TinyHelen's First Curriculum: Training and Evaluating Tiny Language Models in a Simpler Language Environment
作者: Ke Yang, Volodymyr Kindratenko, ChengXiang Zhai
分类: cs.CL, cs.AI
发布日期: 2024-12-31
🔗 代码/项目: GITHUB
💡 一句话要点
TinyHelen:在简化语言环境中训练和评估小型语言模型,提升学习效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 小型语言模型 简化语言环境 数据精简 指令遵循 预训练 语言模型评估 低资源训练
📋 核心要点
- 现有语言模型训练成本高昂,数据集和模型庞大,测试失败代价大,需要更高效的训练方法。
- 论文提出在简化语言环境中训练小型语言模型,通过降低数据噪声和复杂度,保留关键文本特征,提升学习效率。
- 实验表明,在精简数据集上训练的小型语言模型在指令遵循方面优于在原始数据集上训练的模型,验证了方法的有效性。
📝 摘要(中文)
由于大型数据集和模型的存在,训练语言模型(LM)及其应用代理的成本日益增加,使得测试失败难以承受。简化的语言环境作为原始的训练和测试场所,保留了基本的常识和沟通技巧,但以更易于理解的形式存在,从而可能提高LM的学习效率,并因此减少有效训练所需的模型大小和数据量。在这些简化的语言环境中,小型模型、数据集和代理的可行策略可能适用于复杂语言环境中较大的模型、数据集和代理。为了创建这样的环境,我们专注于两个方面:i)最小化语言数据集的噪声和复杂性,以及ii)保留基本的文本分布特征。与以前的方法不同,我们提出了一种通过消除噪声、最小化词汇并保持特定于类型的模式(例如,书籍、对话、代码等)来细化文本数据的流程。通过使用大型LM实施此流程,我们创建了一套更精简的LM训练和评估数据集:71M Leaner-Pretrain、7M Leaner-Instruct、用于评估语言能力的Leaner-Glue以及用于测试指令遵循能力的Leaner-Eval。我们的实验表明,更精简的预训练可以提高LM的学习效率。在这些数据集上训练的Tiny LM在不同语言粒度级别的指令遵循方面优于在原始数据集上训练的Tiny LM。此外,Leaner-Pretrain数据集与传统大型LM训练集的对齐使得能够以资源优化的方式分析学习目标、模型架构和训练技术如何影响语言建模和下游任务的性能。我们的代码和数据集可在https://github.com/EmpathYang/TinyHelen.git上找到。
🔬 方法详解
问题定义:现有大型语言模型的训练和评估成本高昂,主要由于数据集的规模和复杂性。现有方法难以在资源有限的情况下进行快速迭代和实验,并且难以分析不同训练策略对模型性能的影响。因此,需要一种更高效、更经济的方法来训练和评估语言模型,尤其是在小型模型上。
核心思路:论文的核心思路是构建一个简化的语言环境,该环境保留了语言的基本特征,但降低了噪声和复杂性。通过在这个简化环境中训练小型语言模型,可以提高学习效率,降低训练成本,并更容易地分析不同训练策略的影响。这种简化环境的设计目标是使小型模型上的有效策略能够推广到大型模型上。
技术框架:该方法包含一个数据处理pipeline,用于创建精简的语言模型训练和评估数据集。该pipeline主要包括以下步骤:1) 消除文本数据中的噪声;2) 最小化词汇量;3) 保留特定类型的文本模式(例如,书籍、对话、代码等)。基于此pipeline,作者构建了Leaner-Pretrain、Leaner-Instruct、Leaner-Glue和Leaner-Eval四个数据集,分别用于预训练、指令微调、语言能力评估和指令遵循能力测试。然后,在这些数据集上训练小型语言模型,并与在原始数据集上训练的模型进行比较。
关键创新:该论文的关键创新在于提出了一种系统性的方法来构建简化的语言环境,用于训练和评估语言模型。与以往方法不同,该方法不仅关注降低数据集的规模,还关注降低数据集的噪声和复杂性,同时保留语言的基本特征。此外,该方法还提供了一套完整的训练和评估数据集,方便研究人员进行实验和比较。
关键设计:在数据处理pipeline中,关键的设计包括噪声消除策略、词汇量最小化策略和特定类型文本模式的保留策略。具体的参数设置和实现细节在论文中没有详细描述,属于未知信息。损失函数和网络结构方面,论文主要关注数据集的构建,并没有对模型架构进行特别的设计,而是使用了现有的小型语言模型。
🖼️ 关键图片

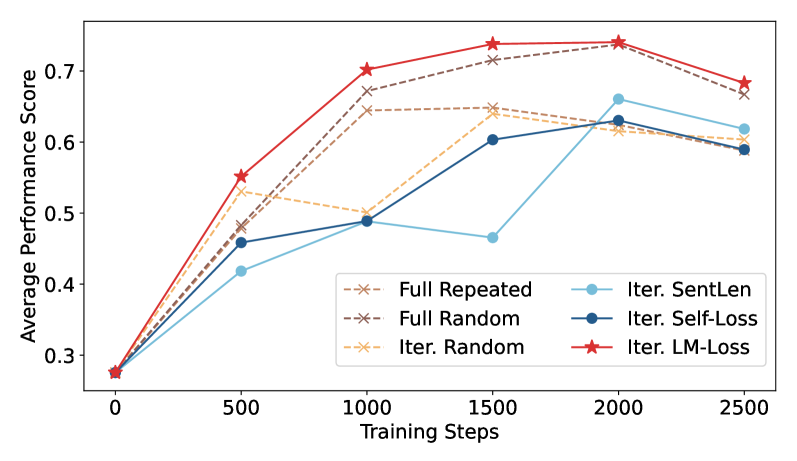

📊 实验亮点
