LLM-Rubric: A Multidimensional, Calibrated Approach to Automated Evaluation of Natural Language Texts
作者: Helia Hashemi, Jason Eisner, Corby Rosset, Benjamin Van Durme, Chris Kedzie
分类: cs.CL
发布日期: 2024-12-31
备注: Updated version of 17 June 2024
期刊: Proceedings of ACL 2024 (Volume 1: Long Papers), pp. 13806-13834
DOI: 10.18653/v1/2024.acl-long.745
💡 一句话要点
LLM-Rubric:一种多维度、校准的方法,用于自然语言文本的自动评估。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自然语言处理 文本评估 大型语言模型 评分细则 校准模型 对话系统 用户满意度 自动化评估
📋 核心要点
- 现有自然语言文本评估方法缺乏细粒度,难以捕捉文本的多维度质量特征,且LLM直接评估结果与人类判断存在偏差。
- LLM-Rubric框架利用人工构建的评分细则,提示LLM生成多维度评估结果,并通过校准模型预测人类评估者的判断。
- 实验表明,LLM-Rubric在对话系统评估中,能更准确地预测用户满意度,显著优于未校准的基线方法。
📝 摘要(中文)
本文介绍了一种用于自然语言文本自动评估的框架。该框架使用人工构建的评分细则来描述如何评估多个感兴趣的维度。为了评估文本,使用每个评分细则问题提示大型语言模型(LLM),并生成潜在响应的分布。LLM的预测通常与人类评估者不太一致——事实上,人类之间也存在分歧。然而,可以将多个LLM分布$ extit{组合}$起来$ extit{预测}$每个人类评估者对所有问题的注释,包括评估整体质量或相关性的总结性问题。LLM-Rubric通过训练一个小型前馈神经网络来实现这一点,该网络包含特定于评估者和独立于评估者的参数。在评估人机信息检索任务中的对话系统时,我们发现具有9个问题的LLM-Rubric(评估自然性、简洁性和引用质量等维度)可以预测人类评估者对整体用户满意度的评估(范围为1-4),均方根误差小于0.5,比未校准的基线提高了2倍。
🔬 方法详解
问题定义:论文旨在解决自然语言文本自动评估中,LLM直接评估结果与人类判断不一致,且缺乏多维度细粒度评估的问题。现有方法难以有效捕捉文本的多个质量维度,导致评估结果不够准确可靠。
核心思路:论文的核心思路是利用人工构建的评分细则,将文本评估分解为多个维度,并使用LLM对每个维度进行评估。然后,通过训练一个校准模型,将LLM的预测结果与人类评估者的判断对齐,从而提高评估的准确性和可靠性。
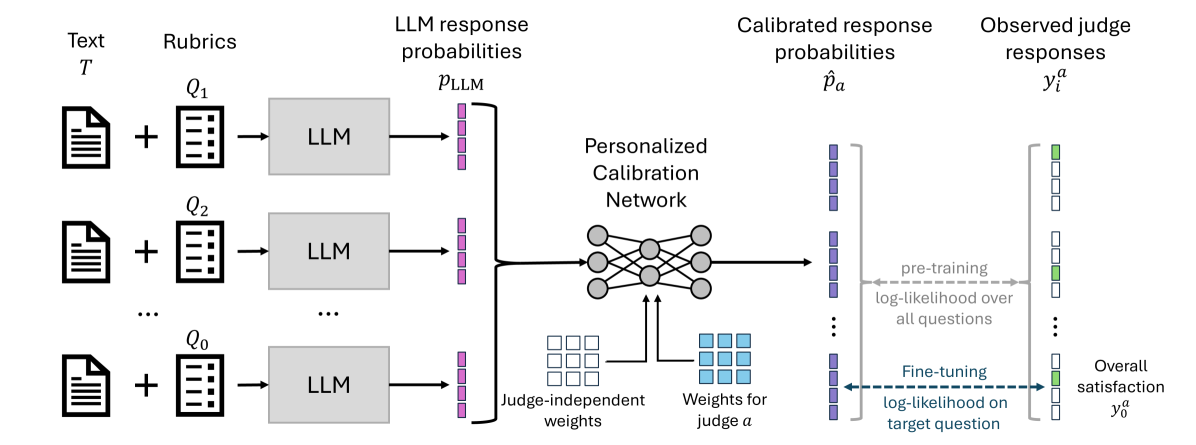
技术框架:LLM-Rubric框架包含以下主要模块:1) 人工构建评分细则:定义多个评估维度和对应的问题。2) LLM评估:使用评分细则中的问题提示LLM,生成每个维度的评估结果(概率分布)。3) 校准模型:训练一个前馈神经网络,输入LLM的评估结果,预测人类评估者的判断。该网络包含评估者特定和独立参数,以捕捉评估者之间的差异。4) 结果整合:将校准模型的预测结果整合,得到最终的文本质量评估。
关键创新:该方法最重要的创新点在于,它将LLM的评估能力与人工构建的评分细则相结合,实现了多维度、细粒度的文本评估。此外,通过训练校准模型,有效地消除了LLM预测与人类判断之间的偏差,提高了评估的准确性。
