KaLM-Embedding: Superior Training Data Brings A Stronger Embedding Model
作者: Xinshuo Hu, Zifei Shan, Xinping Zhao, Zetian Sun, Zhenyu Liu, Dongfang Li, Shaolin Ye, Xinyuan Wei, Qian Chen, Baotian Hu, Haofen Wang, Jun Yu, Min Zhang
分类: cs.CL
发布日期: 2025-01-02 (更新: 2025-01-15)
备注: Technical Report. 23 pages, 6 figures, 10 tables
💡 一句话要点
KaLM-Embedding:通过高质量训练数据提升通用多语言嵌入模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 嵌入模型 多语言模型 训练数据质量 检索增强生成 对比学习
📋 核心要点
- 现有通用嵌入模型训练数据质量不足,限制了模型性能。
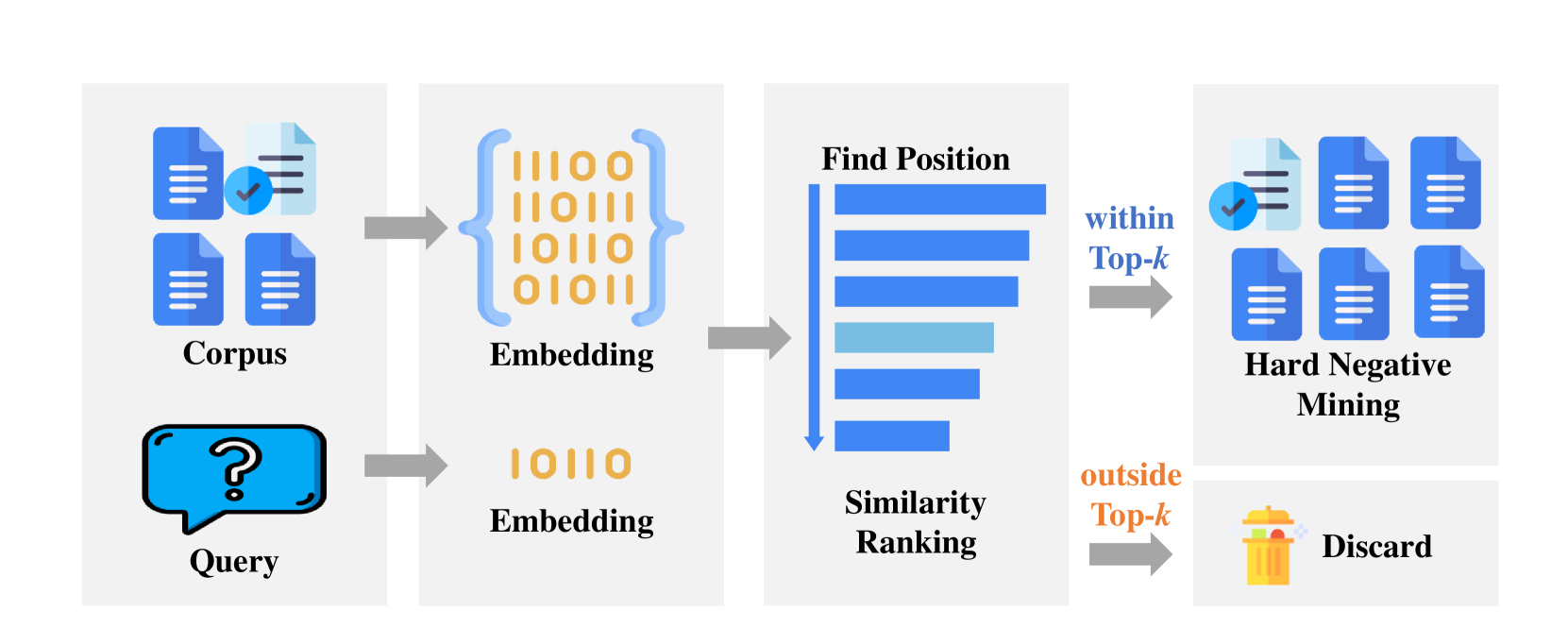
- KaLM-Embedding利用高质量训练数据,结合角色扮演合成数据、排序一致性过滤和半同质任务批采样。
- 实验表明,KaLM-Embedding在MTEB基准测试中优于同等规模的模型,成为新的多语言嵌入模型标杆。
📝 摘要(中文)
随着检索增强生成技术在大语言模型中的普及,嵌入模型变得越来越重要。尽管通用嵌入模型数量不断增长,但以往的研究往往忽视了训练数据质量的关键作用。本文提出了KaLM-Embedding,一种通用的多语言嵌入模型,它利用大量更干净、更多样化和领域特定的训练数据进行训练。我们的模型采用了已被证明可以提高性能的关键技术:(1) 基于角色的合成数据,用于创建从LLM中提炼出的多样化示例;(2) 排序一致性过滤,用于删除信息量较少的样本;(3) 半同质任务批采样,以提高训练效率。与传统的BERT类架构不同,我们采用Qwen2-0.5B作为预训练模型,从而促进了自回归语言模型对通用嵌入任务的适应。在多种语言的MTEB基准上的广泛评估表明,我们的模型优于其他同等规模的模型,为参数小于1B的多语言嵌入模型树立了新标准。
🔬 方法详解
问题定义:论文旨在解决通用多语言嵌入模型的性能瓶颈问题。现有方法通常忽略训练数据质量,导致模型在跨语言和特定领域的检索任务中表现不佳。此外,现有模型架构可能限制了自回归语言模型在嵌入任务中的应用潜力。
核心思路:论文的核心思路是通过构建高质量的训练数据集来提升嵌入模型的性能。具体而言,通过合成多样化的训练样本、过滤低质量样本以及优化训练策略,从而使模型能够学习到更具区分性和泛化能力的嵌入表示。同时,探索使用自回归语言模型作为嵌入模型的基础架构。
技术框架:KaLM-Embedding的训练框架主要包括以下几个阶段:1) 数据合成:利用大型语言模型生成基于角色的合成数据,以增加训练数据的多样性。2) 数据过滤:采用排序一致性过滤方法,去除信息量较少的训练样本。3) 模型训练:使用半同质任务批采样策略,优化训练过程,提高训练效率。4) 模型评估:在MTEB基准测试上进行多语言评估,验证模型性能。
关键创新:论文的关键创新在于以下几个方面:1) 提出了基于角色的合成数据生成方法,有效提升了训练数据的多样性。2) 引入了排序一致性过滤方法,能够自动识别并去除低质量的训练样本。3) 探索了使用Qwen2-0.5B等自回归语言模型作为嵌入模型的基础架构,为后续研究提供了新的思路。
