Advancing Singlish Understanding: Bridging the Gap with Datasets and Multimodal Models
作者: Bin Wang, Xunlong Zou, Shuo Sun, Wenyu Zhang, Yingxu He, Zhuohan Liu, Chengwei Wei, Nancy F. Chen, AiTi Aw
分类: cs.CL, cs.SD, eess.AS
发布日期: 2025-01-02 (更新: 2025-01-11)
备注: Open-Source: https://github.com/AudioLLMs/Singlish
💡 一句话要点
构建Singlish理解桥梁:发布数据集与多模态模型SingAudioLLM
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Singlish理解 多模态学习 语音识别 口语问答 多任务学习 大型语言模型 克里奥尔语
📋 核心要点
- 口语Singlish语料的匮乏限制了对其语言结构和应用的深入研究,阻碍了相关技术的发展。
- 论文通过构建并标注大规模口语Singlish语料库MNSC,并提出多任务多模态模型SingAudioLLM来解决上述问题。
- 实验结果表明,SingAudioLLM在多个Singlish理解任务上取得了SOTA性能,相比其他模型提升显著。
📝 摘要(中文)
Singlish是一种源于英语的克里奥尔语,是多语言和多元文化背景下语言研究的关键。然而,其口语形式仍未得到充分探索,限制了对其语言结构和应用的深入了解。为了解决这个问题,我们标准化并标注了最大的口语Singlish语料库,推出了多任务国家语音语料库(MNSC)。这些数据集支持多种任务,包括自动语音识别(ASR)、口语问答(SQA)、口语对话摘要(SDS)和副语言问答(PQA)。我们发布了标准化的分割和人工验证的测试集,以促进进一步的研究。此外,我们提出了SingAudioLLM,一个利用多模态大型语言模型同时处理这些任务的多任务多模态模型。实验表明,我们的模型能够适应Singlish语境,实现了最先进的性能,并且与其他AudioLLM和级联解决方案相比,性能提高了10-30%。
🔬 方法详解
