Large Language Model-Enhanced Symbolic Reasoning for Knowledge Base Completion
作者: Qiyuan He, Jianfei Yu, Wenya Wang
分类: cs.CL
发布日期: 2025-01-02
💡 一句话要点
提出LLM增强的符号推理框架,用于提升知识库补全的灵活性和可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识库补全 大型语言模型 规则推理 符号推理 知识图谱
📋 核心要点
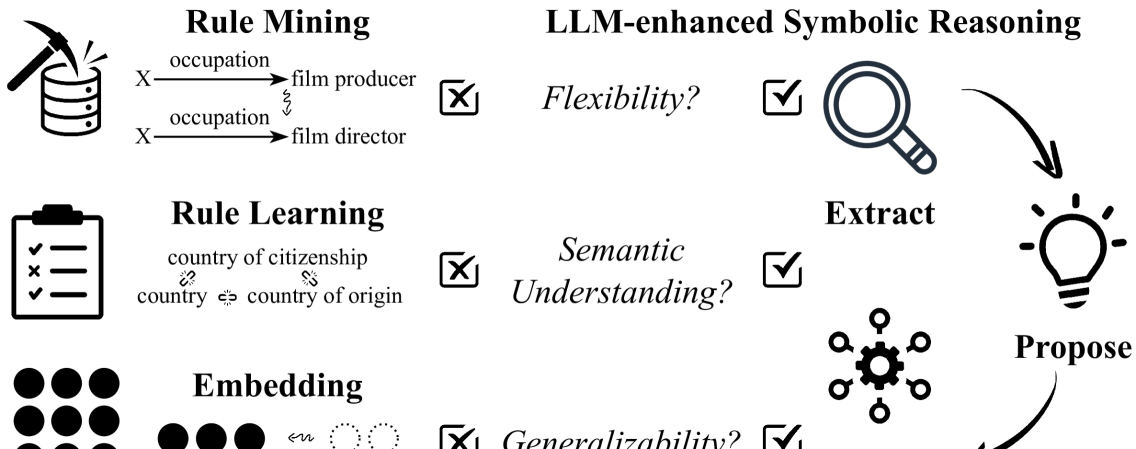
- 传统规则推理KBC方法缺乏灵活性,而LLM虽语义理解强但易产生幻觉,需要结合二者优势。
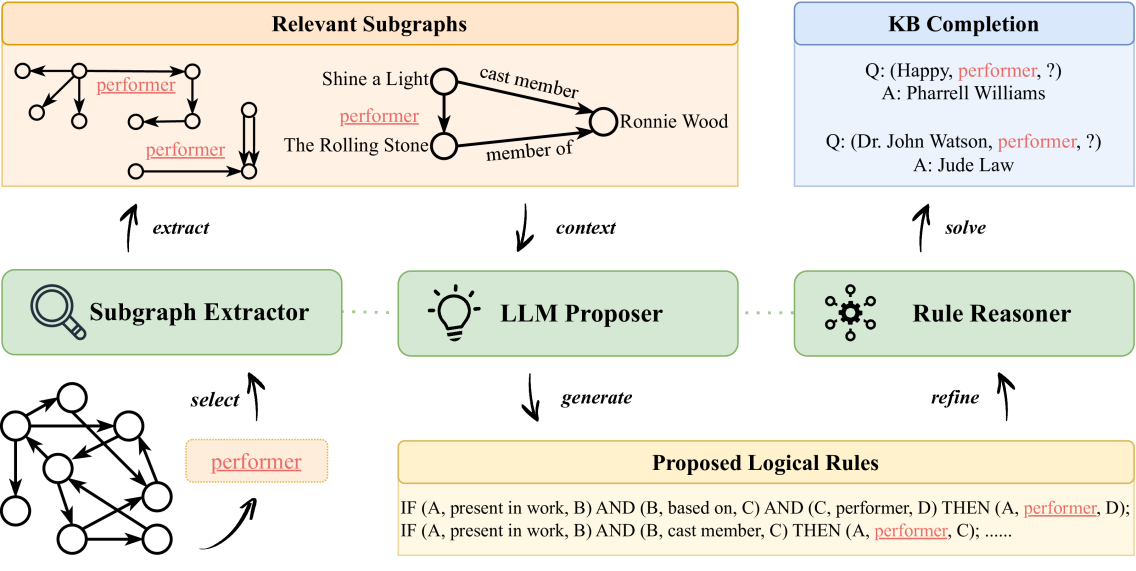
- 提出包含子图提取器、LLM规则提议器和规则推理器的框架,利用LLM生成规则并用规则推理器提炼。
- 实验表明,该方法在多个知识库数据集上表现出强大的性能,验证了框架的鲁棒性和泛化性。
📝 摘要(中文)
本文提出了一种新颖的框架,旨在结合大型语言模型(LLMs)的理解能力与基于规则推理的逻辑严谨性,从而提升知识库补全(KBC)的灵活性和可靠性。传统基于规则的KBC方法具有可验证的推理过程,但缺乏灵活性;而LLMs虽然具有强大的语义理解能力,却容易产生幻觉。该框架包含一个子图提取器、一个LLM规则提议器和一个规则推理器。子图提取器首先从知识库中采样子图,然后LLM利用这些子图提出多样且有意义的规则,用于推断缺失的事实。为了有效避免LLM生成过程中的幻觉,规则推理器进一步提炼这些规则,以确定知识库补全中最显著的规则。该方法的主要优势在于利用LLMs增强了规则的多样性和丰富性,并与基于规则的推理相结合以提高可靠性。实验结果表明,该方法在不同的知识库数据集上表现出强大的性能,突出了所提出框架的鲁棒性和泛化性。
🔬 方法详解
问题定义:知识库补全(KBC)旨在推断知识库中缺失的事实。现有基于规则的KBC方法虽然推理过程可验证,但规则生成过程僵化,缺乏灵活性。而直接使用大型语言模型(LLMs)进行KBC,虽然具有强大的语义理解能力,但容易产生幻觉,导致推理结果不可靠。
核心思路:论文的核心思路是结合LLMs的语义理解能力和规则推理的逻辑严谨性,利用LLMs生成更丰富、更多样化的规则,并通过规则推理器对LLMs生成的规则进行筛选和提炼,从而避免幻觉,提高KBC的准确性和可靠性。这样既能利用LLMs的知识,又能保证推理过程的可解释性。
技术框架:该框架主要包含三个模块:子图提取器、LLM规则提议器和规则推理器。首先,子图提取器从知识库中采样子图,为LLM提供上下文信息。然后,LLM规则提议器利用这些子图生成候选规则。最后,规则推理器对LLM生成的规则进行评估和筛选,选择最有效的规则用于知识库补全。整个流程旨在利用LLM的生成能力,同时通过规则推理保证结果的可靠性。
关键创新:该方法最重要的创新点在于将LLMs引入到规则生成过程中,从而克服了传统规则生成方法的局限性,显著提升了规则的多样性和丰富性。同时,通过规则推理器对LLMs生成的规则进行过滤,有效避免了LLMs的幻觉问题,提高了KBC的准确性。这种结合LLM和规则推理的混合方法是该论文的核心创新。
