FED: Fast and Efficient Dataset Deduplication Framework with GPU Acceleration
作者: Youngjun Son, Chaewon Kim, Jaejin Lee
分类: cs.CL
发布日期: 2025-01-02 (更新: 2025-03-12)
备注: 13 pages, 4 figures
🔗 代码/项目: GITHUB
💡 一句话要点
FED:基于GPU加速的高效数据集去重框架,提升LLM训练效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据集去重 MinHash LSH GPU加速 大型语言模型 数据清洗
📋 核心要点
- 现有基于GPU的MinHash LSH去重方法效率仍有提升空间,无法充分利用GPU集群的计算能力。
- FED框架通过优化MinHash LSH算法,并结合高效的非密码学哈希函数,实现了GPU集群上的加速去重。
- 实验表明,FED在去重速度上显著优于CPU和现有GPU方法,同时保持了较高的去重质量。
📝 摘要(中文)
数据集去重对于提高数据质量至关重要,最终能够提升大型语言模型的训练性能和效率。MinHash LSH算法是常用的数据去重方法。最近,NVIDIA推出了一种基于GPU的MinHash LSH去重方法,但其效率仍有优化空间。本文提出了一个GPU加速的去重框架FED,该框架针对GPU集群优化了MinHash LSH,并利用了计算高效、部分可重用的非密码学哈希函数。在具有四个GPU的节点上处理3000万个文档时,FED的性能显著优于SlimPajama中基于CPU的去重工具(使用64个逻辑CPU核心),高达107.2倍,并且优于NVIDIA NeMo Curator中基于GPU的工具,高达6.3倍。值得注意的是,我们的方法极大地加速了之前耗时的MinHash签名生成阶段,与CPU基线相比,实现了高达260倍的加速。尽管效率有所提高,但FED保持了较高的去重质量,与标准MinHash算法识别的重复文档集相比,重复文档集的Jaccard相似度超过0.96。在大规模实验中,在四节点、16-GPU环境中,仅需6小时即可完成1.2万亿token的去重。相关代码已在GitHub上公开。
🔬 方法详解
问题定义:论文旨在解决大规模数据集去重效率低下的问题,尤其是在大型语言模型训练的背景下。现有的CPU方法速度慢,而现有的GPU方法未能充分利用GPU的并行计算能力,导致去重过程耗时较长。
核心思路:论文的核心思路是针对GPU集群优化MinHash LSH算法,并采用计算高效的非密码学哈希函数。通过充分利用GPU的并行处理能力,加速MinHash签名生成和相似度计算过程,从而提高整体去重效率。