问题定义:论文旨在解决口语Singlish理解的难题。现有方法缺乏足够的数据支持,并且难以有效利用多模态信息进行综合理解,导致在自动语音识别、口语问答等任务上表现不佳。
核心思路:论文的核心思路是构建大规模的口语Singlish数据集,并利用多模态大型语言模型(MLLM)的强大能力,实现对Singlish语音、语义和上下文信息的综合理解。通过多任务学习,提升模型在不同任务上的泛化能力。
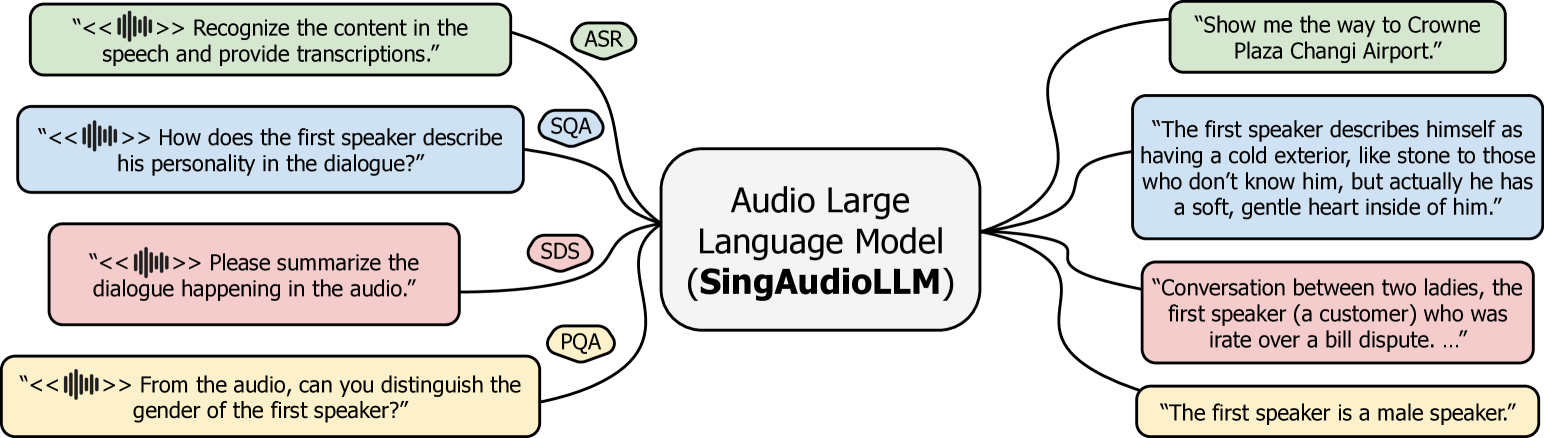
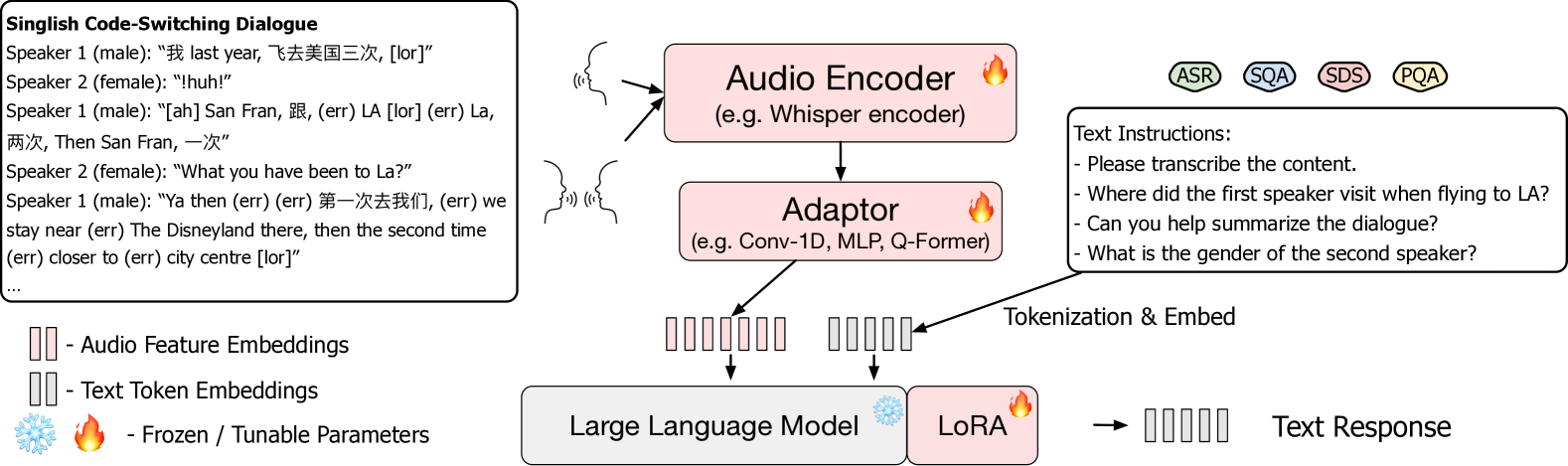
技术框架:整体框架包含两个主要部分:一是MNSC数据集的构建,包括数据收集、标准化和人工标注;二是SingAudioLLM模型的构建,该模型基于MLLM,能够同时处理自动语音识别(ASR)、口语问答(SQA)、口语对话摘要(SDS)和副语言问答(PQA)等任务。模型接收语音输入,并输出相应的文本或答案。
关键创新:论文的关键创新在于:1)构建了目前最大的口语Singlish数据集MNSC,为相关研究提供了数据基础;2)提出了SingAudioLLM,一个专门针对Singlish理解的多任务多模态模型,能够有效利用语音和文本信息;3)通过多任务学习,提升了模型在不同Singlish理解任务上的性能。
关键设计:MNSC数据集包含多种类型的标注,支持不同的任务。SingAudioLLM模型的具体结构未知,但推测其利用了预训练的MLLM作为 backbone,并通过微调或添加特定模块来适应Singlish的特点。损失函数可能采用了多任务学习常用的加权损失函数,以平衡不同任务之间的学习。
🖼️ 关键图片
📊 实验亮点
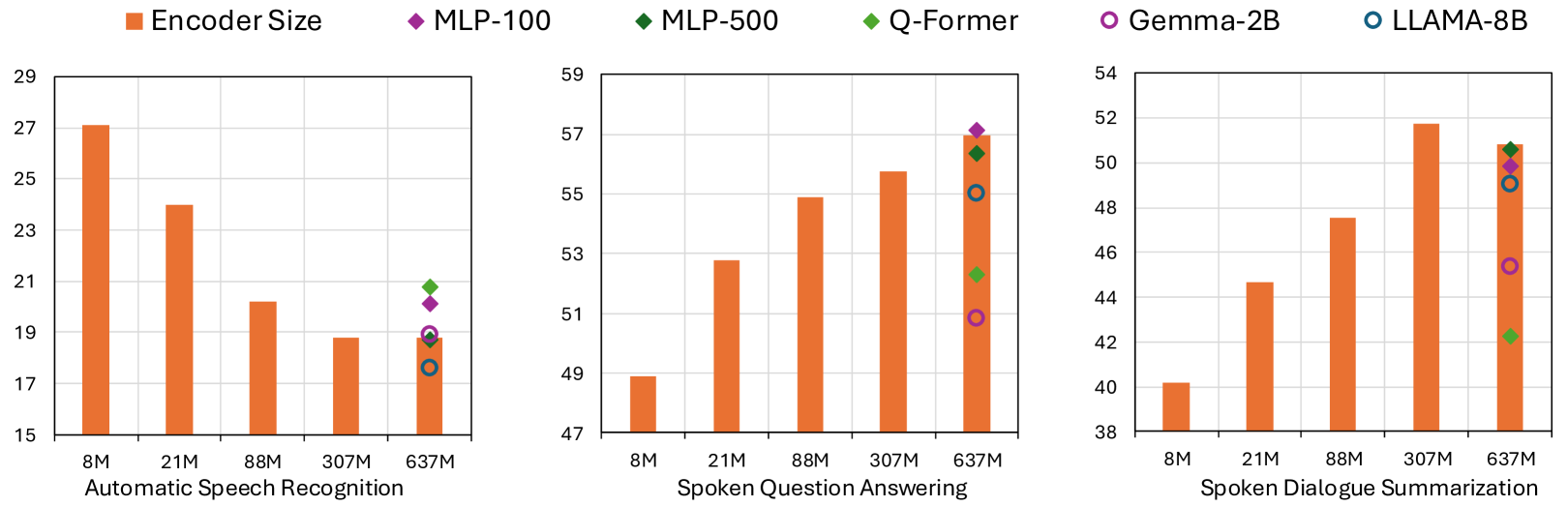
实验结果表明,SingAudioLLM在多个Singlish理解任务上取得了state-of-the-art的性能,相比于其他AudioLLM和级联解决方案,性能提升了10-30%。这表明该模型能够有效适应Singlish的特点,并充分利用多模态信息进行理解。
🎯 应用场景
该研究成果可应用于智能语音助手、口语翻译、教育等领域。例如,可以开发能够理解Singlish的智能客服,或者用于Singlish语言教学。未来,该研究还可以促进对其他克里奥尔语的研究和应用,推动多语言技术的发展。
📄 摘要(原文)
Singlish, a Creole language rooted in English, is a key focus in linguistic research within multilingual and multicultural contexts. However, its spoken form remains underexplored, limiting insights into its linguistic structure and applications. To address this gap, we standardize and annotate the largest spoken Singlish corpus, introducing the Multitask National Speech Corpus (MNSC). These datasets support diverse tasks, including Automatic Speech Recognition (ASR), Spoken Question Answering (SQA), Spoken Dialogue Summarization (SDS), and Paralinguistic Question Answering (PQA). We release standardized splits and a human-verified test set to facilitate further research. Additionally, we propose SingAudioLLM, a multi-task multimodal model leveraging multimodal large language models to handle these tasks concurrently. Experiments reveal our models adaptability to Singlish context, achieving state-of-the-art performance and outperforming prior models by 10-30% in comparison with other AudioLLMs and cascaded solutions.