GRASP: Replace Redundant Layers with Adaptive Singular Parameters for Efficient Model Compression
作者: Kainan Liu, Yong Zhang, Ning Cheng, Zhitao Li, Shaojun Wang, Jing Xiao
分类: cs.CL, cs.LG
发布日期: 2024-12-31 (更新: 2025-06-06)
备注: 15 pages, 5 figures
💡 一句话要点
GRASP:通过自适应奇异参数替换冗余层,实现高效LLM压缩
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模型压缩 大型语言模型 奇异值分解 梯度归因 模型剪枝
📋 核心要点
- 大型语言模型存在功能冗余层,直接剪枝会导致性能显著下降。
- GRASP通过梯度归因自适应识别并保留关键奇异分量,替换冗余层。
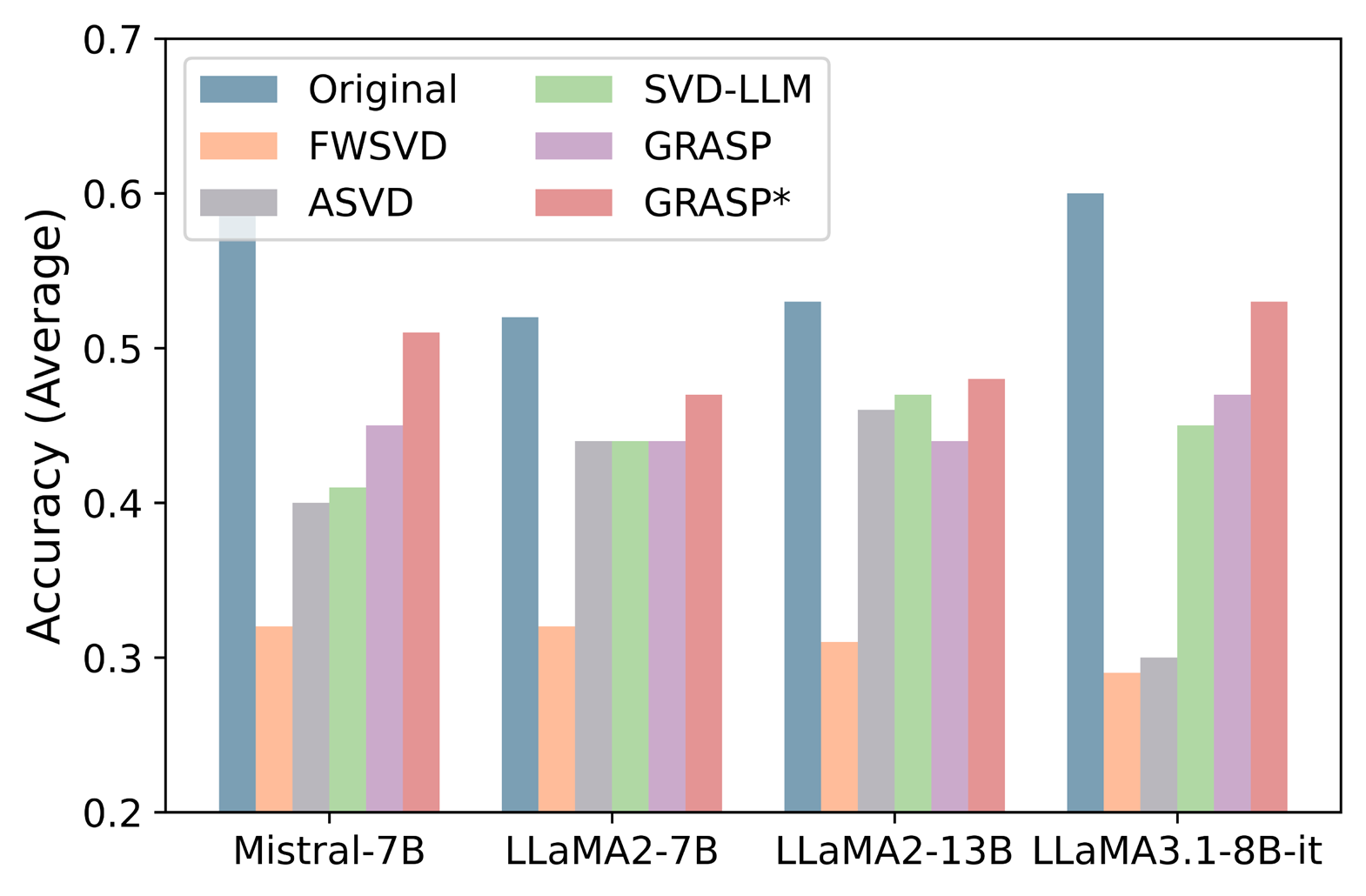
- 实验表明,GRASP在20%压缩率下,性能达到原始模型的90%,优于现有方法。
📝 摘要(中文)
现有研究表明,大型语言模型(LLM)中存在大量功能冗余的层,可以通过移除这些层来降低推理成本,从而实现模型压缩。然而,不加选择的层剪枝通常会导致显著的性能下降。本文提出了GRASP(基于梯度的自适应奇异参数保留)压缩框架,通过保留对敏感度有感知的奇异值来缓解这个问题。与直接层剪枝不同,GRASP利用基于梯度的归因方法,在小型校准数据集上自适应地识别和保留关键的奇异分量。通过仅用最少的参数集替换冗余层,GRASP实现了高效的压缩,同时以最小的开销保持了强大的性能。在多个LLM上的实验表明,GRASP始终优于现有的压缩方法,在20%的压缩率下实现了原始模型90%的性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)压缩过程中,直接剪枝冗余层导致性能显著下降的问题。现有方法在移除冗余层时,往往忽略了不同层的重要性,导致关键信息丢失,从而影响模型的整体性能。因此,如何在压缩模型的同时,尽可能地保留模型的关键信息,是本论文要解决的核心问题。
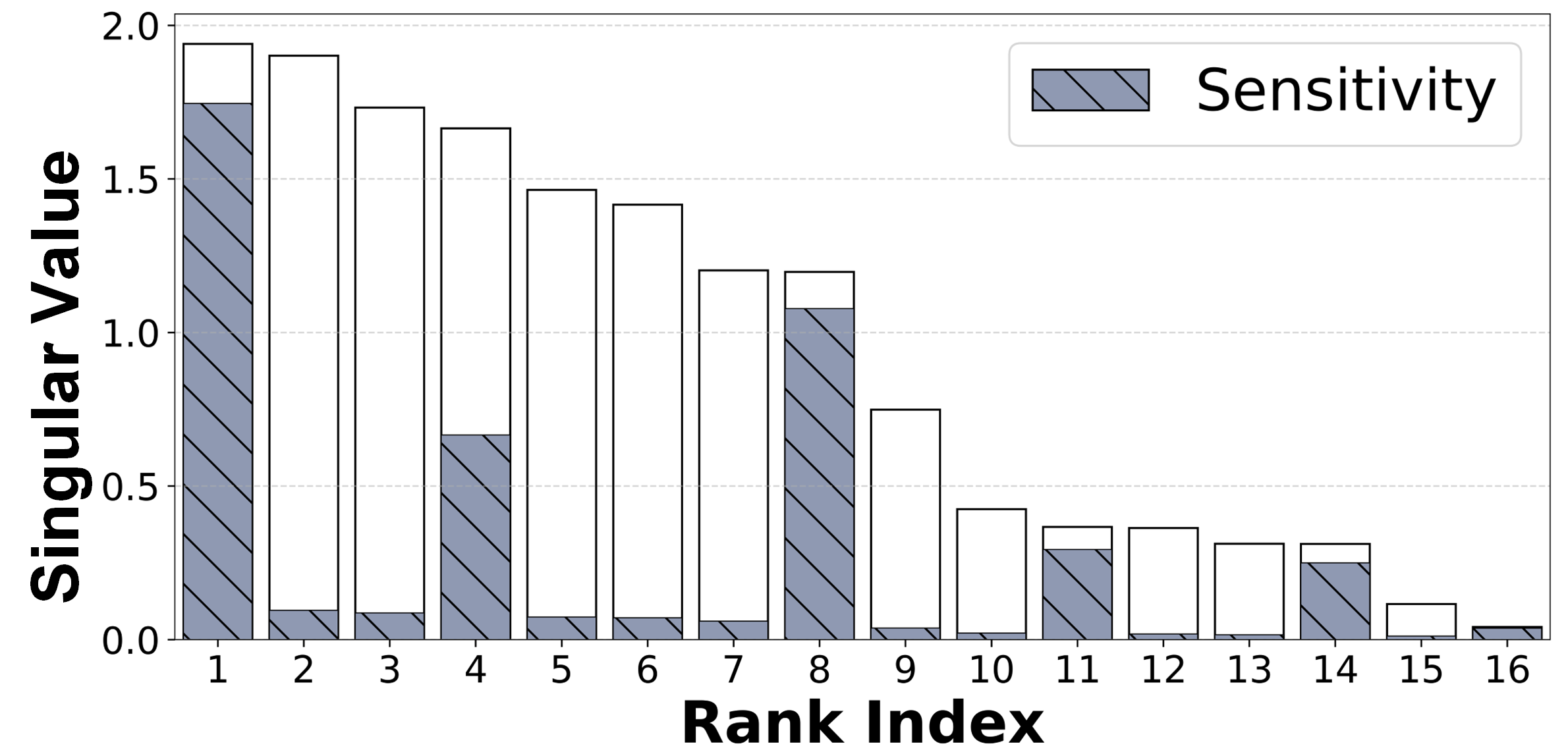