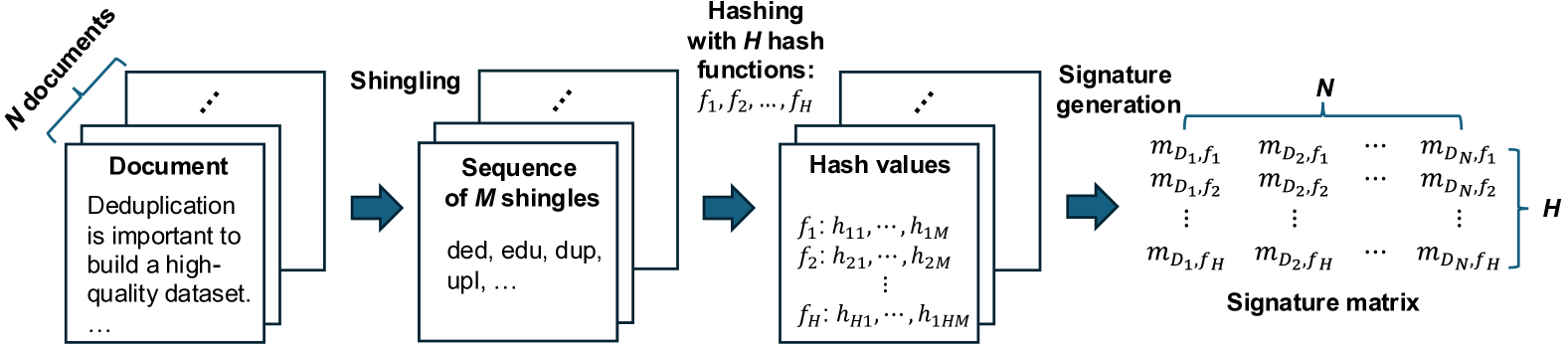
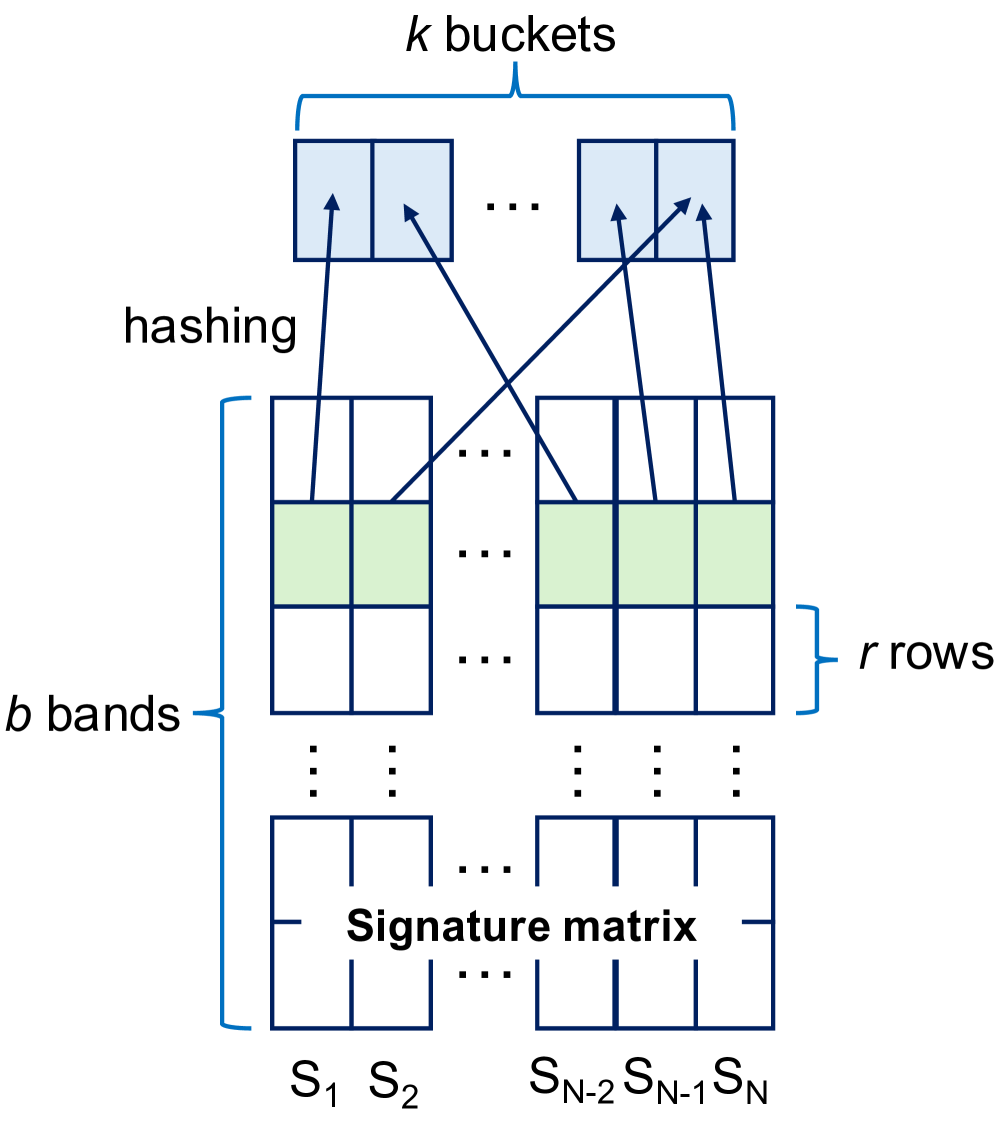
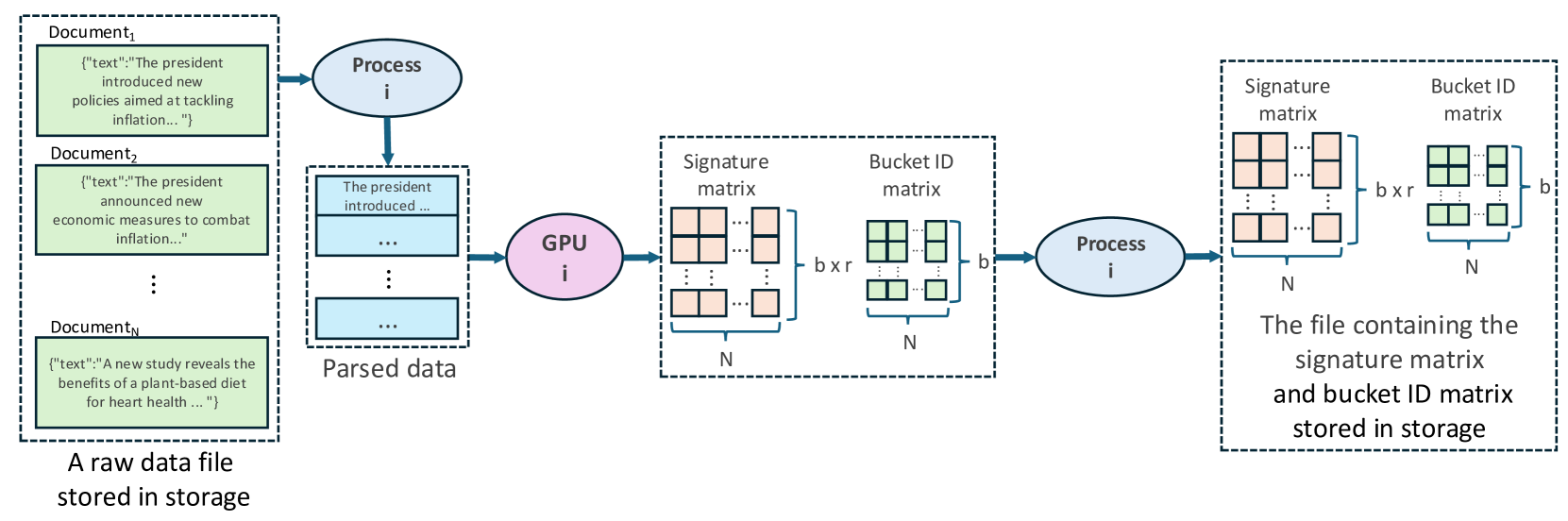
技术框架:FED框架主要包含以下几个阶段:1) 数据预处理:对输入文档进行清洗和格式化。2) MinHash签名生成:使用优化的哈希函数在GPU上并行生成MinHash签名。3) LSH索引构建:构建LSH索引,用于快速查找相似的文档。4) 相似度计算:计算候选文档对之间的相似度,并识别重复文档。5) 结果输出:输出去重后的数据集。
关键创新:FED的关键创新在于:1) 针对GPU集群优化了MinHash LSH算法,使其能够充分利用GPU的并行计算能力。2) 采用了计算高效、部分可重用的非密码学哈希函数,显著加速了MinHash签名生成过程。3) 提出了一个完整的GPU加速去重框架,能够高效地处理大规模数据集。
关键设计:论文中关键的设计包括:1) 哈希函数的选择:选择了计算速度快、冲突率低的非密码学哈希函数,例如MurmurHash。2) LSH参数的设置:根据数据集的特点,调整LSH的桶的数量和哈希函数的数量,以达到最佳的去重效果。3) GPU内存管理:优化了GPU内存的使用,避免了内存溢出和数据传输瓶颈。
🖼️ 关键图片
📊 实验亮点
FED框架在处理3000万个文档时,相比于SlimPajama(CPU,64核)实现了高达107.2倍的加速,相比于NVIDIA NeMo Curator(GPU)实现了高达6.3倍的加速。MinHash签名生成阶段的加速比高达260倍。在16-GPU环境下,仅需6小时即可完成1.2万亿token的去重。同时,FED保持了较高的去重质量,Jaccard相似度超过0.96。
🎯 应用场景
该研究成果可广泛应用于大型语言模型训练、搜索引擎优化、数据清洗等领域。通过高效的数据集去重,可以提高模型训练的效率和质量,降低存储成本,并提升数据分析的准确性。未来,该技术有望应用于更多需要处理大规模数据集的场景,例如生物信息学、金融分析等。
📄 摘要(原文)
Dataset deduplication plays a crucial role in enhancing data quality, ultimately improving the training performance and efficiency of large language models. A commonly used method for data deduplication is the MinHash LSH algorithm. Recently, NVIDIA introduced a GPU-based MinHash LSH deduplication method, but it remains suboptimal, leaving room for further improvement in processing efficiency. This paper proposes a GPU-accelerated deduplication framework, FED, that optimizes MinHash LSH for GPU clusters and leverages computationally efficient, partially reusable non-cryptographic hash functions. FED significantly outperforms the CPU-based deduplication tool in SlimPajama (using 64 logical CPU cores) by up to 107.2 times and the GPU-based tool in NVIDIA NeMo Curator by up to 6.3 times when processing 30 million documents on a node with four GPUs. Notably, our method dramatically accelerates the previously time-consuming MinHash signature generation phase, achieving speed-ups of up to 260 compared to the CPU baseline. Despite these gains in efficiency, FED maintains high deduplication quality, with the duplicate document sets reaching a Jaccard similarity of over 0.96 compared to those identified by the standard MinHash algorithm. In large-scale experiments, the deduplication of 1.2 trillion tokens is completed in just 6 hours in a four-node, 16-GPU environment. The related code is publicly available on GitHub (\href{https://github.com/mcrl/FED}{https://github.com/mcrl/FED}).