Have We Designed Generalizable Structural Knowledge Promptings? Systematic Evaluation and Rethinking
作者: Yichi Zhang, Zhuo Chen, Lingbing Guo, Yajing Xu, Shaokai Chen, Mengshu Sun, Binbin Hu, Zhiqiang Zhang, Lei Liang, Wen Zhang, Huajun Chen
分类: cs.CL
发布日期: 2024-12-31
备注: Work in progress
💡 一句话要点
系统性评估结构化知识提示的泛化性,并提出SUBARU基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 结构化知识提示 大型语言模型 泛化能力 知识密集型任务 基准测试 SUBARU 知识图谱 自然语言处理
📋 核心要点
- 现有结构化知识提示方法缺乏对泛化能力的系统性评估,难以确定其适用范围和局限性。
- 论文通过多维度评估结构化知识提示的泛化能力,并构建多粒度、多层次的SUBARU基准。
- SUBARU基准包含9个不同任务,旨在全面评估结构化知识提示在不同粒度和难度下的表现。
📝 摘要(中文)
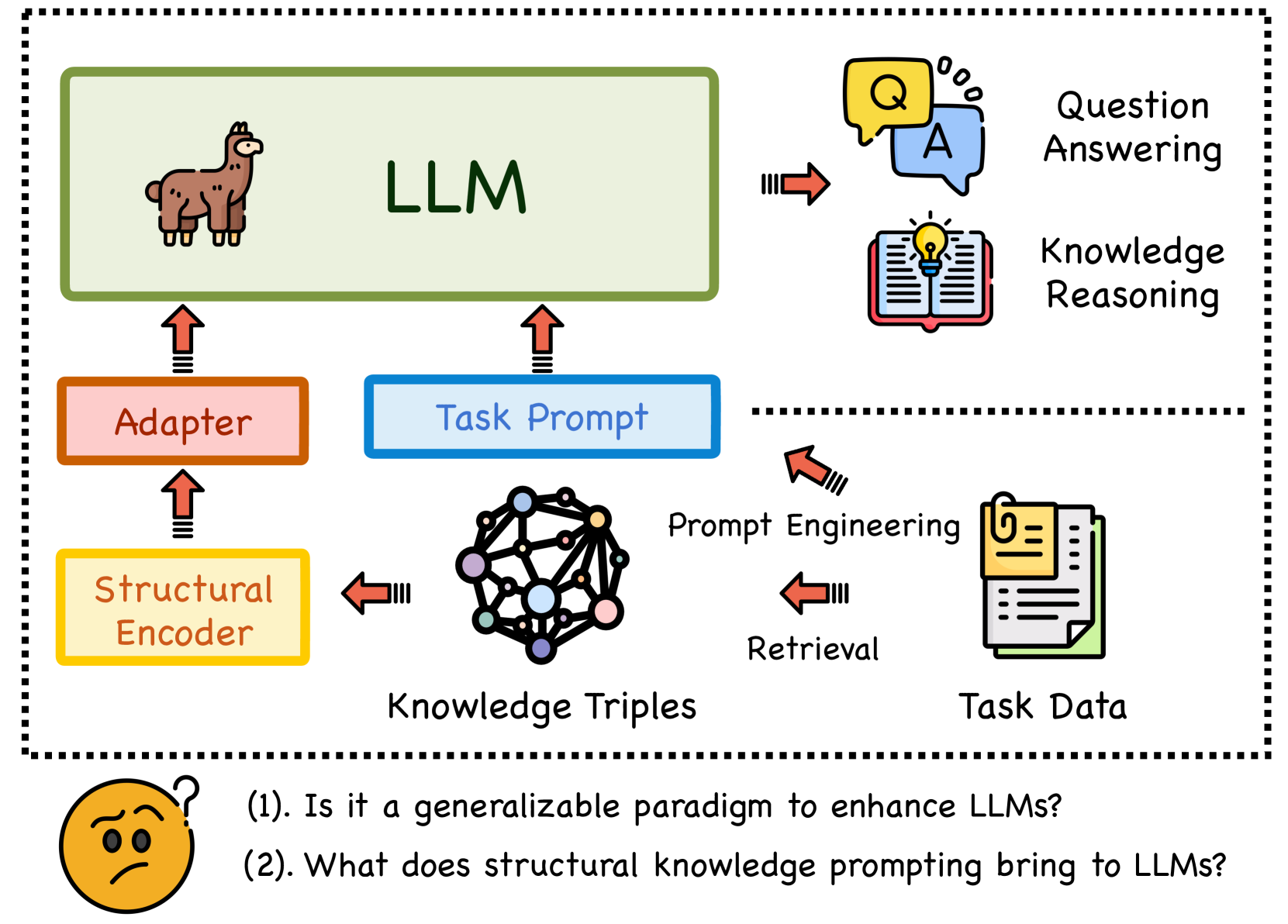
