LLM-MedQA: Enhancing Medical Question Answering through Case Studies in Large Language Models
作者: Hang Yang, Hao Chen, Hui Guo, Yineng Chen, Ching-Sheng Lin, Shu Hu, Jinrong Hu, Xi Wu, Xin Wang
分类: cs.CL, cs.AI, cs.IR
发布日期: 2024-12-31 (更新: 2025-01-18)
💡 一句话要点
LLM-MedQA:利用LLM案例研究增强医疗问答系统性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医疗问答 大型语言模型 案例研究 零样本学习 多智能体系统
📋 核心要点
- 医疗问答系统在提供高质量患者护理方面至关重要,但现有LLM在医学术语理解和复杂推理方面存在不足。
- 该论文提出一种多智能体MedQA系统,通过生成相似案例来增强LLM在医疗问答中的表现,无需额外训练数据。
- 实验结果表明,该方法在MedQA数据集上,准确率和F1分数均提升了7%,显著优于现有基准模型。
📝 摘要(中文)
本文提出了一种新颖的方法,通过在多智能体医疗问答(MedQA)系统中引入相似案例生成来提升性能。该方法利用最先进的LLM模型Llama3.1:70B,在零样本学习设置下,增强MedQA数据集上的表现。该方法充分利用了模型固有的医学知识和推理能力,无需额外的训练数据。实验结果表明,该方法在各种医疗QA任务中,相较于现有基准模型,准确率和F1分数均提升了7%。此外,本文还考察了模型在处理复杂医疗查询时的可解释性和可靠性。这项研究不仅为医疗问答提供了一个强大的解决方案,也为LLM在医疗领域更广泛的应用奠定了基础。
🔬 方法详解
问题定义:现有医疗问答系统依赖的LLM在理解医学领域特定术语和执行复杂推理方面面临挑战,这限制了它们在关键医疗应用中的有效性。论文旨在解决LLM在医疗问答中表现不佳的问题,特别是在零样本学习场景下,如何提升其准确性和可靠性。
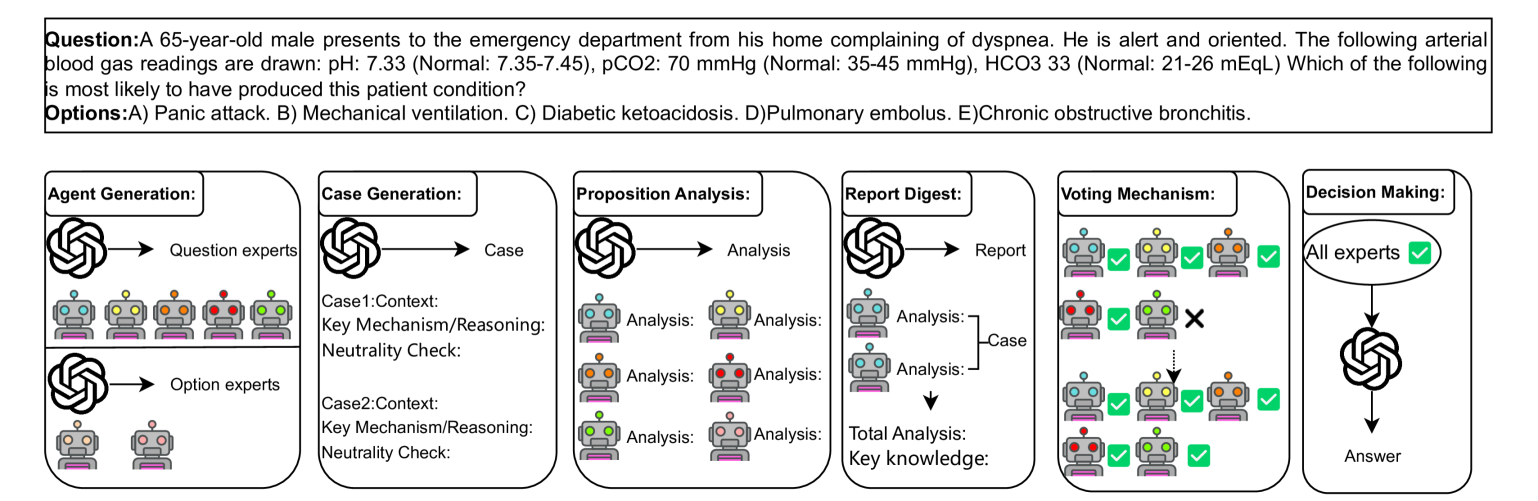
核心思路:论文的核心思路是利用LLM自身的能力,通过生成与问题相似的案例,来辅助LLM进行推理和回答。通过引入“案例生成”这一环节,让LLM能够更好地理解问题的上下文,并利用已有的医学知识进行更准确的判断。这种方法旨在模拟医生在诊断过程中参考类似病例的思维过程。
技术框架:该方法采用多智能体架构,其中一个智能体负责生成与输入问题相似的医疗案例,另一个智能体则利用这些案例来回答问题。具体流程如下:1) 输入医疗问题;2) 利用Llama3.1:70B模型生成相似案例;3) 将原始问题和生成的案例输入到另一个Llama3.1:70B模型中进行推理;4) 输出最终答案。整个过程无需额外的训练数据,属于零样本学习。
关键创新:该方法最重要的创新点在于将“案例生成”引入到医疗问答系统中。与传统的直接问答方法不同,该方法通过生成相似案例来增强LLM的理解和推理能力。这种方法更符合医生在实际诊断中的思维模式,能够提高LLM在医疗问答中的准确性和可靠性。此外,该方法在零样本学习设置下取得了显著的性能提升,表明其具有很强的泛化能力。
关键设计:论文的关键设计在于如何有效地生成相似案例。具体来说,论文利用Llama3.1:70B模型的文本生成能力,通过prompt engineering来引导模型生成与输入问题相关的医疗案例。Prompt的设计需要考虑到案例的完整性、相关性和多样性。此外,论文还考察了不同数量的生成案例对最终结果的影响,并选择了最优的案例数量。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在MedQA数据集上取得了显著的性能提升,准确率和F1分数均提高了7%。与现有基准模型相比,该方法在零样本学习设置下表现出色,证明了其有效性和泛化能力。此外,论文还对模型的可解释性和可靠性进行了分析,表明该方法在处理复杂医疗查询时具有较好的表现。
