Distributed Mixture-of-Agents for Edge Inference with Large Language Models
作者: Purbesh Mitra, Priyanka Kaswan, Sennur Ulukus
分类: cs.IT, cs.CL, cs.DC, cs.LG, cs.NI
发布日期: 2024-12-30
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于分布式混合Agent的边缘LLM推理框架,提升推理质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分布式计算 边缘推理 大型语言模型 混合Agent Gossip算法
📋 核心要点
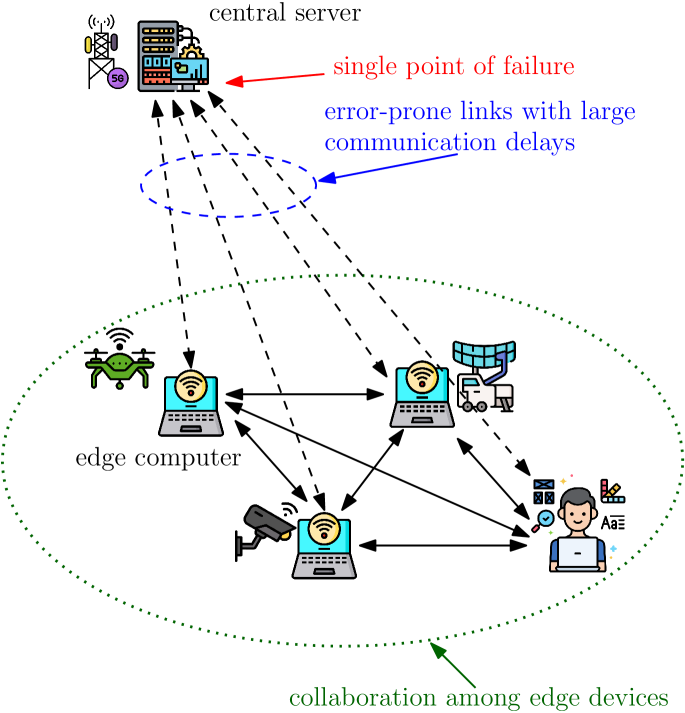
- 现有LLM推理依赖单模型,效果受限;边缘设备算力分散,缺乏有效协同。
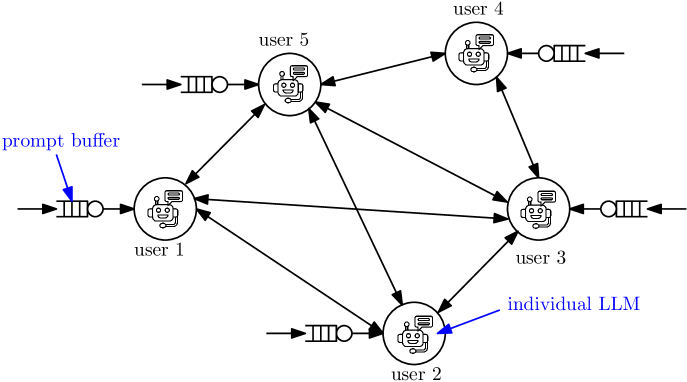
- 提出分布式MoA架构,利用Gossip算法实现边缘设备间LLM的协同推理。
- 理论分析队列稳定性,实验验证MoA配置对推理质量的影响,并在AlpacaEval 2.0上评估。
📝 摘要(中文)
本文提出了一种分布式混合Agent(MoA)架构,用于增强大型语言模型(LLM)在边缘设备上的推理性能。该架构允许多个LLM协同工作,从而改进用户提示的响应质量。每个边缘设备都与一个用户关联,并拥有独立的计算能力。设备之间通过去中心化的Gossip算法交换信息,无需中央服务器的监督。用户提示及其增强版本被临时存储在设备队列中。考虑到边缘设备的内存限制,论文理论分析了设备队列的排队稳定性条件,并通过实验验证。实验结果表明,某些MoA配置在AlpacaEval 2.0基准测试中表现出更高的响应质量。代码已开源。
🔬 方法详解
问题定义:论文旨在解决边缘设备上LLM推理质量不高的问题。现有方法通常依赖单个LLM,无法充分利用边缘设备分散的计算资源。此外,边缘设备的内存有限,需要保证队列的稳定性,避免因提示过多而崩溃。
核心思路:论文的核心思路是利用分布式混合Agent(MoA)架构,允许多个LLM在边缘设备上协同工作。通过Gossip算法,设备可以交换用户提示或增强提示,从而生成更精确的答案。这种协同方式可以有效提升推理质量,并充分利用边缘设备的计算资源。
技术框架:整体架构包括多个边缘设备,每个设备运行一个LLM。用户向设备发送提示,设备将提示放入队列中等待处理。设备之间通过Gossip算法交换提示或增强提示。每个设备根据接收到的提示生成响应,并将响应返回给用户。论文还分析了队列的稳定性条件,以确保系统能够正常运行。
关键创新:最重要的技术创新点在于将MoA架构应用于分布式边缘计算环境。通过Gossip算法实现设备间的去中心化协同,无需中央服务器的监督。此外,论文还提出了队列稳定性分析方法,为系统设计提供了理论依据。
关键设计:论文的关键设计包括Gossip算法的选择、提示增强策略、以及队列管理策略。Gossip算法需要保证信息能够快速传播到整个网络。提示增强策略需要生成高质量的增强提示,以提升推理质量。队列管理策略需要保证队列的稳定性,避免因提示过多而崩溃。具体的参数设置和损失函数等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,某些MoA配置在AlpacaEval 2.0基准测试中表现出更高的响应质量。具体性能数据和提升幅度在摘要中未明确给出,属于未知信息。论文开源了代码,方便其他研究者复现和改进。
🎯 应用场景
该研究成果可应用于智能家居、自动驾驶、物联网等领域。通过在边缘设备上部署分布式MoA架构,可以提升LLM推理的效率和质量,从而为用户提供更智能、更个性化的服务。例如,在智能家居中,多个设备可以协同工作,共同理解用户的意图,并提供更精准的控制和建议。
📄 摘要(原文)
Mixture-of-Agents (MoA) has recently been proposed as a method to enhance performance of large language models (LLMs), enabling multiple individual LLMs to work together for collaborative inference. This collaborative approach results in improved responses to user prompts compared to relying on a single LLM. In this paper, we consider such an MoA architecture in a distributed setting, where LLMs operate on individual edge devices, each uniquely associated with a user and equipped with its own distributed computing power. These devices exchange information using decentralized gossip algorithms, allowing different device nodes to talk without the supervision of a centralized server. In the considered setup, different users have their own LLM models to address user prompts. Additionally, the devices gossip either their own user-specific prompts or augmented prompts to generate more refined answers to certain queries. User prompts are temporarily stored in the device queues when their corresponding LLMs are busy. Given the memory limitations of edge devices, it is crucial to ensure that the average queue sizes in the system remain bounded. In this paper, we address this by theoretically calculating the queuing stability conditions for the device queues under reasonable assumptions, which we validate experimentally as well. Further, we demonstrate through experiments, leveraging open-source LLMs for the implementation of distributed MoA, that certain MoA configurations produce higher-quality responses compared to others, as evaluated on AlpacaEval 2.0 benchmark. The implementation is available at: https://github.com/purbeshmitra/distributed_moa.