大型语言模型(LLMs)在文本生成方面表现出色,但缺乏事实准确性仍然是一个主要问题。结构化知识提示(SKP)是一种将外部知识整合到LLMs中的重要方法,通过结合结构化表示,在许多知识密集型任务中取得了最先进的结果。然而,现有方法通常侧重于特定问题,缺乏对SKP泛化性和能力边界的全面探索。本文旨在从粒度、可迁移性、可扩展性和通用性四个角度评估和反思SKP范式的泛化能力。为了提供全面的评估,我们引入了一个名为SUBARU的新型多粒度、多层次基准,该基准包含9个不同任务,具有不同的粒度和难度级别。
🔬 方法详解
问题定义:现有结构化知识提示(SKP)方法在知识密集型任务中表现出色,但缺乏对泛化能力的系统评估。现有方法通常针对特定问题设计,难以评估其在不同粒度、可迁移性、可扩展性和通用性方面的表现。因此,需要一个全面的基准来评估SKP的泛化能力,并为未来的研究提供指导。
核心思路:论文的核心思路是构建一个多粒度、多层次的基准(SUBARU),从四个关键维度(粒度、可迁移性、可扩展性和通用性)系统地评估SKP的泛化能力。通过在SUBARU基准上评估不同的SKP方法,可以深入了解其优势和局限性,并为未来的研究提供方向。
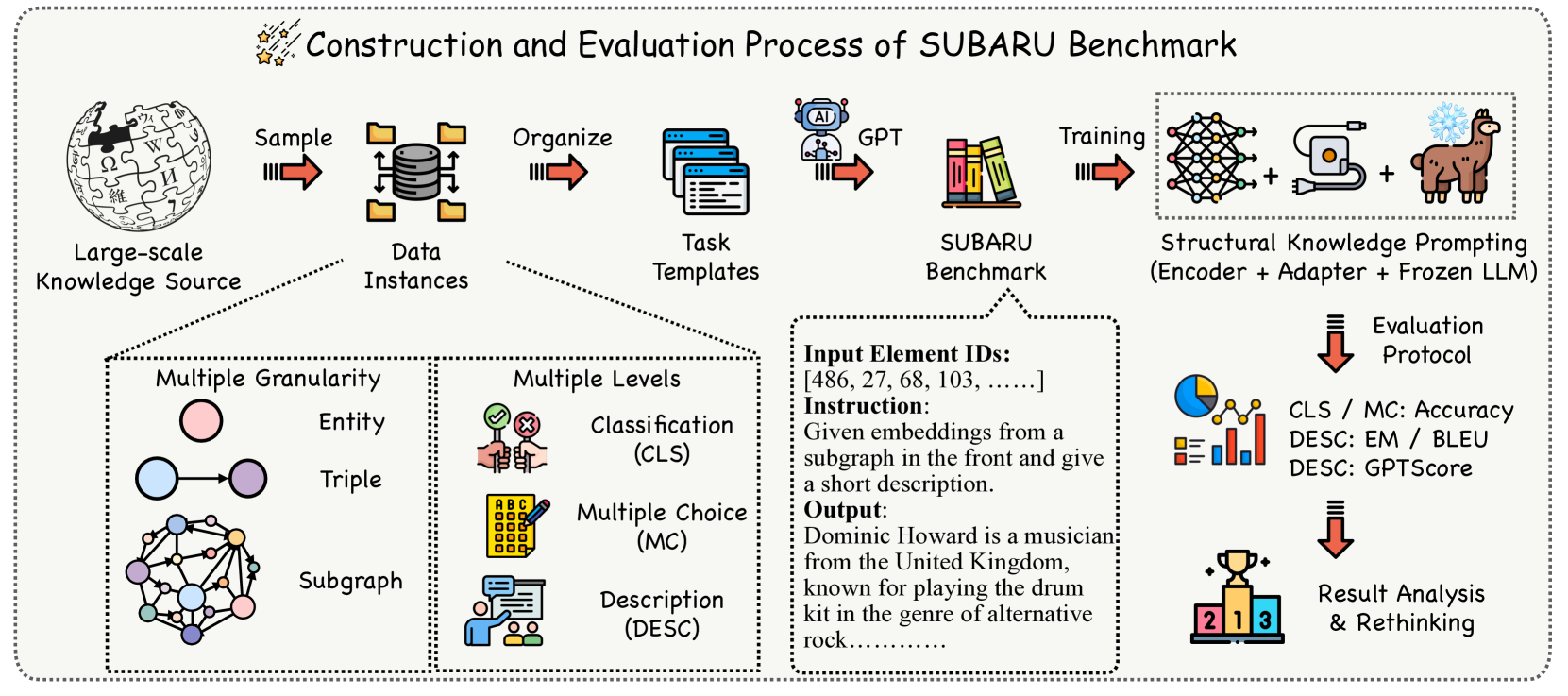
技术框架:论文主要包含以下几个部分:1)定义了评估SKP泛化能力的四个维度;2)构建了SUBARU基准,包含9个不同任务,涵盖不同的知识粒度和难度级别;3)在SUBARU基准上评估了现有的SKP方法;4)分析了实验结果,并提出了改进SKP泛化能力的建议。
关键创新:论文的主要创新点在于:1)提出了一个系统性的框架,用于评估SKP的泛化能力,包括粒度、可迁移性、可扩展性和通用性四个维度;2)构建了一个新的多粒度、多层次基准(SUBARU),用于全面评估SKP的性能。与现有基准相比,SUBARU更加全面和具有挑战性,可以更好地评估SKP的泛化能力。