🎯 应用场景
该研究成果可应用于智能医疗助手、在线医疗咨询、医学教育等领域。通过提供更准确、可靠的医疗问答服务,可以辅助医生进行诊断,提高患者的就医效率和满意度。未来,该方法还可以扩展到其他医学领域,例如疾病预测、药物研发等,为医疗行业的智能化发展提供有力支持。
📄 摘要(原文)
Accurate and efficient question-answering systems are essential for delivering high-quality patient care in the medical field. While Large Language Models (LLMs) have made remarkable strides across various domains, they continue to face significant challenges in medical question answering, particularly in understanding domain-specific terminologies and performing complex reasoning. These limitations undermine their effectiveness in critical medical applications. To address these issues, we propose a novel approach incorporating similar case generation within a multi-agent medical question-answering (MedQA) system. Specifically, we leverage the Llama3.1:70B model, a state-of-the-art LLM, in a multi-agent architecture to enhance performance on the MedQA dataset using zero-shot learning. Our method capitalizes on the model's inherent medical knowledge and reasoning capabilities, eliminating the need for additional training data. Experimental results show substantial performance gains over existing benchmark models, with improvements of 7% in both accuracy and F1-score across various medical QA tasks. Furthermore, we examine the model's interpretability and reliability in addressing complex medical queries. This research not only offers a robust solution for medical question answering but also establishes a foundation for broader applications of LLMs in the medical domain.