BlockDialect: Block-wise Fine-grained Mixed Format Quantization for Energy-Efficient LLM Inference
作者: Wonsuk Jang, Thierry Tambe
分类: cs.CL, cs.LG
发布日期: 2025-01-02 (更新: 2025-07-24)
备注: ICML 2025
💡 一句话要点
BlockDialect:面向节能LLM推理的块状细粒度混合格式量化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 量化 大型语言模型 低精度计算 混合精度量化 能源效率 模型推理 激活量化
📋 核心要点
- 现有量化方法难以充分捕捉LLM中块数据的细微分布特征,导致量化精度受限。
- BlockDialect通过为每个块自适应地选择最佳数字格式,实现更精确的数据表示,提升量化性能。
- 实验表明,BlockDialect在LLaMA模型上显著提升了精度,同时降低了比特使用量,实现了更节能的推理。
📝 摘要(中文)
大型语言模型(LLM)的规模迅速增长,给内存使用和计算成本带来了重大挑战。量化权重和激活可以解决这些问题,而硬件支持的细粒度缩放已成为缓解异常值的有希望的解决方案。然而,现有方法难以捕捉细致的块数据分布。我们提出了BlockDialect,一种块状细粒度混合格式技术,它从格式手册中为每个块分配一个最佳数字格式,以实现更好的数据表示。此外,我们还引入了DialectFP4,一个FP4变体(类似于方言)的格式手册,可以适应不同的数据分布。为了有效地利用这一点,我们提出了一种用于在线DialectFP4激活量化的两阶段方法。重要的是,DialectFP4通过选择可表示的值作为与低精度整数算术兼容的缩放整数来确保能源效率。与MXFP4格式相比,BlockDialect在LLaMA3-8B(LLaMA2-7B)模型上实现了10.78%(7.48%)的精度提升,同时每个数据的比特使用量更低,即使在量化全路径矩阵乘法时,也仅比全精度低5.45%(2.69%)。我们的工作侧重于如何表示,而不是如何缩放,为节能LLM推理提供了一条有希望的途径。
