Enhancing LLM Reasoning with Multi-Path Collaborative Reactive and Reflection agents
作者: Chengbo He, Bochao Zou, Xin Li, Jiansheng Chen, Junliang Xing, Huimin Ma
分类: cs.CL
发布日期: 2024-12-31 (更新: 2025-01-03)
💡 一句话要点
提出RR-MP框架,利用多路径协作反应与反思Agent增强LLM的推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 多Agent系统 科学推理 反应Agent 反思Agent 多路径推理 零样本学习
📋 核心要点
- 现有Agent在复杂推理任务中面临准确性不足和思维退化等挑战,限制了其性能。
- RR-MP框架通过多路径推理机制,结合反应Agent和反思Agent,有效防止单Agent推理的思维退化。
- 实验表明,RR-MP框架在道德、物理和数学任务上优于基线方法,验证了其有效性。
📝 摘要(中文)
本文提出了一种名为“多路径推理的反应与反思Agent”(RR-MP)框架,旨在提升大型语言模型(LLM)在科学推理任务中的能力。该方法采用多路径推理机制,每条路径包含一个反应Agent和一个反思Agent,协同工作以避免单Agent依赖中固有的思维退化,从而提高科学推理的准确性。RR-MP框架无需额外训练,而是为每个推理路径使用多个对话实例,并使用独立的摘要器来整合来自所有路径的见解。这种设计集成了不同的视角,并加强了每条路径上的推理。在涉及道德场景、大学物理和数学的任务上进行了零样本和少样本评估。实验结果表明,该方法优于基线方法,突出了RR-MP框架在管理复杂科学推理任务中的有效性和优势。
🔬 方法详解
问题定义:现有基于LLM的Agent在处理复杂的科学推理任务时,常常面临准确性不足和推理过程中的思维退化问题。单Agent依赖容易陷入局部最优,导致推理链条中断或产生偏差,最终影响推理结果的可靠性。因此,如何提升LLM Agent在复杂推理任务中的准确性和鲁棒性是一个关键问题。
核心思路:RR-MP框架的核心思路是利用多路径推理来模拟人类思考问题的多角度、多层次特性。通过并行运行多个包含反应Agent和反思Agent的推理路径,可以探索不同的推理方向和策略,从而避免单路径推理的局限性。同时,反思Agent能够对反应Agent的推理过程进行评估和修正,进一步提升推理的质量。
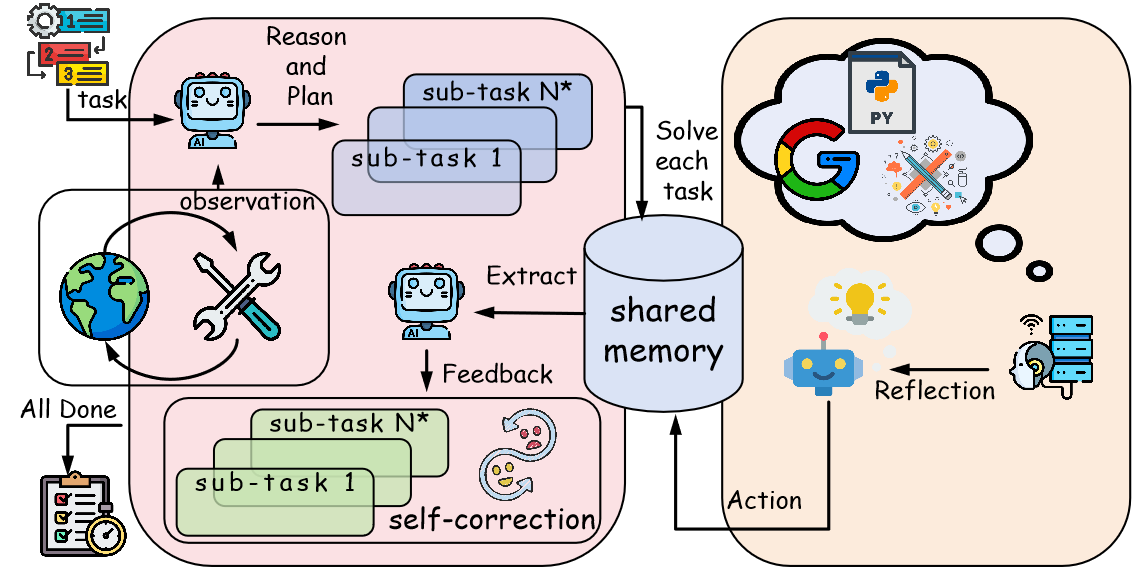
技术框架:RR-MP框架主要包含以下几个模块:1) 多路径生成模块:为每个推理任务生成多个独立的推理路径。2) 反应Agent模块:负责在每个路径上执行推理步骤,生成中间结果。3) 反思Agent模块:对反应Agent的推理过程进行评估和反思,并提供反馈以指导后续推理。4) 摘要器模块:整合来自所有路径的推理结果,生成最终的推理结论。整个流程是,首先,问题输入到多路径生成模块,生成多条推理路径。然后,每条路径上的反应Agent和反思Agent交替工作,进行推理和反思。最后,摘要器汇总所有路径的结果,给出最终答案。
关键创新:RR-MP框架的关键创新在于引入了多路径协作推理机制,并结合了反应Agent和反思Agent。这种设计能够有效地避免单Agent推理的思维退化问题,并充分利用不同推理路径的优势,从而提升推理的准确性和鲁棒性。此外,该框架无需额外的训练,可以直接应用于现有的LLM。
