CodeElo: Benchmarking Competition-level Code Generation of LLMs with Human-comparable Elo Ratings
作者: Shanghaoran Quan, Jiaxi Yang, Bowen Yu, Bo Zheng, Dayiheng Liu, An Yang, Xuancheng Ren, Bofei Gao, Yibo Miao, Yunlong Feng, Zekun Wang, Jian Yang, Zeyu Cui, Yang Fan, Yichang Zhang, Binyuan Hui, Junyang Lin
分类: cs.CL
发布日期: 2025-01-02 (更新: 2025-01-03)
💡 一句话要点
CodeElo:提出基于Elo等级分的LLM代码生成能力竞赛级评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 评测基准 Elo等级分 CodeForces
📋 核心要点
- 现有代码生成评测基准缺乏私有测试用例、特殊评判支持和一致的执行环境,难以有效评估LLM的竞赛级编码能力。
- CodeElo通过模拟CodeForces平台,采用直接提交和Elo等级分系统,提供了一个标准化的、与人类表现可比的评测环境。
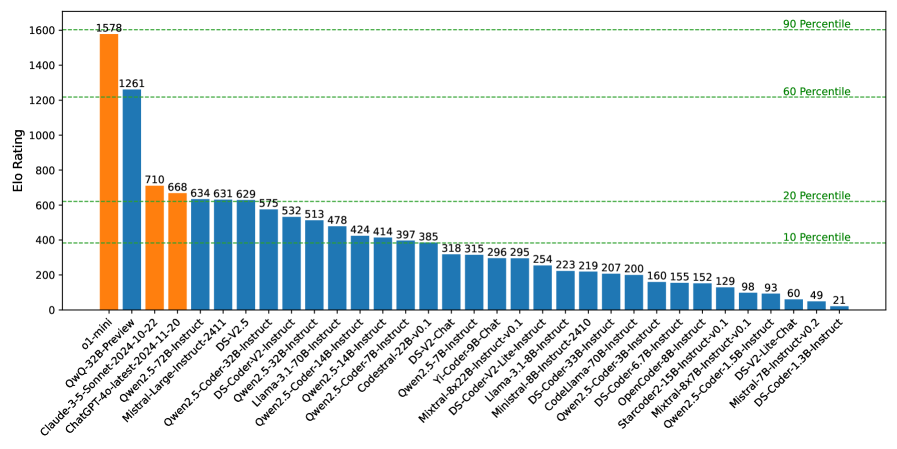
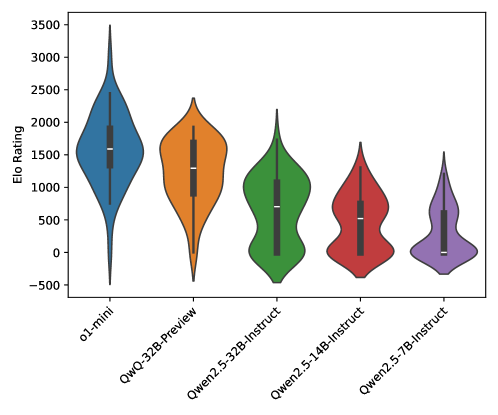
- 实验结果表明,o1-mini和QwQ-32B-Preview在CodeElo上表现突出,但其他模型在简单问题上仍表现不佳,有较大提升空间。
📝 摘要(中文)
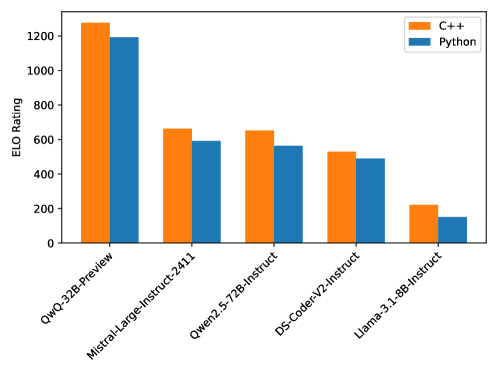
随着大型语言模型(LLM)代码推理能力的增强,以及OpenAI o1和o3等推理模型的突破,迫切需要开发更具挑战性和综合性的基准,以有效测试其复杂的竞赛级编码能力。现有的基准,如LiveCodeBench和USACO,由于缺乏私有测试用例、不支持特殊评判以及执行环境不一致而存在不足。为了弥补这一差距,我们推出了CodeElo,这是一个标准化的竞赛级代码生成基准,首次有效解决了所有这些挑战。CodeElo基准主要基于官方CodeForces平台,并尽可能与该平台保持一致。我们整理了CodeForces最近六个月的竞赛问题,包括竞赛级别、问题难度等级和问题算法标签等详细信息。我们引入了一种独特的评判方法,将问题直接提交到平台,并开发了一个可靠的Elo等级分计算系统,该系统与平台对齐,可与人类参与者相媲美,但方差较低。通过在CodeElo上进行测试,我们首次提供了30个现有流行的开源和3个专有LLM的Elo等级分。结果表明,o1-mini和QwQ-32B-Preview表现突出,分别达到了1578和1261的Elo等级分,而其他模型即使是最简单的问题也难以解决,在所有人类参与者中排名最低的25%。我们还进行了详细的分析实验,以深入了解不同算法的性能以及C++和Python之间的比较,这可以为未来的研究提供方向。
🔬 方法详解
问题定义:现有代码生成评测基准,如LiveCodeBench和USACO,无法充分评估LLM在竞赛级别的编码能力。这些基准存在私有测试用例缺失,不支持特殊评判,以及执行环境与实际竞赛环境不一致等问题,导致评测结果的可靠性和代表性不足。因此,需要一个更具挑战性、更全面、更贴近真实竞赛环境的评测基准。
核心思路:CodeElo的核心思路是模拟真实的CodeForces竞赛环境,通过将LLM生成的代码直接提交到CodeForces平台进行评判,并采用与CodeForces类似的Elo等级分系统来评估LLM的编码能力。这种方法能够更准确地反映LLM在实际竞赛中的表现,并提供与人类选手可比的评估结果。
技术框架:CodeElo的技术框架主要包括以下几个部分:1) 问题收集:收集CodeForces平台上最近六个月的竞赛问题,并整理问题的详细信息,如竞赛级别、难度等级和算法标签。2) 评判系统:将LLM生成的代码直接提交到CodeForces平台进行评判,获取评判结果。3) Elo等级分计算:根据评判结果,采用与CodeForces类似的Elo等级分系统计算LLM的等级分。4) 结果分析:对实验结果进行详细分析,包括不同算法的性能比较、C++和Python的性能比较等。
关键创新:CodeElo最重要的技术创新点在于其评判方法和Elo等级分计算系统。该评判方法直接将LLM生成的代码提交到真实的竞赛平台进行评判,避免了因模拟环境与真实环境差异而导致的评估偏差。Elo等级分计算系统与CodeForces平台对齐,使得LLM的等级分能够与人类选手的等级分进行直接比较,从而更准确地评估LLM的编码能力。