🔬 方法详解
问题定义:现有的大型语言模型量化方法,尤其是在激活量化方面,难以有效地处理不同块之间数据分布的差异。简单的均匀量化或单一格式量化无法充分利用硬件的低精度计算能力,同时保持较高的模型精度。现有方法无法很好地捕捉块级别上的细粒度数据分布,导致量化损失较大。
核心思路:BlockDialect的核心思路是为每个数据块选择最合适的量化格式,从而更好地匹配该块的数据分布。通过引入一个包含多种FP4变体的“格式手册”(DialectFP4),模型可以根据块的特性自适应地选择最佳的量化格式。这种块级别的自适应量化能够更精确地表示数据,减少量化误差。
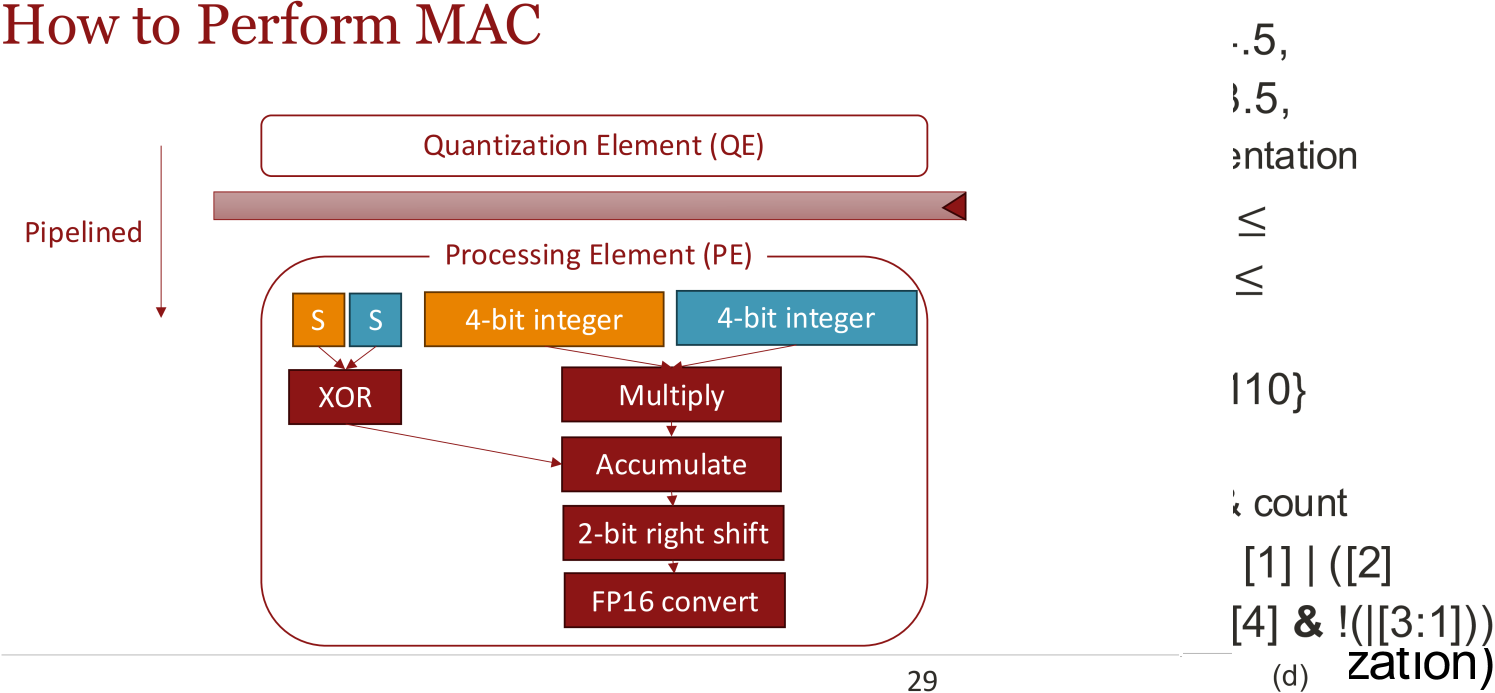
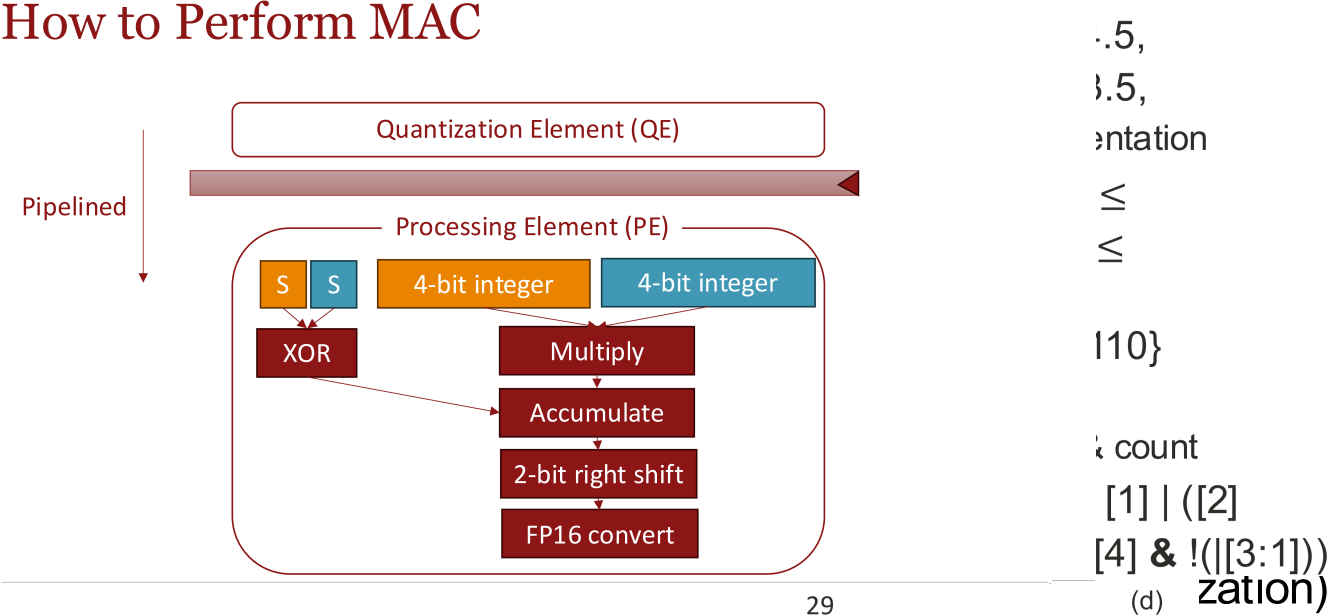
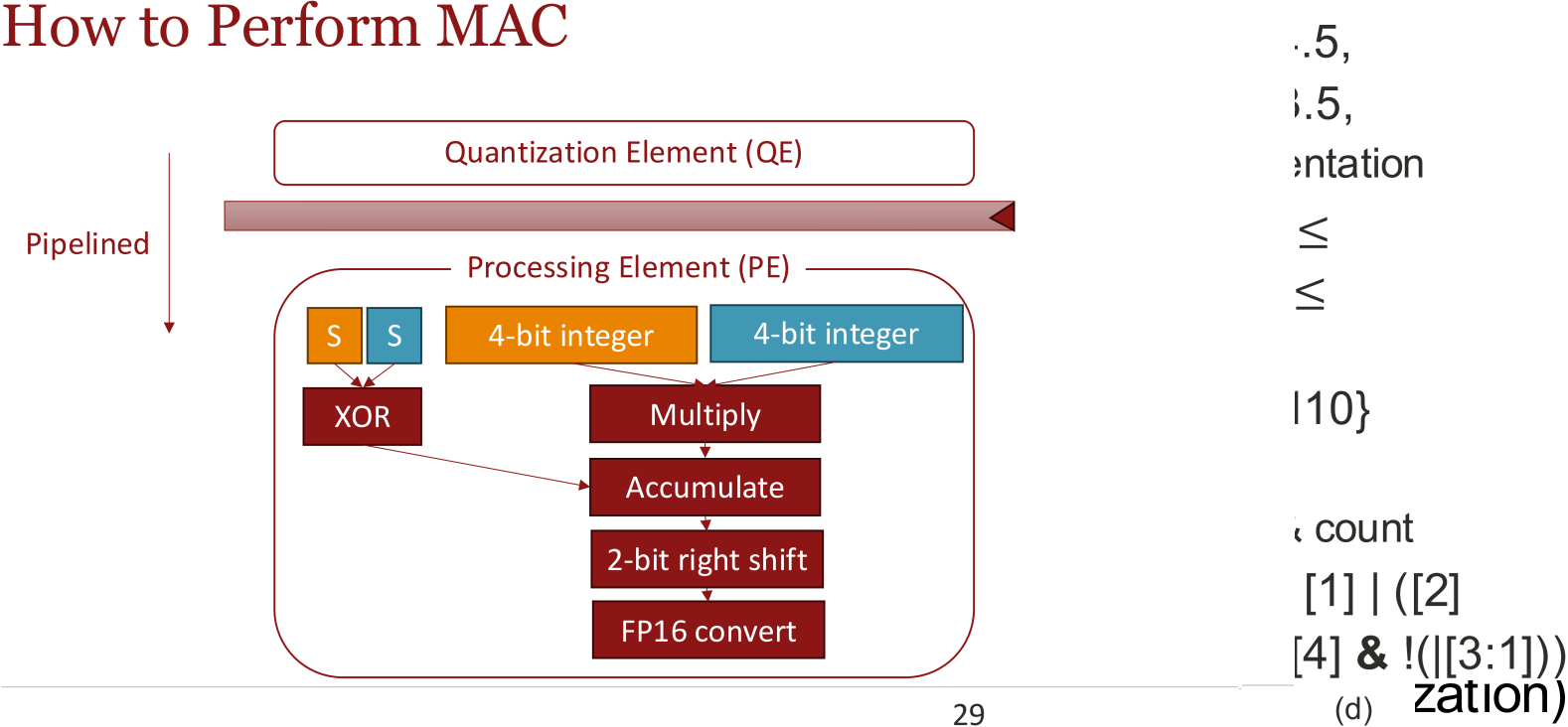
技术框架:BlockDialect包含两个主要阶段:离线格式手册构建和在线激活量化。离线阶段,构建包含多种FP4变体的DialectFP4格式手册。在线阶段,首先对激活进行初步量化,然后根据量化结果选择最佳的DialectFP4格式,最后使用选定的格式进行最终量化。这种两阶段方法允许模型在运行时动态地适应不同的数据分布。
关键创新:BlockDialect的关键创新在于块级别的混合格式量化和DialectFP4格式手册的设计。与传统的单一格式量化方法不同,BlockDialect允许每个块使用不同的量化格式,从而更好地适应数据的局部特性。DialectFP4格式手册提供了一组FP4变体,这些变体针对不同的数据分布进行了优化,使得模型能够更灵活地选择合适的量化格式。
