OmniChat: Enhancing Spoken Dialogue Systems with Scalable Synthetic Data for Diverse Scenarios
作者: Xize Cheng, Dongjie Fu, Xiaoda Yang, Minghui Fang, Ruofan Hu, Jingyu Lu, Bai Jionghao, Zehan Wang, Shengpeng Ji, Rongjie Huang, Linjun Li, Yu Chen, Tao Jin, Zhou Zhao
分类: cs.CL, cs.HC, cs.SD, eess.AS
发布日期: 2025-01-02
💡 一句话要点
OmniChat:利用可扩展的合成数据增强口语对话系统,覆盖多样化场景
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 口语对话系统 合成数据 数据增强 多模态融合 异构特征 ShareChatX DailyTalk
📋 核心要点
- 现有口语对话系统难以处理真实世界对话的复杂性,主要受限于数据集的规模和场景多样性。
- 论文提出利用合成数据增强对话模型,并构建了大规模口语对话数据集ShareChatX。
- OmniChat系统通过异构特征融合模块优化特征选择,并在DailyTalk数据集上取得了SOTA结果。
📝 摘要(中文)
随着大型语言模型的快速发展,研究人员创造了越来越先进的口语对话系统,可以自然地与人类交谈。然而,这些系统仍然难以处理现实世界对话的全部复杂性,包括音频事件、音乐环境和情感表达,这主要是因为当前的对话数据集在规模和场景多样性方面都受到限制。在本文中,我们提出利用合成数据来增强各种场景下的对话模型。我们介绍了ShareChatX,这是第一个全面的、大规模的口语对话数据集,涵盖了各种场景。基于此数据集,我们引入了OmniChat,一个具有异构特征融合模块的多轮对话系统,旨在优化不同对话上下文中的特征选择。此外,我们探索了使用合成数据训练对话系统的关键方面。通过全面的实验,我们确定了合成数据和真实数据之间的理想平衡,在真实世界的对话数据集DailyTalk上取得了最先进的结果。我们还强调了合成数据在处理各种复杂的对话场景,特别是涉及音频和音乐的场景中的重要性。
🔬 方法详解
问题定义:现有口语对话系统在处理真实场景,特别是包含音频事件、音乐环境和情感表达的复杂对话时表现不佳。主要原因是现有数据集规模有限,场景覆盖不足,导致模型泛化能力弱。
核心思路:论文的核心思路是利用合成数据来扩充训练数据集,从而提升对话系统在多样化场景下的性能。通过生成包含各种音频、音乐和情感信息的对话数据,弥补真实数据集中场景覆盖不足的问题。
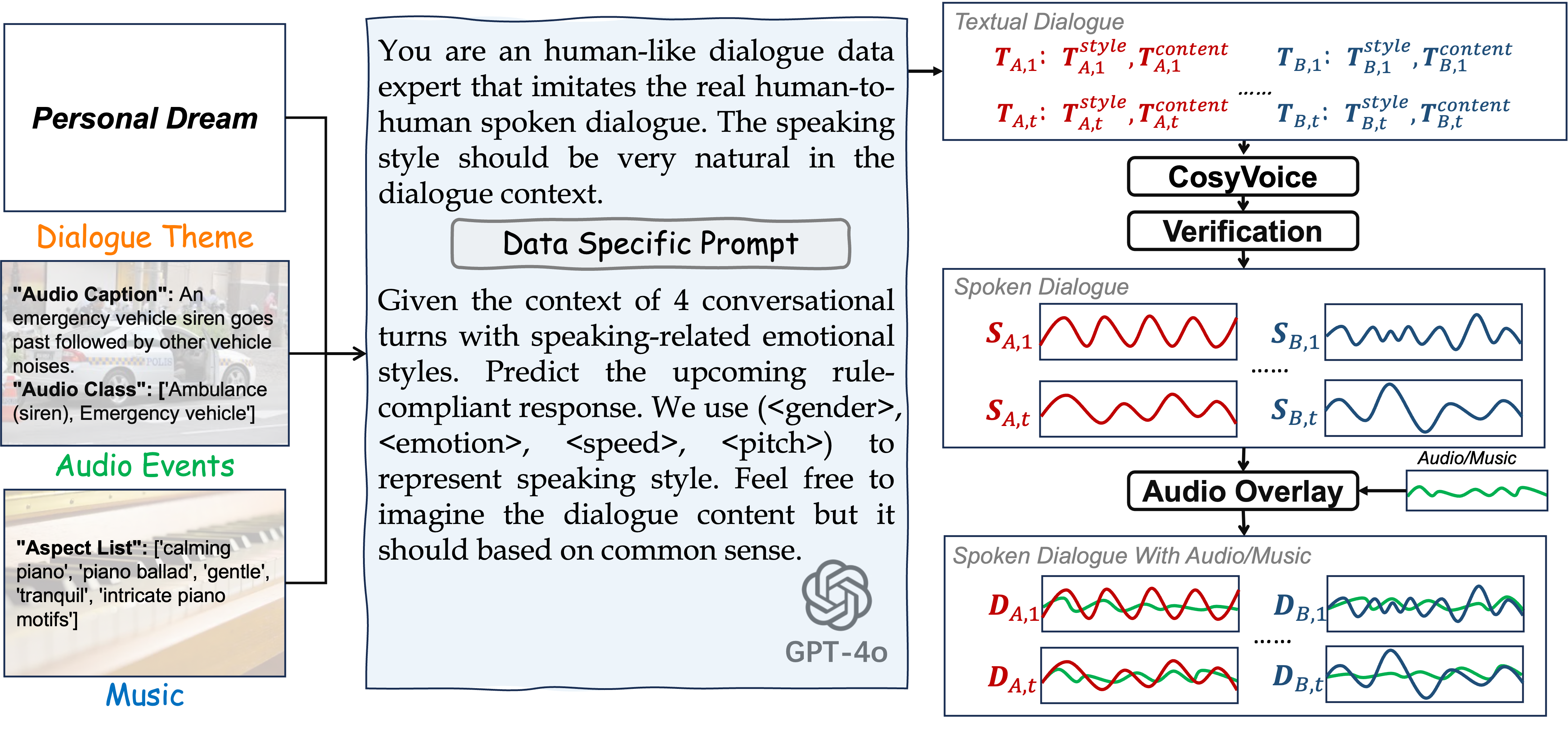
技术框架:OmniChat系统基于ShareChatX数据集进行训练。该系统包含一个异构特征融合模块,用于处理来自不同模态(例如文本、音频)的特征。训练过程中,探索了合成数据和真实数据的最佳比例,以最大化模型性能。
关键创新:关键创新在于利用合成数据来增强口语对话系统,特别是在处理音频和音乐相关的对话场景方面。通过ShareChatX数据集,提供了一个大规模、多样化的训练资源,并证明了合成数据在提升模型泛化能力方面的有效性。
关键设计:OmniChat系统的异构特征融合模块的具体结构未知,论文中可能没有详细描述。合成数据和真实数据的比例选择是通过实验确定的,具体比例值未知。损失函数和网络结构等细节也未在摘要中提及,需要查阅论文全文才能了解。
🖼️ 关键图片

📊 实验亮点
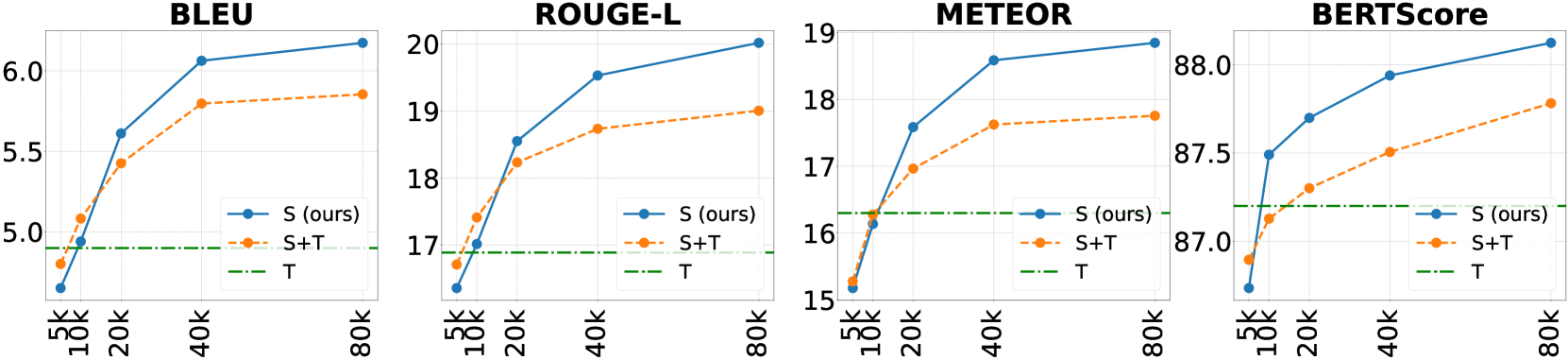
