Labels Generated by Large Language Models Help Measure People's Empathy in Vitro
作者: Md Rakibul Hasan, Yue Yao, Md Zakir Hossain, Aneesh Krishna, Imre Rudas, Shafin Rahman, Tom Gedeon
分类: cs.CL, cs.LG
发布日期: 2025-01-01 (更新: 2025-07-16)
备注: This work has been submitted to the IEEE for possible publication
🔗 代码/项目: GITHUB
💡 一句话要点
利用大语言模型生成标签,提升体外实验中人类共情能力评估的准确性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 共情计算 噪声标签校正 数据增强 预训练语言模型 心理学 体外实验
📋 核心要点
- 现有的共情计算模型依赖于众包数据,但这些数据常常包含噪声标签,影响模型性能。
- 本文提出利用大语言模型生成高质量标签,通过噪声标签校正和数据增强两种策略,提升模型训练效果。
- 实验表明,使用LLM生成的标签训练RoBERTa模型,在NewsEmp基准测试中取得了显著的性能提升,达到SOTA。
📝 摘要(中文)
本文探索了大语言模型(LLM)在体外(in-vitro)应用中的潜力,即利用LLM生成的标签来改进主流模型的监督训练。与广泛研究的直接解决任务的prompt工程(in vivo)不同,本文侧重于LLM在共情计算中的应用,通过LLM生成的标签来提升模型的性能。共情计算是一项新兴任务,旨在从文本叙述等输入中预测基于心理学的问卷结果。由于众包数据集通常存在噪声标签,本文提出了两种策略:噪声标签校正和训练数据增强。实验结果表明,使用基于心理学且具有尺度意识的prompt生成的LLM标签替换或补充众包标签,可以显著提高准确性。使用噪声降低的标签训练的RoBERTa预训练语言模型在NewsEmp基准测试中取得了0.648的Pearson相关系数,达到了最先进水平。此外,本文还分析了评估指标的选择和人口统计学偏差,旨在指导未来更公平的共情计算模型的发展。代码和LLM生成的标签已公开。
🔬 方法详解
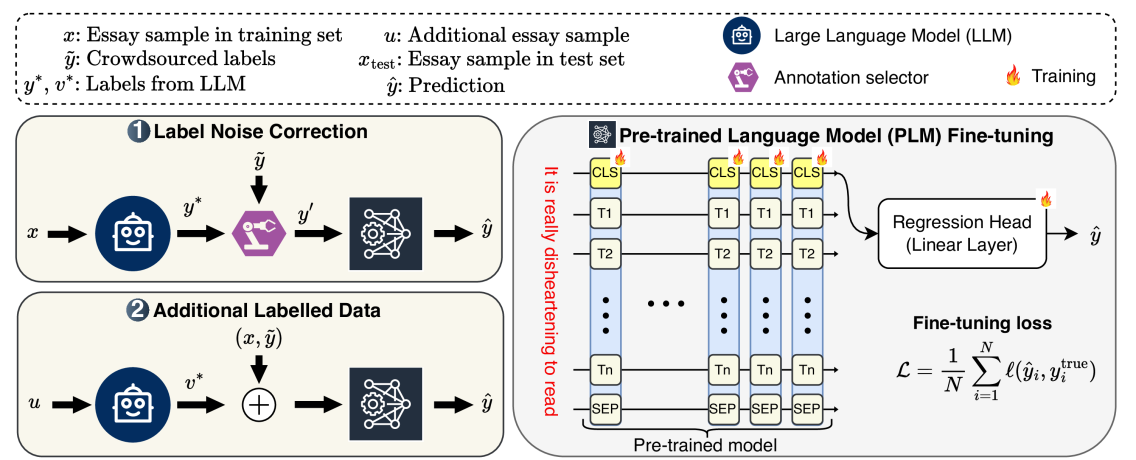
问题定义:论文旨在解决共情计算中,由于众包数据集标签噪声过大,导致模型训练效果不佳的问题。现有方法依赖人工标注,成本高昂且难以保证标签质量,特别是对于主观性较强的共情能力评估任务。
核心思路:论文的核心思路是利用大语言模型(LLM)的强大文本理解和生成能力,生成更准确、更一致的标签,替代或补充原有的噪声标签。通过精心设计的prompt,引导LLM模拟心理学专家的判断,从而获得高质量的标签。
技术框架:整体框架包含以下几个主要阶段:1) 数据准备:使用现有的共情计算数据集,包含文本叙述和对应的共情能力评估标签。2) Prompt设计:设计基于心理学理论的prompt,引导LLM生成标签。prompt需要考虑共情能力的尺度,例如使用Likert量表。3) 标签生成:使用LLM(例如GPT-3)根据prompt生成新的标签。4) 标签校正/数据增强:使用LLM生成的标签替换或补充原始标签,构建新的训练数据集。5) 模型训练:使用新的训练数据集训练预训练语言模型(例如RoBERTa)。6) 模型评估:在标准基准测试集上评估模型的性能。
关键创新:最重要的技术创新点在于将LLM应用于标签生成,并将其作为一种体外(in-vitro)方法,用于改善现有模型的训练。与直接使用LLM解决任务不同,本文利用LLM生成高质量的训练数据,从而提升主流模型的性能。这种方法可以有效降低对大量人工标注数据的依赖。
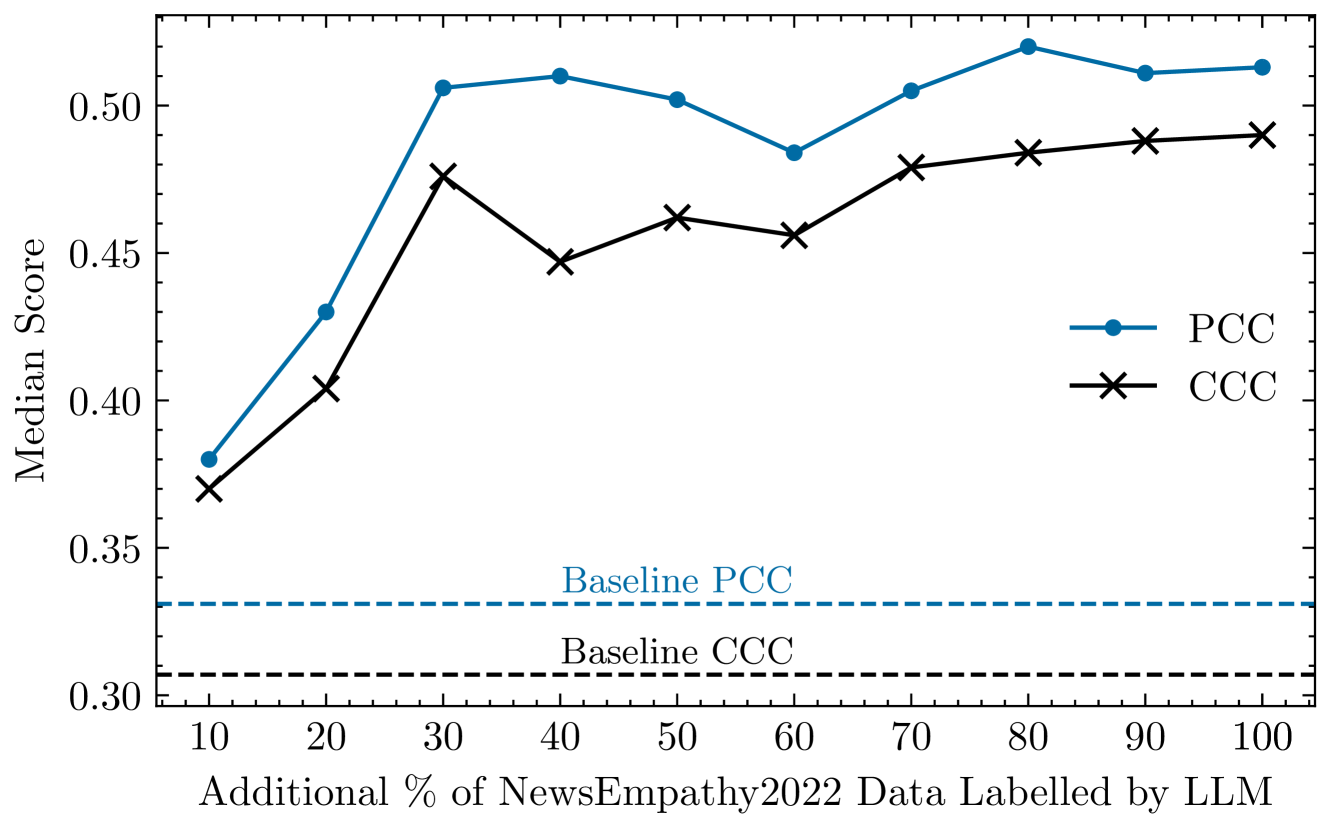
