MDSF: Context-Aware Multi-Dimensional Data Storytelling Framework based on Large language Model
作者: Chengze Zhang, Changshan Li, Shiyang Gao
分类: cs.CL, cs.AI
发布日期: 2025-01-02
💡 一句话要点
MDSF:基于大语言模型的上下文感知多维数据故事讲述框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据故事讲述 大型语言模型 上下文感知 自动洞察生成 多维数据分析
📋 核心要点
- 现有自动数据分析系统在利用大语言模型进行数据洞察和故事讲述方面存在挑战。
- MDSF框架通过结合预处理、增强分析和评分机制,实现自动洞察生成和上下文感知的故事讲述。
- 实验结果表明,MDSF在洞察排名、描述质量和叙事连贯性方面优于现有方法,提升用户满意度。
📝 摘要(中文)
数据爆炸式增长和大数据技术的进步对更高效、自动化的数据分析和故事讲述方法提出了需求。然而,自动数据分析系统在利用大型语言模型(LLMs)进行数据洞察发现、增强分析和数据故事讲述方面仍然面临挑战。本文提出了一种基于大型语言模型的多维数据故事讲述框架(MDSF),用于自动洞察生成和上下文感知的故事讲述。该框架结合了先进的预处理技术、增强分析算法和独特的评分机制,以识别和优先排序可操作的洞察。通过使用微调的LLM,增强了上下文理解,并以最少的人工干预生成叙述。该架构还包括一个基于代理的机制,用于实时故事讲述的持续控制。关键发现表明,在洞察排名准确性、描述质量和叙事连贯性方面,MDSF优于各种数据集上的现有方法。实验评估证明了MDSF自动化复杂分析任务、减少解释偏差和提高用户满意度的能力。用户研究进一步强调了其在增强内容结构、结论提取和细节丰富性方面的实际效用。
🔬 方法详解
问题定义:现有方法在利用大型语言模型进行数据洞察发现和故事讲述时,无法充分理解上下文信息,导致生成的洞察不够准确,叙述缺乏连贯性,需要大量人工干预。因此,需要一种能够自动生成高质量数据故事,并减少人工干预的框架。
核心思路:MDSF的核心思路是利用大型语言模型(LLMs)的强大语言理解和生成能力,结合先进的预处理技术和增强分析算法,实现上下文感知的多维数据故事讲述。通过独特的评分机制,对洞察进行排序和优先级划分,确保生成的故事具有更高的准确性和可操作性。
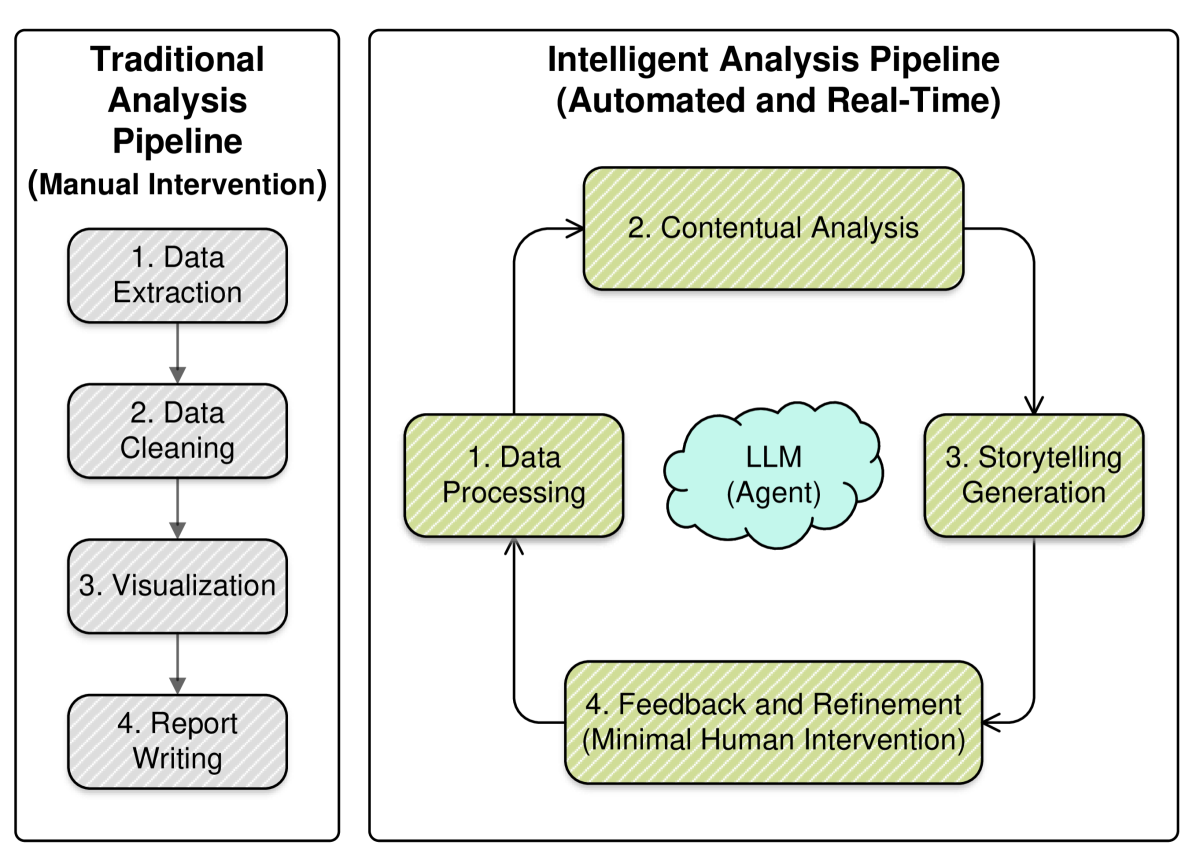