论文在真实世界的对话数据集DailyTalk上取得了最先进的结果,证明了合成数据在提升对话系统性能方面的有效性。特别是在处理包含音频和音乐的复杂对话场景时,合成数据的作用更加显著。具体的性能提升幅度未知,需要查阅论文全文。
🎯 应用场景
该研究成果可应用于智能客服、语音助手、社交机器人等领域,提升这些系统在复杂真实场景下的对话能力。特别是在音乐推荐、情感支持等需要理解音频和情感信息的应用中,具有重要的实际价值和潜在影响。未来,该方法可以推广到其他多模态对话系统,进一步提升人机交互的自然性和流畅性。
📄 摘要(原文)
With the rapid development of large language models, researchers have created increasingly advanced spoken dialogue systems that can naturally converse with humans. However, these systems still struggle to handle the full complexity of real-world conversations, including audio events, musical contexts, and emotional expressions, mainly because current dialogue datasets are constrained in both scale and scenario diversity. In this paper, we propose leveraging synthetic data to enhance the dialogue models across diverse scenarios. We introduce ShareChatX, the first comprehensive, large-scale dataset for spoken dialogue that spans diverse scenarios. Based on this dataset, we introduce OmniChat, a multi-turn dialogue system with a heterogeneous feature fusion module, designed to optimize feature selection in different dialogue contexts. In addition, we explored critical aspects of training dialogue systems using synthetic data. Through comprehensive experimentation, we determined the ideal balance between synthetic and real data, achieving state-of-the-art results on the real-world dialogue dataset DailyTalk. We also highlight the crucial importance of synthetic data in tackling diverse, complex dialogue scenarios, especially those involving audio and music. For more details, please visit our demo page at \url{https://sharechatx.github.io/}.