Echoes in AI: Quantifying lack of plot diversity in LLM outputs
作者: Weijia Xu, Nebojsa Jojic, Sudha Rao, Chris Brockett, Bill Dolan
分类: cs.CL
发布日期: 2024-12-31 (更新: 2025-08-29)
备注: PNAS Vol. 122 No. 35. Copyright \c{opyright} 2025 the Author(s). Published by PNAS. This open access article is distributed under Creative Commons Attribution-NonCommercial-NoDerivatives License 4.0 (CC BY-NC-ND)
期刊: Proc. Natl. Acad. Sci. U.S.A. 122 (35) e2504966122 (2025)
💡 一句话要点
提出Sui Generis指标,量化评估大语言模型生成故事中情节元素的多样性不足问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 故事生成 情节多样性 自动评估 Sui Generis评分
📋 核心要点
- 现有大语言模型在故事生成中缺乏足够的情节多样性,限制了其在创意内容生成方面的应用潜力。
- 论文提出Sui Generis评分,一种自动化的情节独特性度量指标,用于量化评估LLM生成故事的情节多样性。
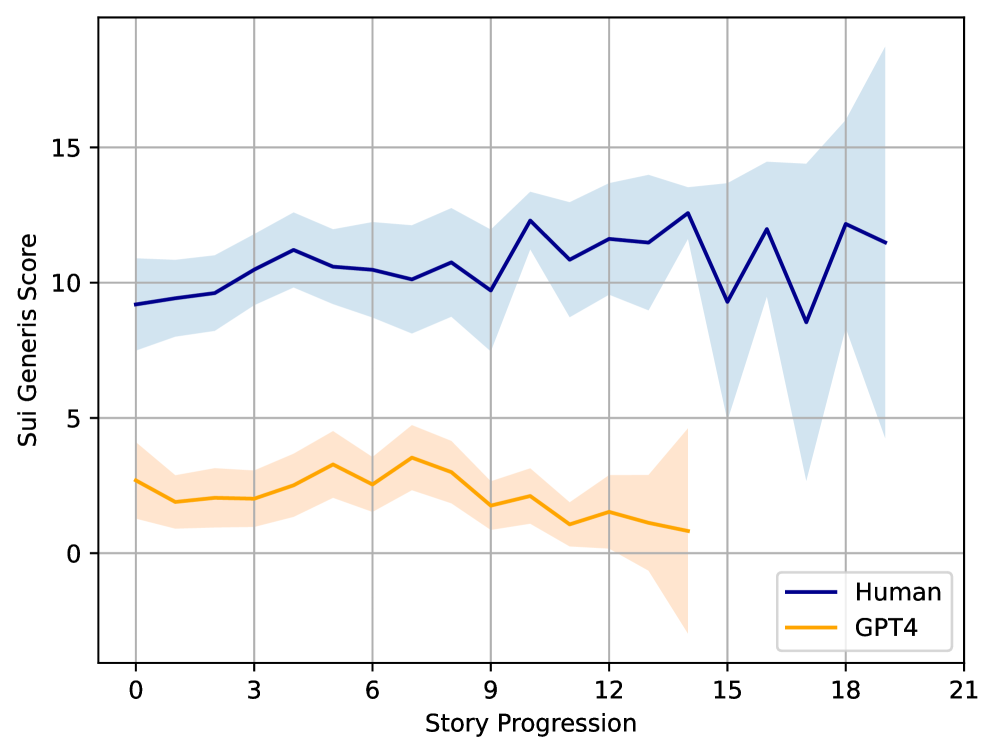
- 实验表明,LLM生成的故事情节元素重复率高,Sui Generis评分与人类对故事惊喜程度的判断具有相关性。
📝 摘要(中文)
随着大型语言模型(LLMs)的快速发展,它们在创意内容构思和生成方面的应用日益广泛。一个关键问题随之出现:当前LLMs能否提供足够多样化的想法,以真正促进集体创造力?我们研究了两个最先进的LLMs,GPT-4和LLaMA-3,在故事生成方面的表现,并发现LLM生成的故事通常包含在多个生成结果中重复出现的情节元素。为了量化这种现象,我们引入了Sui Generis评分,这是一种自动指标,用于衡量在LLM下使用相同提示生成的替代故事情节中,情节元素的独特性。在100个短篇故事上的评估表明,LLM生成的故事通常包含在不同生成结果和不同LLMs中频繁重复的特殊情节元素的组合,而原始人类撰写的故事的情节很少被重新创建,甚至很少被重复。此外,我们的人工评估表明,故事片段中Sui Generis评分的排名与人类对惊喜程度的判断适度相关,即使评分计算是完全自动的,不依赖于人类判断。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在故事生成任务中情节多样性不足的问题。现有方法难以有效评估LLM生成内容的情节独特性,导致生成的故事情节缺乏新颖性和创意,限制了LLM在创意内容生成领域的应用。
核心思路:论文的核心思路是通过量化情节元素的独特性来评估LLM生成故事的多样性。具体而言,论文提出了一种名为Sui Generis的自动评分指标,该指标衡量在给定提示下,LLM生成的多个故事情节中特定情节元素的唯一性。Sui Generis评分越高,表示该情节元素越独特,故事的多样性越高。
技术框架:论文的技术框架主要包括以下几个步骤:1) 使用LLM(GPT-4和LLaMA-3)生成多个基于相同提示的故事;2) 将生成的故事分解为情节元素;3) 使用Sui Generis评分计算每个情节元素的独特性;4) 分析Sui Generis评分的分布,评估LLM生成故事的情节多样性;5) 进行人工评估,验证Sui Generis评分与人类对故事惊喜程度判断的相关性。
关键创新:论文最重要的技术创新点在于提出了Sui Generis评分,这是一种自动化的情节独特性度量指标。与现有方法相比,Sui Generis评分无需人工标注,能够高效地评估LLM生成故事的情节多样性。此外,论文还通过实验验证了Sui Generis评分与人类对故事惊喜程度判断的相关性,证明了该指标的有效性。
