Dynamic Scaling of Unit Tests for Code Reward Modeling
作者: Zeyao Ma, Xiaokang Zhang, Jing Zhang, Jifan Yu, Sijia Luo, Jie Tang
分类: cs.CL, cs.SE
发布日期: 2025-01-02
备注: Homepage: https://code-reward-model.github.io/
💡 一句话要点
提出CodeRM-8B,通过动态调整单元测试规模提升代码奖励建模性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 单元测试 奖励建模 大型语言模型 动态缩放
📋 核心要点
- 现有代码生成方法依赖LLM生成单元测试来评估代码质量,但LLM的错误导致单元测试不可靠,降低了奖励信号质量。
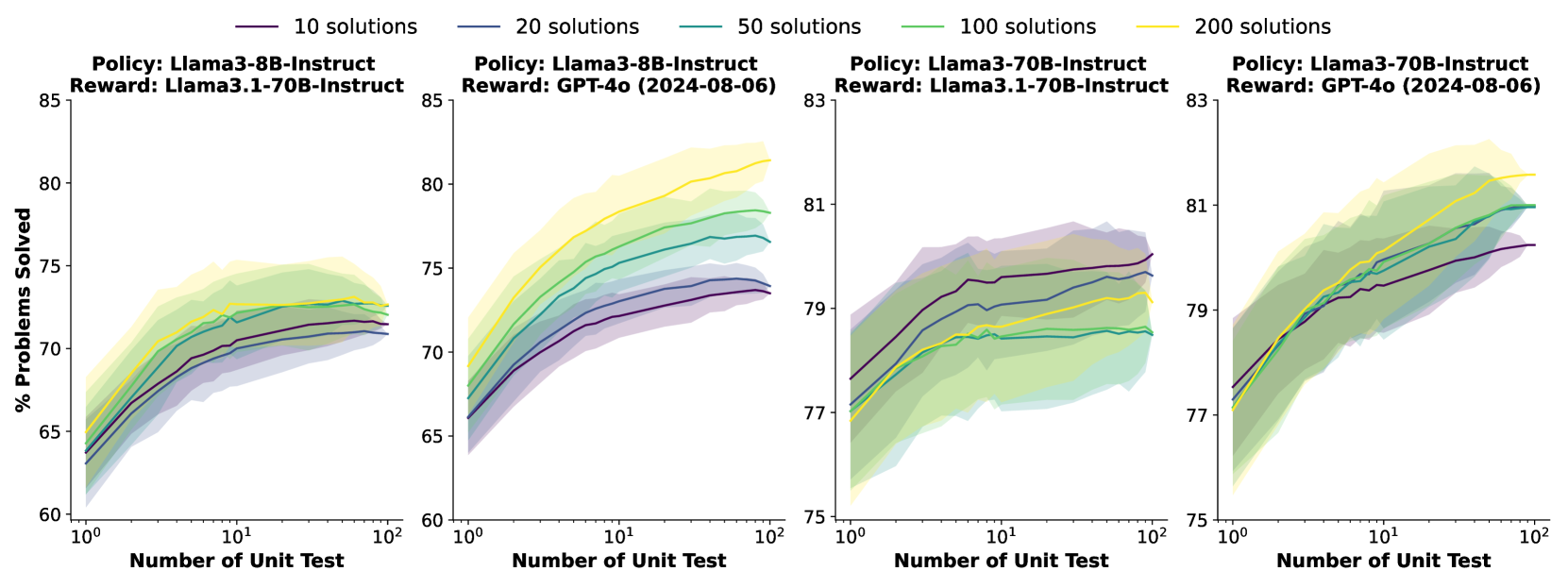
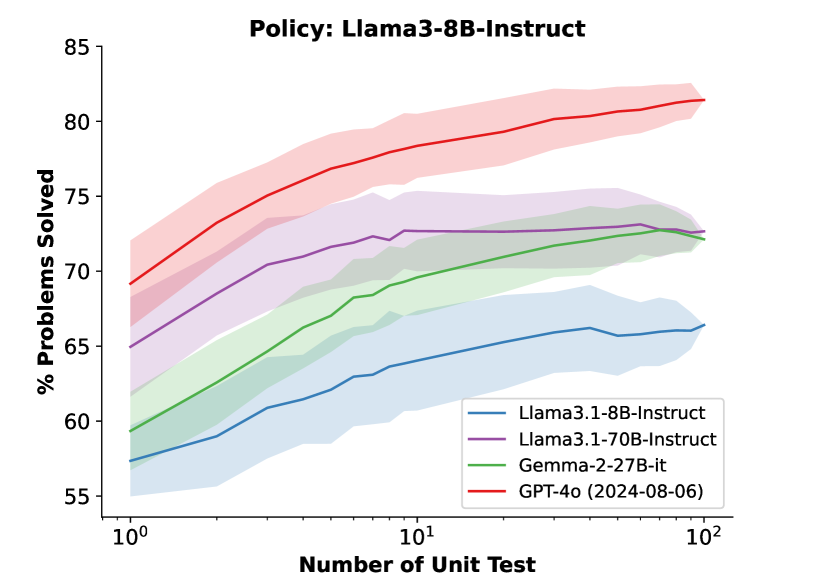
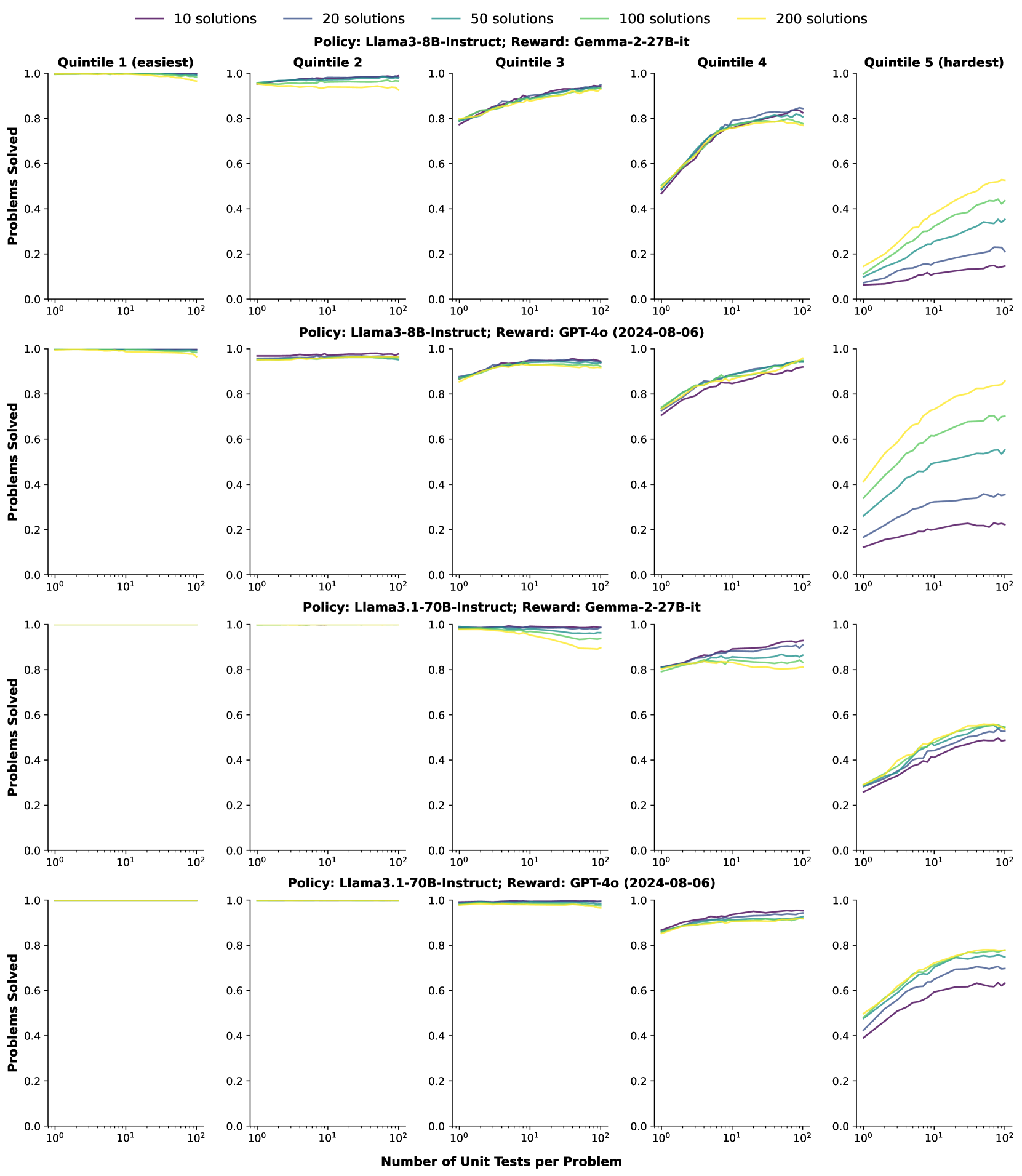
- 论文提出CodeRM-8B,通过扩展单元测试规模来提高奖励信号质量,并采用动态缩放机制根据问题难度调整测试数量。
- 实验表明,该方法在多个基准测试中显著提升了代码生成性能,例如Llama3-8B提升18.43%,GPT-4o-mini提升3.42%。
📝 摘要(中文)
当前的大型语言模型(LLMs)在代码生成等复杂推理任务中,首次尝试往往难以产生准确的响应。现有研究通过生成多个候选解决方案,并使用LLM生成的单元测试进行验证来解决这个问题。单元测试的执行结果作为奖励信号,用于识别正确的解决方案。然而,LLMs经常自信地犯错,导致这些单元测试并不可靠,从而降低了奖励信号的质量。受扩大解决方案数量可以提高LLM性能的启发,我们探索了扩大单元测试规模对提高奖励信号质量的影响。初步实验表明,单元测试的数量与奖励信号的质量呈正相关,并且在更具挑战性的问题中观察到更大的收益。基于这些发现,我们提出了CodeRM-8B,一个轻量级但有效的单元测试生成器,可以实现高效和高质量的单元测试扩展。此外,我们实现了一种动态缩放机制,可以根据问题的难度调整单元测试的数量,从而进一步提高效率。实验结果表明,我们的方法显著提高了各种模型在三个基准测试上的性能(例如,Llama3-8B提高了18.43%,GPT-4o-mini在HumanEval Plus上提高了3.42%)。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在代码生成任务中,由于LLM生成的单元测试不可靠,导致奖励信号质量下降的问题。现有方法依赖于这些有缺陷的单元测试来评估代码,从而影响了代码生成模型的性能。
