Chunk-Distilled Language Modeling
作者: Yanhong Li, Karen Livescu, Jiawei Zhou
分类: cs.CL, cs.AI
发布日期: 2024-12-31
💡 一句话要点
提出Chunk-Distilled LM,通过检索式生成多token文本块,提升LLM效率与可控性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 文本生成 检索式生成 知识蒸馏 多token生成
📋 核心要点
- 现有LLM逐token生成效率低,且难以快速适应新数据和领域知识,限制了其应用。
- CD-LM结合深度网络LLM与检索模块,一步生成多token文本块,提升生成效率。
- CD-LM通过构建可定制的数据存储,灵活利用模型内部知识或外部专家知识,增强模型可控性。
📝 摘要(中文)
本文提出了一种名为Chunk-Distilled Language Modeling (CD-LM) 的文本生成方法,旨在解决当前大型语言模型 (LLM) 中存在的两个挑战:token级别生成效率低下,以及难以适应新数据和知识。该方法将基于深度网络的LLM与直接的检索模块相结合,从而能够在单个解码步骤中生成多token文本块。检索框架支持灵活构建模型或领域特定的数据存储,既可以利用现有模型的内部知识,也可以整合来自人工标注语料库的专家见解。这种适应性增强了对语言模型分布的控制,而无需额外的训练。我们展示了CD-LM的公式,以及证明其在各种下游任务中提高语言模型性能和效率的性能指标。代码和数据将公开提供。
🔬 方法详解
问题定义:现有大型语言模型在文本生成时,通常采用逐个token生成的方式,计算量大,效率低下。此外,如何使LLM快速适应新的数据和知识,例如特定领域的专业知识,也是一个挑战。直接对LLM进行fine-tuning成本高昂,且可能影响其通用能力。
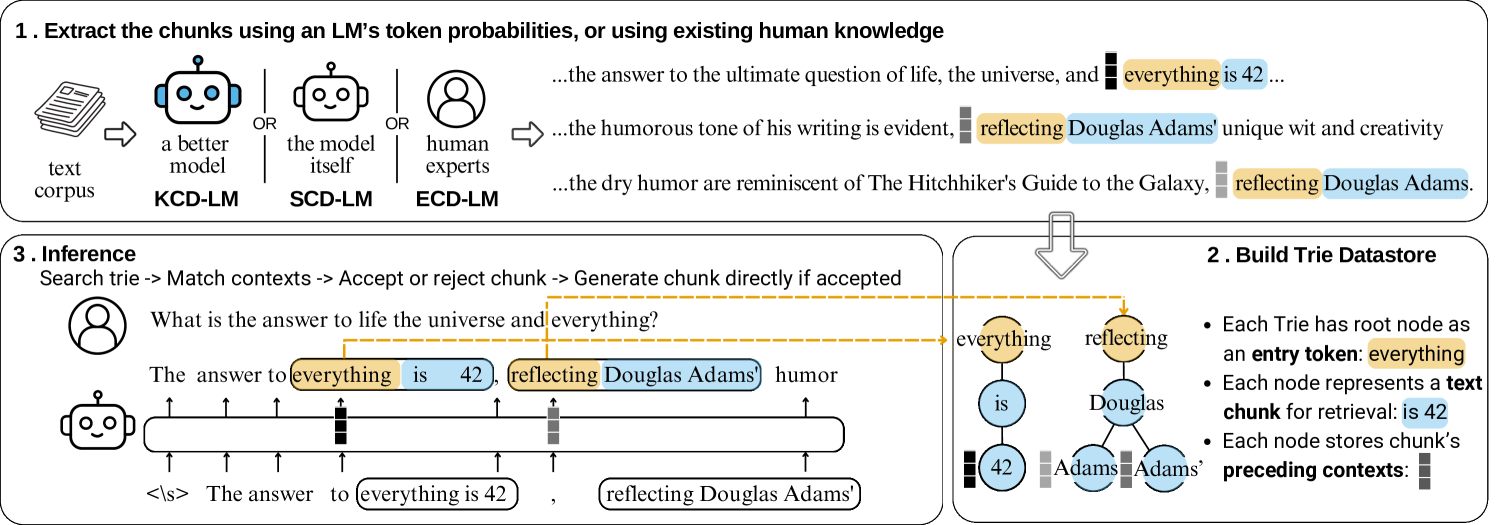
核心思路:CD-LM的核心思路是利用检索机制,在生成文本时,不再逐个token生成,而是从预先构建的数据存储中检索出多个token组成的文本块(chunk),然后直接输出。这样可以显著减少解码步骤,提高生成效率。同时,通过灵活构建数据存储,可以方便地将新的知识或数据注入到模型中,而无需重新训练整个模型。
技术框架:CD-LM的整体框架包含两个主要模块:一个是预训练的LLM,用于生成文本表示;另一个是检索模块,用于从数据存储中检索相关的文本块。具体流程如下:首先,使用LLM对输入文本进行编码,得到文本表示。然后,使用该表示作为查询向量,在数据存储中进行检索,找到最相关的若干个文本块。最后,将检索到的文本块作为输出,或者与LLM的生成结果进行融合,得到最终的生成文本。
关键创新:CD-LM的关键创新在于将检索机制引入到语言模型中,实现了多token级别的生成。与传统的逐token生成方法相比,CD-LM可以显著提高生成效率,并方便地集成新的知识和数据。此外,CD-LM的数据存储可以根据不同的任务和领域进行定制,从而实现对语言模型分布的更精细控制。
