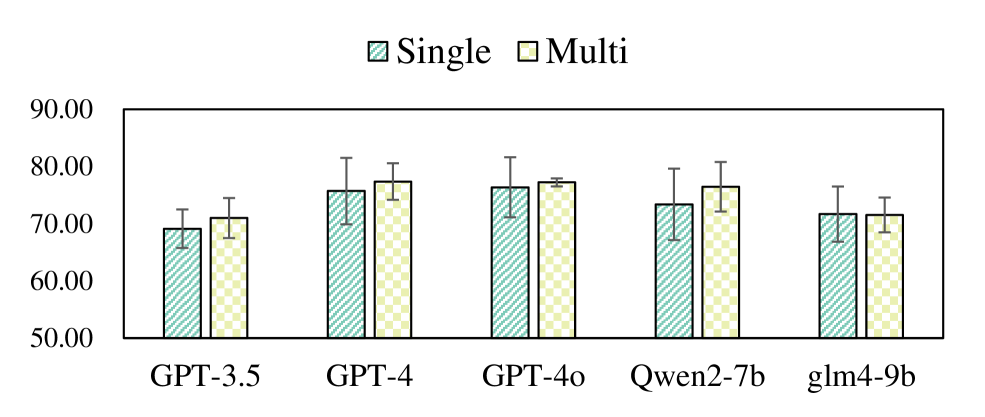
- 实验结果表明,即使是GPT-4等先进模型在MIRAGE框架下也面临挑战,表明该框架能有效区分LLM在复杂社交环境中的表现。
📝 摘要(中文)
本文提出了多重宇宙互动角色扮演能力通用评估框架(MIRAGE),旨在评估大型语言模型(LLMs)在通过谋杀之谜游戏展现高级人类行为方面的能力。MIRAGE包含八个精心设计的剧本,涵盖不同的主题和风格,提供丰富的模拟环境。为了评估LLMs的性能,MIRAGE采用了四种不同的方法:信任倾向指数(TII)用于测量信任和怀疑的动态变化,线索调查能力(CIC)用于测量LLMs进行信息收集的能力,互动能力指数(ICI)用于评估角色扮演能力,以及剧本合规指数(SCI)用于评估LLMs理解和遵循指令的能力。实验表明,即使是像GPT-4这样流行的模型,在应对MIRAGE提出的复杂性时也面临着重大挑战。数据集和模拟代码已在github上公开。
🔬 方法详解
问题定义:现有的大型语言模型在环境感知、基于推理的决策制定以及模拟复杂人类行为方面表现出显著的能力,尤其是在互动角色扮演环境中。然而,缺乏一个综合性的框架来评估LLM在复杂社交互动环境(例如,涉及信任、欺骗和信息收集的场景)中扮演角色的能力。现有方法难以捕捉LLM在这些复杂场景下的细微表现,例如理解和利用社交线索、维持角色一致性以及有效互动。
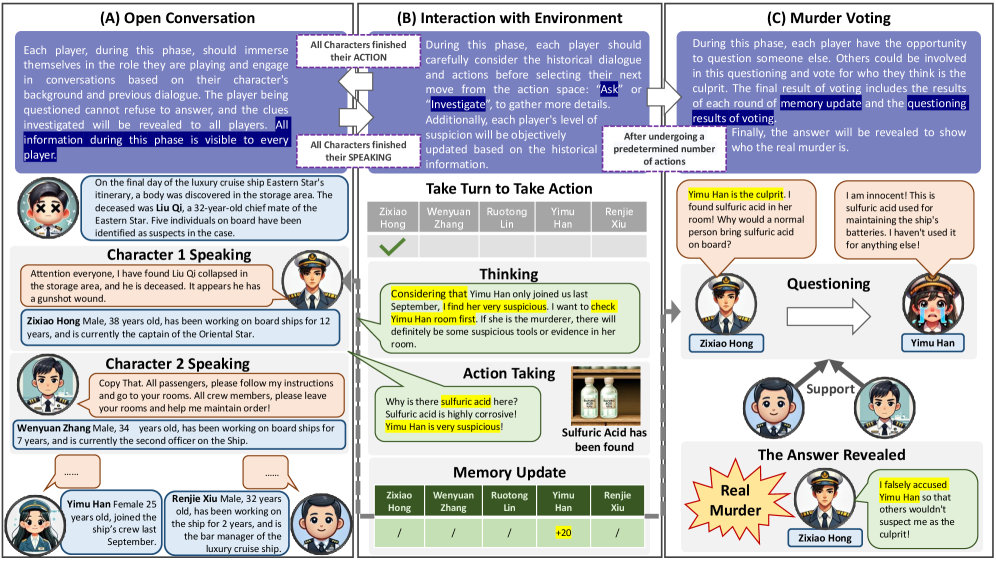
核心思路:MIRAGE的核心思路是构建一个多重宇宙互动角色扮演环境,通过模拟谋杀之谜游戏来评估LLM在复杂社交互动中的能力。这种方法允许研究人员观察LLM在不同角色和剧本下的行为,并使用一系列指标来量化其表现。通过精心设计的剧本和评估指标,MIRAGE旨在全面评估LLM在理解社交动态、进行信息收集、维持角色一致性以及遵循指令方面的能力。
技术框架:MIRAGE框架包含以下主要组成部分: 1. 剧本设计:八个精心设计的剧本,涵盖不同的主题和风格,提供丰富的模拟环境。 2. 角色分配:为每个LLM分配一个特定的角色,并提供相应的背景信息和目标。 3. 互动模拟:LLM之间进行互动,模拟角色扮演过程。 4. 评估指标:使用四种不同的指标来评估LLM的性能:TII、CIC、ICI和SCI。
关键创新:MIRAGE的关键创新在于其综合性的评估框架,该框架不仅考虑了LLM的角色扮演能力,还考虑了其在复杂社交互动中的表现。与现有方法相比,MIRAGE更注重评估LLM在理解社交动态、进行信息收集、维持角色一致性以及遵循指令方面的能力。此外,MIRAGE还提供了一个丰富的模拟环境,允许研究人员观察LLM在不同角色和剧本下的行为。
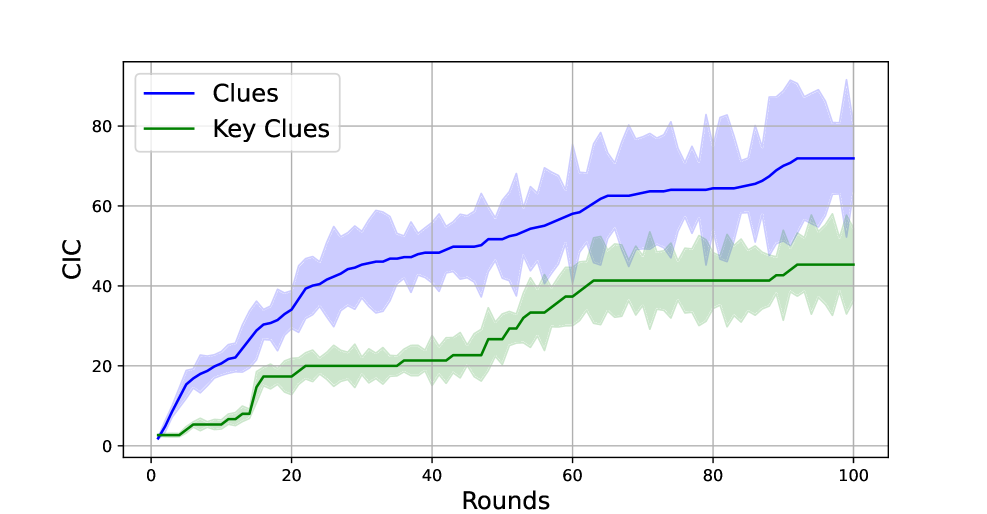
关键设计:MIRAGE的关键设计包括: * 信任倾向指数(TII):用于测量LLM在互动过程中信任和怀疑的动态变化。 * 线索调查能力(CIC):用于测量LLM进行信息收集和线索调查的能力。 * 互动能力指数(ICI):用于评估LLM的角色扮演能力,例如角色一致性和互动质量。 * 剧本合规指数(SCI):用于评估LLM理解和遵循剧本指令的能力。这些指标的设计旨在全面评估LLM在复杂社交互动中的表现。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使是GPT-4等先进模型在MIRAGE框架下也面临挑战,尤其是在信任倾向指数(TII)和线索调查能力(CIC)方面表现不佳。这表明现有LLM在理解和利用社交线索、进行有效信息收集方面仍有提升空间。MIRAGE框架能够有效区分不同LLM在复杂社交环境中的表现,为LLM的改进提供了有价值的参考。