核心思路:论文的核心思路是通过增加单元测试的数量来提高奖励信号的质量。作者观察到,更多的单元测试可以更全面地覆盖代码的各种情况,从而更准确地评估代码的正确性。此外,论文还提出了一种动态缩放机制,根据问题的难度自适应地调整单元测试的数量,以提高效率。
技术框架:整体框架包含以下几个主要阶段:1) 使用大型语言模型生成多个候选代码解决方案;2) 使用CodeRM-8B生成单元测试,并根据问题难度动态调整单元测试的数量;3) 执行单元测试,并将执行结果作为奖励信号;4) 使用奖励信号来选择最佳的代码解决方案。
关键创新:论文的关键创新在于提出了CodeRM-8B,一个轻量级但有效的单元测试生成器,以及动态缩放机制。CodeRM-8B能够高效地生成高质量的单元测试,而动态缩放机制则可以根据问题的难度自适应地调整单元测试的数量,从而在保证性能的同时提高效率。与现有方法相比,该方法能够更有效地利用单元测试来提高代码生成模型的性能。
关键设计:CodeRM-8B的具体实现细节未知,但可以推测其可能采用了某种prompt工程或微调技术,使其能够生成更准确、更全面的单元测试。动态缩放机制的具体实现细节也未知,但可以推测其可能使用了某种难度评估指标,例如代码的复杂度或单元测试的失败率,来动态调整单元测试的数量。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在HumanEval Plus等基准测试中显著提高了代码生成性能。例如,使用Llama3-8B模型时,性能提升了18.43%;使用GPT-4o-mini模型时,性能提升了3.42%。这些结果表明,通过动态调整单元测试规模,可以有效地提高代码奖励建模的性能。
🎯 应用场景
该研究成果可应用于各种需要代码生成的场景,例如软件开发、自动化测试、教育等。通过提高代码生成模型的性能,可以显著提高开发效率,降低开发成本,并促进软件质量的提升。未来,该方法还可以扩展到其他类型的生成任务,例如文本生成、图像生成等。
📄 摘要(原文)
Current large language models (LLMs) often struggle to produce accurate responses on the first attempt for complex reasoning tasks like code generation. Prior research tackles this challenge by generating multiple candidate solutions and validating them with LLM-generated unit tests. The execution results of unit tests serve as reward signals to identify correct solutions. As LLMs always confidently make mistakes, these unit tests are not reliable, thereby diminishing the quality of reward signals. Motivated by the observation that scaling the number of solutions improves LLM performance, we explore the impact of scaling unit tests to enhance reward signal quality. Our pioneer experiment reveals a positive correlation between the number of unit tests and reward signal quality, with greater benefits observed in more challenging problems. Based on these insights, we propose CodeRM-8B, a lightweight yet effective unit test generator that enables efficient and high-quality unit test scaling. Additionally, we implement a dynamic scaling mechanism that adapts the number of unit tests based on problem difficulty, further improving efficiency. Experimental results show that our approach significantly improves performance across various models on three benchmarks (e.g., with gains of 18.43% for Llama3-8B and 3.42% for GPT-4o-mini on HumanEval Plus).