关键设计:SUBARU基准包含9个不同的知识密集型任务,这些任务涵盖了不同的知识粒度(细粒度、粗粒度)和难度级别。每个任务都包含训练集、验证集和测试集。论文还定义了用于评估SKP性能的指标,例如准确率、召回率和F1值。具体的参数设置和网络结构取决于所评估的SKP方法。
🖼️ 关键图片
📊 实验亮点
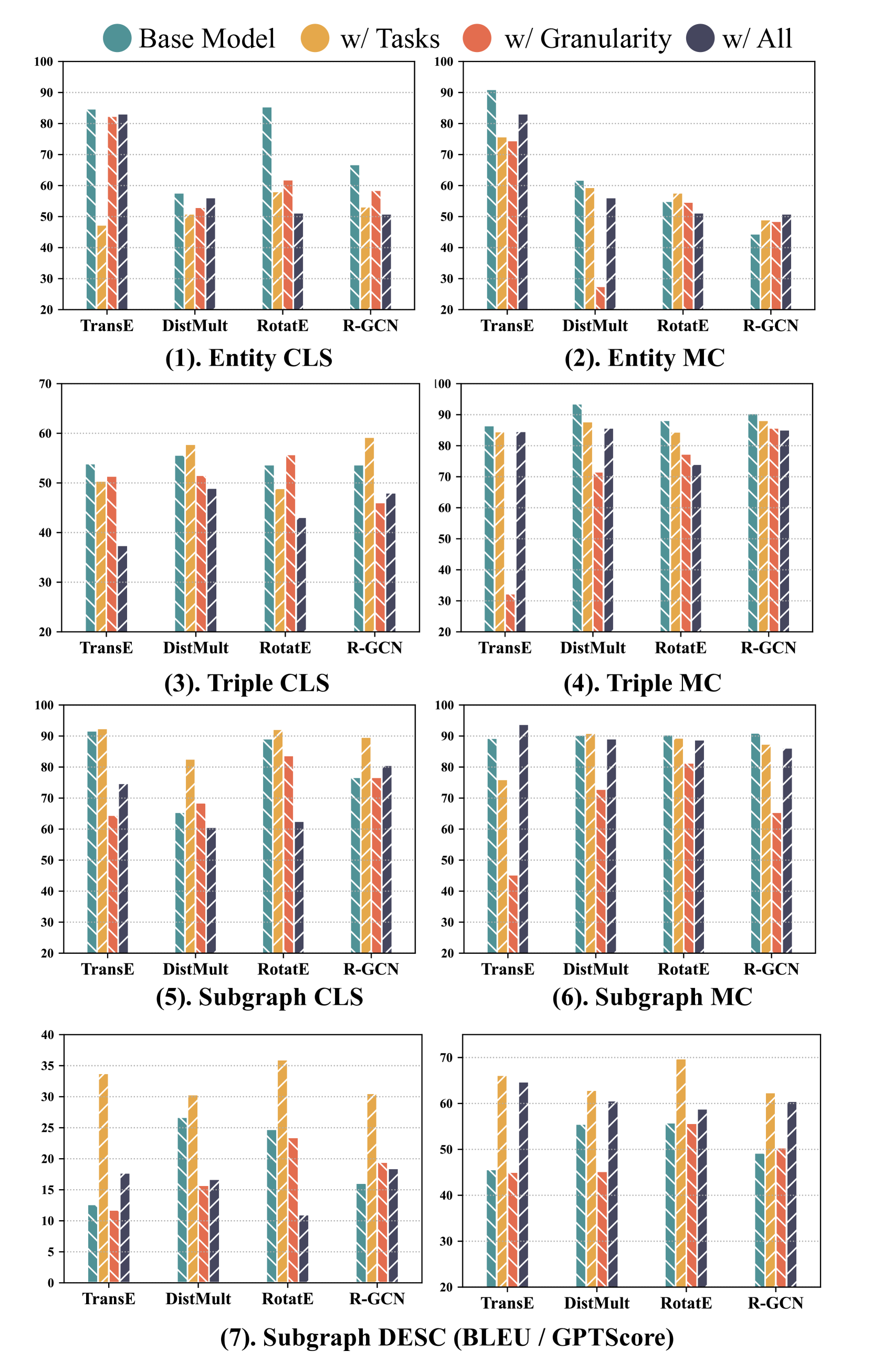
论文构建了SUBARU基准,包含9个不同任务,涵盖不同的知识粒度和难度级别,为全面评估SKP的性能提供了基础。通过在SUBARU上评估现有SKP方法,揭示了它们在泛化能力方面的局限性,并为未来的研究提供了改进方向。具体的性能数据和对比基线需要在论文中查找。
🎯 应用场景
该研究成果可应用于知识密集型任务,例如问答系统、知识图谱补全、文本生成等。通过评估和改进结构化知识提示的泛化能力,可以提高LLMs在这些任务中的性能和可靠性。此外,SUBARU基准可以作为未来研究的平台,促进SKP方法的发展和应用。
📄 摘要(原文)
Large language models (LLMs) have demonstrated exceptional performance in text generation within current NLP research. However, the lack of factual accuracy is still a dark cloud hanging over the LLM skyscraper. Structural knowledge prompting (SKP) is a prominent paradigm to integrate external knowledge into LLMs by incorporating structural representations, achieving state-of-the-art results in many knowledge-intensive tasks. However, existing methods often focus on specific problems, lacking a comprehensive exploration of the generalization and capability boundaries of SKP. This paper aims to evaluate and rethink the generalization capability of the SKP paradigm from four perspectives including Granularity, Transferability, Scalability, and Universality. To provide a thorough evaluation, we introduce a novel multi-granular, multi-level benchmark called SUBARU, consisting of 9 different tasks with varying levels of granularity and difficulty.