关键设计:CodeElo的关键设计包括:1) 问题选择:选择最近六个月的CodeForces竞赛问题,以保证问题的时效性和代表性。2) 评判环境:直接使用CodeForces平台进行评判,以保证评判环境的真实性和可靠性。3) Elo等级分计算:采用与CodeForces类似的Elo等级分计算公式,并根据实际情况进行调整,以保证等级分计算的准确性和可比性。
🖼️ 关键图片
📊 实验亮点
CodeElo首次提供了30个开源和3个专有LLM的Elo等级分。实验结果表明,o1-mini和QwQ-32B-Preview表现突出,分别达到了1578和1261的Elo等级分。其他模型在简单问题上表现不佳,表明现有LLM在竞赛级代码生成方面仍有很大的提升空间。
🎯 应用场景
CodeElo可用于评估和比较不同LLM的代码生成能力,指导LLM的训练和优化,并促进代码生成技术的发展。此外,CodeElo还可以应用于教育领域,帮助学生提高编程能力,并为编程竞赛提供更公平的评估标准。
📄 摘要(原文)
With the increasing code reasoning capabilities of existing large language models (LLMs) and breakthroughs in reasoning models like OpenAI o1 and o3, there is a growing need to develop more challenging and comprehensive benchmarks that effectively test their sophisticated competition-level coding abilities. Existing benchmarks, like LiveCodeBench and USACO, fall short due to the unavailability of private test cases, lack of support for special judges, and misaligned execution environments. To bridge this gap, we introduce CodeElo, a standardized competition-level code generation benchmark that effectively addresses all these challenges for the first time. CodeElo benchmark is mainly based on the official CodeForces platform and tries to align with the platform as much as possible. We compile the recent six months of contest problems on CodeForces with detailed information such as contest divisions, problem difficulty ratings, and problem algorithm tags. We introduce a unique judging method in which problems are submitted directly to the platform and develop a reliable Elo rating calculation system that aligns with the platform and is comparable with human participants but has lower variance. By testing on our CodeElo, we provide the Elo ratings of 30 existing popular open-source and 3 proprietary LLMs for the first time. The results show that o1-mini and QwQ-32B-Preview stand out significantly, achieving Elo ratings of 1578 and 1261, respectively, while other models struggle even with the easiest problems, placing in the lowest 25 percent among all human participants. Detailed analysis experiments are also conducted to provide insights into performance across algorithms and comparisons between using C++ and Python, which can suggest directions for future studies.