关键设计:CD-LM的关键设计包括:1) 数据存储的构建方式,可以选择利用现有模型的内部知识,也可以整合来自人工标注语料库的专家见解;2) 检索算法的选择,可以使用近似最近邻搜索等高效算法,以保证检索速度;3) 如何将检索到的文本块与LLM的生成结果进行融合,可以使用简单的拼接或者更复杂的注意力机制。
🖼️ 关键图片

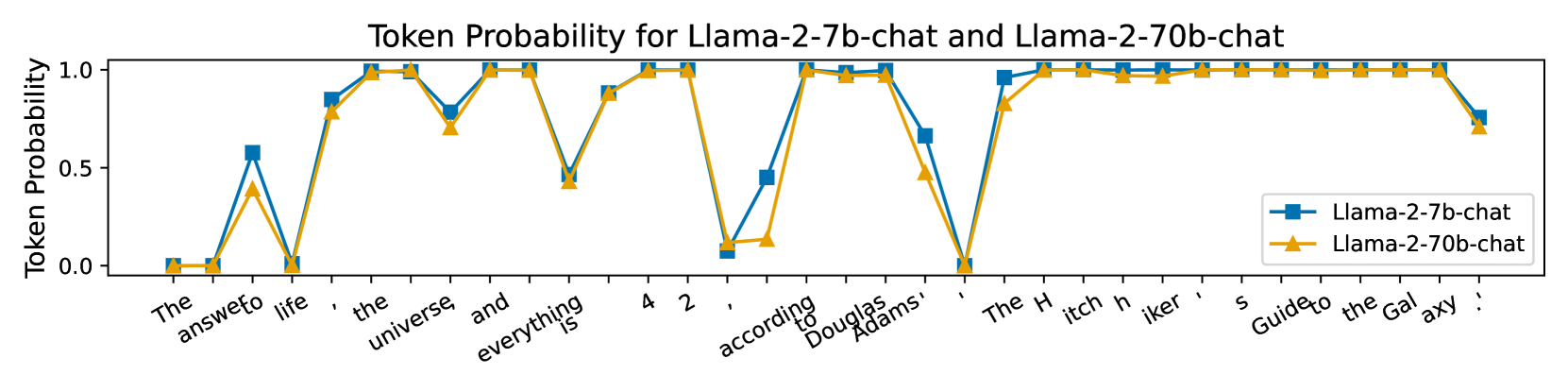
📊 实验亮点
论文通过实验证明,CD-LM在多个下游任务上都取得了显著的性能提升。具体而言,CD-LM在生成速度上比传统的LLM快数倍,同时在BLEU、ROUGE等指标上也有所提升。实验结果表明,CD-LM能够有效地提高语言模型的性能和效率。
🎯 应用场景
CD-LM可应用于多种文本生成场景,例如机器翻译、文本摘要、对话生成等。其高效的生成能力使其在对实时性要求较高的场景中具有优势。通过定制数据存储,CD-LM可以轻松应用于特定领域,例如医疗、金融等,生成专业性更强的文本。此外,CD-LM还可用于知识图谱补全、信息检索等任务。
📄 摘要(原文)
We introduce Chunk-Distilled Language Modeling (CD-LM), an approach to text generation that addresses two challenges in current large language models (LLMs): the inefficiency of token-level generation, and the difficulty of adapting to new data and knowledge. Our method combines deep network-based LLMs with a straightforward retrieval module, which allows the generation of multi-token text chunks at a single decoding step. Our retrieval framework enables flexible construction of model- or domain-specific datastores, either leveraging the internal knowledge of existing models, or incorporating expert insights from human-annotated corpora. This adaptability allows for enhanced control over the language model's distribution without necessitating additional training. We present the CD-LM formulation along with performance metrics demonstrating its ability to improve language model performance and efficiency across a diverse set of downstream tasks. Code and data will be made publicly available.