关键设计:Sui Generis评分的计算方式未知,论文中没有详细描述。论文使用了GPT-4和LLaMA-3作为故事生成模型,并选择了100个短篇故事作为评估数据集。人工评估部分,论文采用了未知的人工评估方法,评估了故事片段的惊喜程度。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LLM生成的故事情节元素重复率较高,Sui Generis评分较低,表明LLM在故事生成方面缺乏足够的多样性。此外,实验还发现Sui Generis评分与人类对故事惊喜程度的判断具有适度相关性,验证了该指标的有效性。具体性能数据和提升幅度未知。
🎯 应用场景
该研究成果可应用于评估和改进LLM在创意内容生成方面的能力,例如故事创作、剧本编写、广告文案生成等。通过优化LLM的训练数据和生成策略,可以提高生成内容的多样性和创新性,从而更好地满足用户的创意需求。此外,Sui Generis评分可以作为一种自动化的评估工具,用于比较不同LLM的创意生成能力。
📄 摘要(原文)
With rapid advances in large language models (LLMs), there has been an increasing application of LLMs in creative content ideation and generation. A critical question emerges: can current LLMs provide ideas that are diverse enough to truly bolster collective creativity? We examine two state-of-the-art LLMs, GPT-4 and LLaMA-3, on story generation and discover that LLM-generated stories often consist of plot elements that are echoed across a number of generations. To quantify this phenomenon, we introduce the Sui Generis score, an automatic metric that measures the uniqueness of a plot element among alternative storylines generated using the same prompt under an LLM. Evaluating on 100 short stories, we find that LLM-generated stories often contain combinations of idiosyncratic plot elements echoed frequently across generations and across different LLMs, while plots from the original human-written stories are rarely recreated or even echoed in pieces. Moreover, our human evaluation shows that the ranking of Sui Generis scores among story segments correlates moderately with human judgment of surprise level, even though score computation is completely automatic without relying on human judgment.