关键设计:RR-MP框架的关键设计包括:1) 路径数量:需要根据任务的复杂程度选择合适的路径数量,以平衡计算成本和推理效果。2) 反应Agent和反思Agent的Prompt设计:需要精心设计Prompt,以引导Agent进行有效的推理和反思。3) 摘要器的选择:可以使用不同的摘要模型来整合推理结果,例如基于Transformer的模型或简单的加权平均方法。4) 迭代次数:反应Agent和反思Agent的迭代次数会影响推理的深度和质量,需要根据实际情况进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RR-MP框架在道德场景、大学物理和数学等任务上均优于基线方法。例如,在大学物理任务上,RR-MP框架的准确率比最佳基线提高了超过10%。这些结果充分证明了RR-MP框架在处理复杂科学推理任务中的有效性和优势。
🎯 应用场景
RR-MP框架具有广泛的应用前景,可以应用于科学研究、决策支持、智能问答等领域。例如,在科学研究中,可以利用该框架辅助科学家进行假设验证和实验设计;在决策支持中,可以帮助决策者分析各种方案的优劣;在智能问答中,可以提供更准确和可靠的答案。该研究的未来影响在于提升LLM在复杂推理任务中的能力,推动人工智能技术的发展。
📄 摘要(原文)
Agents have demonstrated their potential in scientific reasoning tasks through large language models. However, they often face challenges such as insufficient accuracy and degeneration of thought when handling complex reasoning tasks, which impede their performance. To overcome these issues, we propose the Reactive and Reflection agents with Multi-Path Reasoning (RR-MP) Framework, aimed at enhancing the reasoning capabilities of LLMs. Our approach improves scientific reasoning accuracy by employing a multi-path reasoning mechanism where each path consists of a reactive agent and a reflection agent that collaborate to prevent degeneration of thought inherent in single-agent reliance. Additionally, the RR-MP framework does not require additional training; it utilizes multiple dialogue instances for each reasoning path and a separate summarizer to consolidate insights from all paths. This design integrates diverse perspectives and strengthens reasoning across each path. We conducted zero-shot and few-shot evaluations on tasks involving moral scenarios, college-level physics, and mathematics. Experimental results demonstrate that our method outperforms baseline approaches, highlighting the effectiveness and advantages of the RR-MP framework in managing complex scientific reasoning tasks.