关键设计:在数据合成方面,设计了不同的角色和场景,以生成多样化的对话和文本。在排序一致性过滤方面,采用了基于余弦相似度的排序一致性度量。在模型训练方面,使用了AdamW优化器,并设置了合适的学习率和权重衰减系数。在半同质任务批采样方面,将相似的任务组合成一个批次,以提高训练效率。
🖼️ 关键图片


📊 实验亮点
KaLM-Embedding在MTEB基准测试中取得了显著的性能提升,超越了同等规模的其他模型。例如,在某些语言和任务上,KaLM-Embedding的性能提升超过了5%。这表明高质量的训练数据和有效的训练策略能够显著提升嵌入模型的性能。
🎯 应用场景
KaLM-Embedding可广泛应用于信息检索、问答系统、文本聚类、语义搜索等领域。高质量的嵌入表示能够提升检索系统的准确性和召回率,改善用户体验。该研究成果有助于推动跨语言信息处理和自然语言理解技术的发展,具有重要的实际应用价值。
📄 摘要(原文)
As retrieval-augmented generation prevails in large language models, embedding models are becoming increasingly crucial. Despite the growing number of general embedding models, prior work often overlooks the critical role of training data quality. In this work, we introduce KaLM-Embedding, a general multilingual embedding model that leverages a large quantity of cleaner, more diverse, and domain-specific training data. Our model has been trained with key techniques proven to enhance performance: (1) persona-based synthetic data to create diversified examples distilled from LLMs, (2) ranking consistency filtering to remove less informative samples, and (3) semi-homogeneous task batch sampling to improve training efficacy. Departing from traditional BERT-like architectures, we adopt Qwen2-0.5B as the pre-trained model, facilitating the adaptation of auto-regressive language models for general embedding tasks. Extensive evaluations of the MTEB benchmark across multiple languages show that our model outperforms others of comparable size, setting a new standard for multilingual embedding models with <1B parameters.