🎯 应用场景
MIRAGE框架可应用于评估和改进大型语言模型在社交机器人、虚拟助手和游戏AI等领域的应用。通过MIRAGE的评估,可以更好地了解LLM在复杂社交环境中的优势和不足,从而指导模型的设计和训练,使其能够更好地理解和适应人类社交行为,提升人机交互的自然性和有效性。此外,该框架还可用于研究人类社交行为的计算建模。
📄 摘要(原文)
Large Language Models (LLMs) have shown remarkable capabilities in environmental perception, reasoning-based decision-making, and simulating complex human behaviors, particularly in interactive role-playing contexts. This paper introduces the Multiverse Interactive Role-play Ability General Evaluation (MIRAGE), a comprehensive framework designed to assess LLMs' proficiency in portraying advanced human behaviors through murder mystery games. MIRAGE features eight intricately crafted scripts encompassing diverse themes and styles, providing a rich simulation. To evaluate LLMs' performance, MIRAGE employs four distinct methods: the Trust Inclination Index (TII) to measure dynamics of trust and suspicion, the Clue Investigation Capability (CIC) to measure LLMs' capability of conducting information, the Interactivity Capability Index (ICI) to assess role-playing capabilities and the Script Compliance Index (SCI) to assess LLMs' capability of understanding and following instructions. Our experiments indicate that even popular models like GPT-4 face significant challenges in navigating the complexities presented by the MIRAGE. The datasets and simulation codes are available in \href{https://github.com/lime728/MIRAGE}{github}.