关键设计:子图提取器的采样策略影响LLM获取的上下文信息质量。LLM规则提议器的prompt设计至关重要,需要引导LLM生成高质量的规则。规则推理器需要设计合适的评分函数,评估规则的有效性,例如可以使用置信度、支持度等指标。具体的损失函数和网络结构取决于规则推理器的具体实现方式,论文中可能使用了某种规则学习算法或神经网络模型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在多个知识库数据集上取得了显著的性能提升。具体的数据和对比基线在论文中给出,总体而言,该方法在KBC任务上的准确率和召回率均优于现有方法,验证了该框架的有效性和鲁棒性。实验结果突出了LLM在规则生成方面的潜力,以及规则推理在避免幻觉方面的作用。
🎯 应用场景
该研究成果可应用于智能问答系统、推荐系统、语义搜索等领域。通过更准确地补全知识库,可以提升这些应用的信息检索和推理能力,从而提供更智能、更可靠的服务。未来,该方法有望应用于更复杂的知识图谱构建和维护任务,促进人工智能的进一步发展。
📄 摘要(原文)
Integrating large language models (LLMs) with rule-based reasoning offers a powerful solution for improving the flexibility and reliability of Knowledge Base Completion (KBC). Traditional rule-based KBC methods offer verifiable reasoning yet lack flexibility, while LLMs provide strong semantic understanding yet suffer from hallucinations. With the aim of combining LLMs' understanding capability with the logical and rigor of rule-based approaches, we propose a novel framework consisting of a Subgraph Extractor, an LLM Proposer, and a Rule Reasoner. The Subgraph Extractor first samples subgraphs from the KB. Then, the LLM uses these subgraphs to propose diverse and meaningful rules that are helpful for inferring missing facts. To effectively avoid hallucination in LLMs' generations, these proposed rules are further refined by a Rule Reasoner to pinpoint the most significant rules in the KB for Knowledge Base Completion. Our approach offers several key benefits: the utilization of LLMs to enhance the richness and diversity of the proposed rules and the integration with rule-based reasoning to improve reliability. Our method also demonstrates strong performance across diverse KB datasets, highlighting the robustness and generalizability of the proposed framework.