实验结果表明,在Leaner-Pretrain数据集上预训练的小型语言模型在指令遵循任务上优于在原始数据集上训练的模型。具体性能提升幅度在论文中没有明确给出,属于未知信息。该结果验证了简化语言环境能够提高语言模型的学习效率。
🎯 应用场景
该研究成果可应用于资源受限场景下的语言模型训练和部署,例如移动设备、嵌入式系统等。此外,该方法还可以用于快速原型设计和实验,加速语言模型的研究和开发过程。通过简化语言环境,可以更有效地分析不同训练策略对模型性能的影响,从而指导大型语言模型的训练。
📄 摘要(原文)
Training language models (LMs) and their application agents is increasingly costly due to large datasets and models, making test failures difficult to bear. Simplified language environments serve as primordial training and testing grounds, retaining essential commonsense and communication skills but in a more digestible form, potentially enhancing the learning efficiency of LMs, and thus reducing the required model size and data volume for effective training and evaluation. In these simplified language environments, workable strategies for small models, datasets, and agents may be adaptable to larger models, datasets, and agents in complex language environments. To create such environments, we focus on two aspects: i) minimizing language dataset noise and complexity, and ii) preserving the essential text distribution characteristics. Unlike previous methods, we propose a pipeline to refine text data by eliminating noise, minimizing vocabulary, and maintaining genre-specific patterns (e.g., for books, conversation, code, etc.). Implementing this pipeline with large LMs, we have created a leaner suite of LM training and evaluation datasets: 71M Leaner-Pretrain, 7M Leaner-Instruct, Leaner-Glue for assessing linguistic proficiency, and Leaner-Eval for testing instruction-following ability. Our experiments show that leaner pre-training boosts LM learning efficiency. Tiny LMs trained on these datasets outperform those trained on original datasets in instruction-following across different language granularity levels. Moreover, the Leaner-Pretrain dataset's alignment with conventional large LM training sets enables resource-optimized analysis of how learning objectives, model architectures, and training techniques impact performance on language modeling and downstream tasks. Our code and datasets are available at https://github.com/EmpathYang/TinyHelen.git.