关键设计:关键设计包括:1) 基于心理学理论的prompt设计,确保LLM生成的标签具有心理学意义。2) 尺度感知的prompt设计,例如使用Likert量表,确保LLM生成的标签与原始标签的尺度一致。3) 噪声标签校正策略,例如使用LLM生成的标签替换置信度较低的原始标签。4) 数据增强策略,例如将LLM生成的标签作为额外的训练数据,与原始数据一起训练模型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用LLM生成的标签训练的RoBERTa模型在NewsEmp基准测试中取得了显著的性能提升,Pearson相关系数达到0.648,超过了之前的SOTA结果。通过噪声标签校正和数据增强,模型性能得到了显著改善,验证了LLM在标签生成方面的有效性。
🎯 应用场景
该研究成果可应用于心理健康评估、人机交互、情感计算等领域。通过更准确地评估人类的共情能力,可以帮助开发更具同理心的人工智能系统,改善人机交互体验,并为心理健康问题的早期诊断和干预提供支持。未来,该方法可以推广到其他需要高质量标注数据的领域。
📄 摘要(原文)
Large language models (LLMs) have revolutionised many fields, with LLM-as-a-service (LLMSaaS) offering accessible, general-purpose solutions without costly task-specific training. In contrast to the widely studied prompt engineering for directly solving tasks (in vivo), this paper explores LLMs' potential for in-vitro applications: using LLM-generated labels to improve supervised training of mainstream models. We examine two strategies - (1) noisy label correction and (2) training data augmentation - in empathy computing, an emerging task to predict psychology-based questionnaire outcomes from inputs like textual narratives. Crowdsourced datasets in this domain often suffer from noisy labels that misrepresent underlying empathy. We show that replacing or supplementing these crowdsourced labels with LLM-generated labels, developed using psychology-based scale-aware prompts, achieves statistically significant accuracy improvements. Notably, the RoBERTa pre-trained language model (PLM) trained with noise-reduced labels yields a state-of-the-art Pearson correlation coefficient of 0.648 on the public NewsEmp benchmarks. This paper further analyses evaluation metric selection and demographic biases to help guide the future development of more equitable empathy computing models. Code and LLM-generated labels are available at https://github.com/hasan-rakibul/LLMPathy.