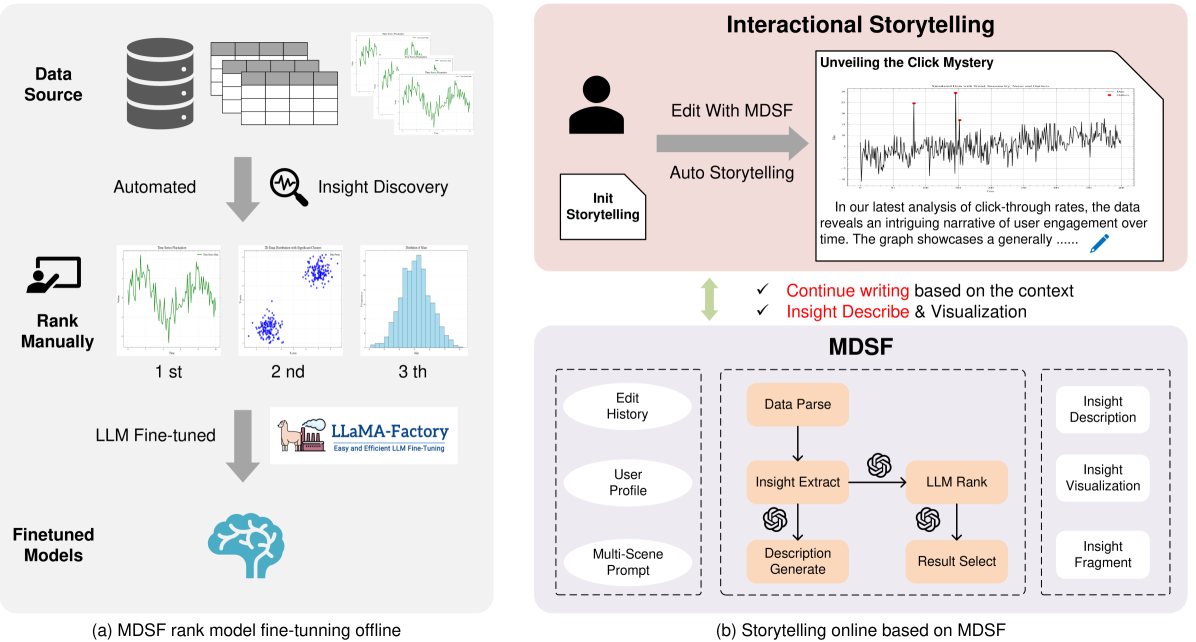
技术框架:MDSF框架包含以下主要模块:1) 数据预处理模块,用于清洗和转换数据;2) 增强分析模块,利用算法挖掘数据中的潜在洞察;3) 洞察评分模块,根据洞察的重要性、相关性和可操作性进行评分;4) LLM驱动的故事生成模块,基于评分后的洞察生成叙述;5) 基于代理的实时故事讲述控制模块,用于控制故事的持续生成。
关键创新:MDSF的关键创新在于其上下文感知的洞察生成和故事讲述能力。通过微调LLM,使其能够更好地理解数据上下文,并生成更准确、连贯的故事。此外,该框架还引入了独特的评分机制,用于对洞察进行排序和优先级划分,从而确保生成的故事具有更高的质量。
关键设计:MDSF的关键设计包括:1) 使用微调的LLM,以增强上下文理解能力;2) 设计独特的评分机制,用于对洞察进行排序和优先级划分,评分标准包括重要性、相关性和可操作性;3) 采用基于代理的机制,用于实时控制故事的持续生成,确保故事的连贯性和完整性。
🖼️ 关键图片
📊 实验亮点
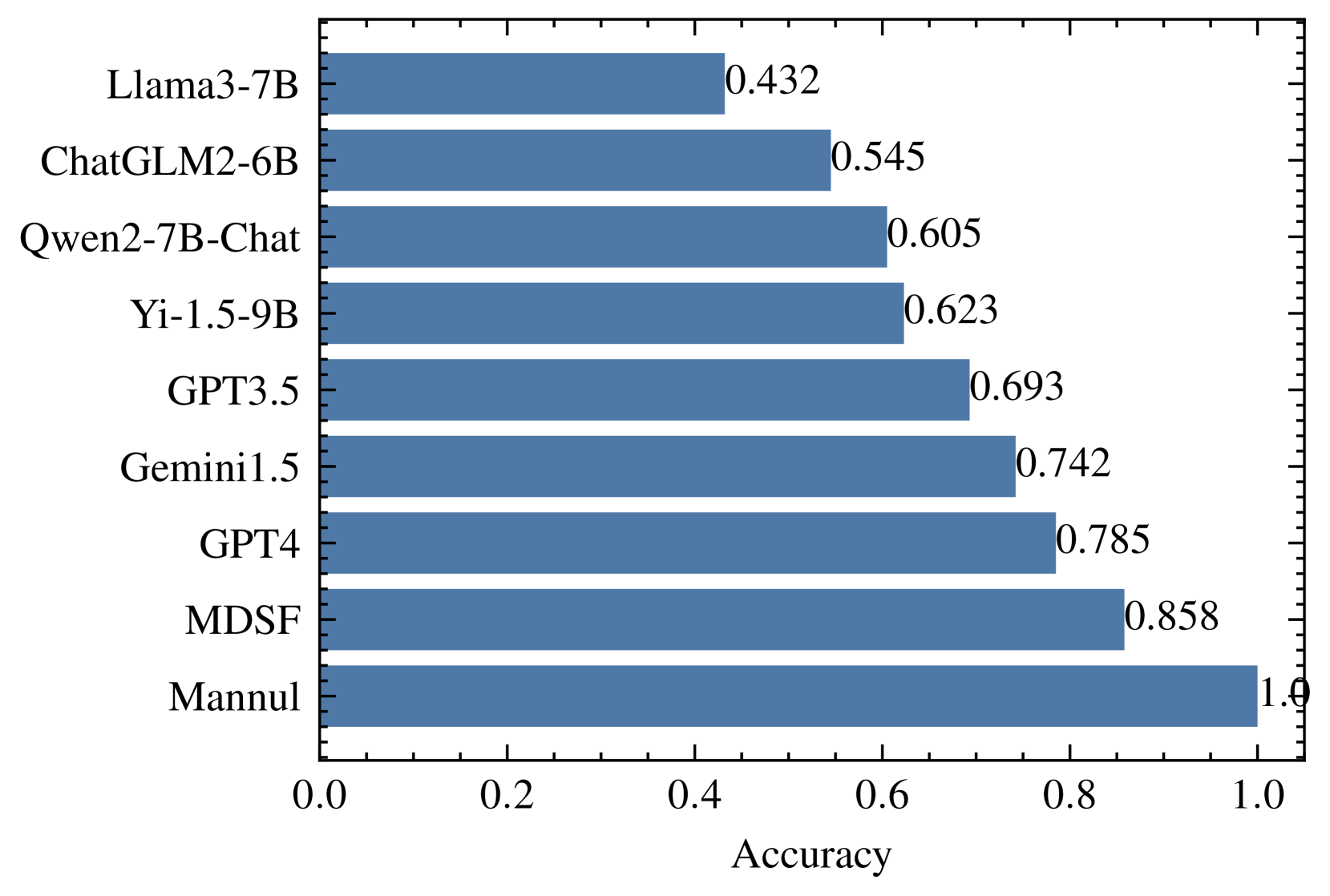
实验结果表明,MDSF在洞察排名准确性、描述质量和叙事连贯性方面优于现有方法。具体来说,MDSF在多个数据集上实现了更高的洞察排名准确率,生成的叙述更具描述性,且故事的连贯性更强。用户研究也表明,MDSF能够显著提高用户满意度,增强内容结构,并帮助用户更好地提取结论和理解细节。
🎯 应用场景
MDSF框架可应用于商业智能、金融分析、市场营销等领域,帮助用户快速理解复杂数据,发现潜在的商业机会和风险。该框架能够自动化数据分析和故事讲述过程,减少人工干预,提高工作效率,并为决策者提供更准确、更全面的信息支持。未来,MDSF有望成为企业数据驱动决策的重要工具。
📄 摘要(原文)
The exponential growth of data and advancements in big data technologies have created a demand for more efficient and automated approaches to data analysis and storytelling. However, automated data analysis systems still face challenges in leveraging large language models (LLMs) for data insight discovery, augmented analysis, and data storytelling. This paper introduces the Multidimensional Data Storytelling Framework (MDSF) based on large language models for automated insight generation and context-aware storytelling. The framework incorporates advanced preprocessing techniques, augmented analysis algorithms, and a unique scoring mechanism to identify and prioritize actionable insights. The use of fine-tuned LLMs enhances contextual understanding and generates narratives with minimal manual intervention. The architecture also includes an agent-based mechanism for real-time storytelling continuation control. Key findings reveal that MDSF outperforms existing methods across various datasets in terms of insight ranking accuracy, descriptive quality, and narrative coherence. The experimental evaluation demonstrates MDSF's ability to automate complex analytical tasks, reduce interpretive biases, and improve user satisfaction. User studies further underscore its practical utility in enhancing content structure, conclusion extraction, and richness of detail.