关键设计:DialectFP4格式手册包含多种FP4变体,每种变体具有不同的缩放因子和舍入策略。在线激活量化采用两阶段方法:第一阶段使用一种通用的量化格式进行初步量化,第二阶段根据第一阶段的量化结果选择最佳的DialectFP4格式。选择最佳格式的标准可以是最小化量化误差或最大化硬件利用率。具体参数设置和损失函数未知。
🖼️ 关键图片
📊 实验亮点
BlockDialect在LLaMA3-8B模型上实现了10.78%的精度提升,在LLaMA2-7B模型上实现了7.48%的精度提升,相比于MXFP4格式,同时降低了比特使用量。即使在量化全路径矩阵乘法时,BlockDialect的精度损失也仅为5.45%(LLaMA3-8B)和2.69%(LLaMA2-7B),表明其在保持精度的同时显著提高了能源效率。
🎯 应用场景
BlockDialect适用于对计算资源和能耗有严格要求的场景,例如移动设备、边缘计算和嵌入式系统上的大型语言模型推理。通过降低内存占用和计算复杂度,BlockDialect可以使LLM在资源受限的设备上高效运行,从而扩展LLM的应用范围。该技术还有助于降低数据中心的能耗,实现更可持续的AI发展。
📄 摘要(原文)
The rapidly increasing size of large language models (LLMs) presents significant challenges in memory usage and computational costs. Quantizing both weights and activations can address these issues, with hardware-supported fine-grained scaling emerging as a promising solution to mitigate outliers. However, existing methods struggle to capture nuanced block data distributions. We propose BlockDialect, a block-wise fine-grained mixed format technique that assigns a per-block optimal number format from a formatbook for better data representation. Additionally, we introduce DialectFP4, a formatbook of FP4 variants (akin to dialects) that adapt to diverse data distributions. To leverage this efficiently, we propose a two-stage approach for online DialectFP4 activation quantization. Importantly, DialectFP4 ensures energy efficiency by selecting representable values as scaled integers compatible with low-precision integer arithmetic. BlockDialect achieves 10.78% (7.48%) accuracy gain on the LLaMA3-8B (LLaMA2-7B) model compared to MXFP4 format with lower bit usage per data, while being only 5.45% (2.69%) below full precision even when quantizing full-path matrix multiplication. Focusing on how to represent over how to scale, our work presents a promising path for energy-efficient LLM inference.