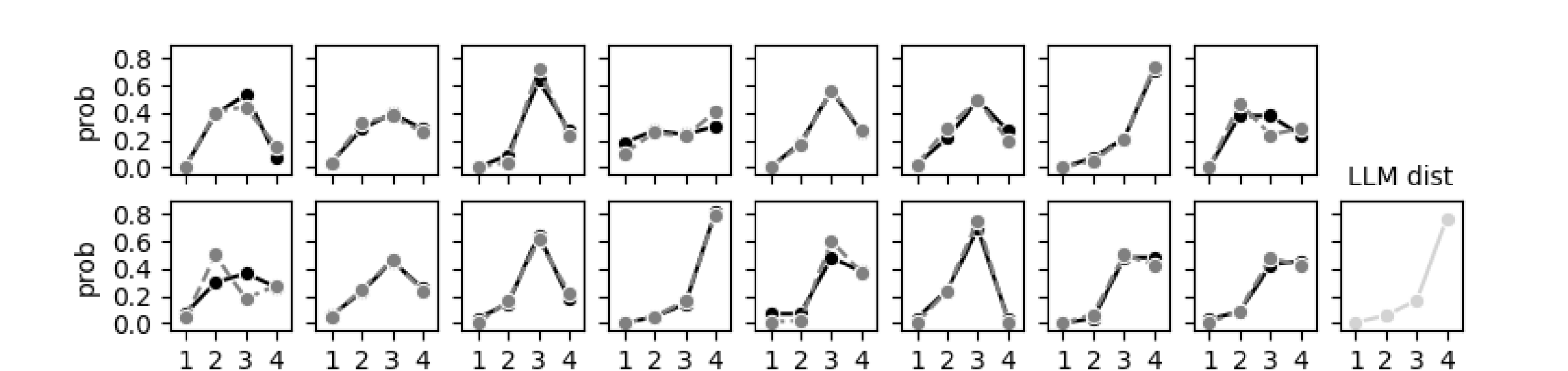
关键设计:校准模型是一个小型前馈神经网络,输入是LLM在各个维度上的预测分布。网络包含评估者特定和独立参数,用于学习不同评估者的偏好和偏差。损失函数采用均方误差,目标是最小化校准模型预测结果与人类评估者判断之间的差异。实验中,使用了9个问题来评估对话系统的自然性、简洁性和引用质量等维度。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM-Rubric在评估对话系统用户满意度方面表现出色,均方根误差小于0.5,相比未校准的基线方法,性能提升了2倍。这表明该方法能够更准确地预测人类评估者的判断,为自然语言文本的自动评估提供了一种有效途径。
🎯 应用场景
该研究成果可应用于各种自然语言生成系统的自动评估,例如对话系统、机器翻译系统、文本摘要系统等。通过自动评估,可以快速、高效地衡量系统的性能,并为系统改进提供指导。此外,该方法还可以用于教育领域,自动评估学生的写作质量,提供个性化的反馈。
📄 摘要(原文)
This paper introduces a framework for the automated evaluation of natural language texts. A manually constructed rubric describes how to assess multiple dimensions of interest. To evaluate a text, a large language model (LLM) is prompted with each rubric question and produces a distribution over potential responses. The LLM predictions often fail to agree well with human judges -- indeed, the humans do not fully agree with one another. However, the multiple LLM distributions can be $\textit{combined}$ to $\textit{predict}$ each human judge's annotations on all questions, including a summary question that assesses overall quality or relevance. LLM-Rubric accomplishes this by training a small feed-forward neural network that includes both judge-specific and judge-independent parameters. When evaluating dialogue systems in a human-AI information-seeking task, we find that LLM-Rubric with 9 questions (assessing dimensions such as naturalness, conciseness, and citation quality) predicts human judges' assessment of overall user satisfaction, on a scale of 1--4, with RMS error $< 0.5$, a $2\times$ improvement over the uncalibrated baseline.