核心思路:GRASP的核心思路是,并非所有冗余层中的信息都是不重要的,关键在于识别并保留那些对模型性能至关重要的信息。论文通过分析梯度信息,来评估每个奇异值对模型性能的贡献,并自适应地保留重要的奇异分量,从而在压缩模型的同时,尽可能地减少性能损失。
技术框架:GRASP框架主要包含以下几个阶段:1) 奇异值分解:对模型中的每一层进行奇异值分解(SVD),将每一层分解为奇异值和奇异向量的乘积。2) 梯度归因:使用一个小的校准数据集,计算每个奇异值对模型输出的梯度。梯度越大,说明该奇异值对模型性能的贡献越大。3) 自适应保留:根据梯度信息,自适应地选择保留重要的奇异值。对于梯度较小的奇异值,则将其对应的奇异向量置零,从而实现模型的压缩。4) 模型重构:使用保留的奇异值和奇异向量,重构压缩后的模型。
关键创新:GRASP的关键创新在于,它并非简单地移除冗余层,而是通过梯度归因来识别并保留对模型性能至关重要的奇异分量。与现有方法相比,GRASP能够更精确地识别冗余信息,从而在压缩模型的同时,尽可能地减少性能损失。此外,GRASP采用自适应的保留策略,能够根据不同层的特性,灵活地调整压缩比例,从而实现更高效的压缩。
关键设计:GRASP的关键设计包括:1) 梯度计算:使用链式法则计算每个奇异值对模型输出的梯度。为了提高计算效率,论文采用了一种近似的梯度计算方法。2) 自适应阈值:根据梯度分布,自适应地设置一个阈值,用于判断哪些奇异值是重要的。3) 校准数据集:使用一个小的校准数据集来计算梯度。校准数据集的选择对GRASP的性能至关重要。论文建议使用与目标任务相关的数据集作为校准数据集。
🖼️ 关键图片

📊 实验亮点
GRASP在多个LLM上进行了实验,结果表明,GRASP始终优于现有的压缩方法。例如,在20%的压缩率下,GRASP能够达到原始模型90%的性能,而其他方法的性能通常会下降更多。此外,GRASP的计算开销很小,不会显著增加模型的训练和推理时间。这些实验结果表明,GRASP是一种高效且有效的LLM压缩方法。
🎯 应用场景
GRASP具有广泛的应用前景,可用于在资源受限的设备上部署大型语言模型,例如移动设备、嵌入式系统等。通过GRASP压缩后的模型,可以在保持较高性能的同时,显著降低计算和存储成本,从而使得LLM能够在更广泛的场景中应用。此外,GRASP还可以用于加速模型的训练和推理过程,提高模型的效率。
📄 摘要(原文)
Recent studies have demonstrated that many layers are functionally redundant in large language models (LLMs), enabling model compression by removing these layers to reduce inference cost. While such approaches can improve efficiency, indiscriminate layer pruning often results in significant performance degradation. In this paper, we propose GRASP (Gradient-based Retention of Adaptive Singular Parameters), a novel compression framework that mitigates this issue by preserving sensitivity-aware singular values. Unlike direct layer pruning, GRASP leverages gradient-based attribution on a small calibration dataset to adaptively identify and retain critical singular components. By replacing redundant layers with only a minimal set of parameters, GRASP achieves efficient compression while maintaining strong performance with minimal overhead. Experiments across multiple LLMs show that GRASP consistently outperforms existing compression methods, achieving 90% of the original model's performance under a 20% compression ratio.