Facilitating large language model Russian adaptation with Learned Embedding Propagation
作者: Mikhail Tikhomirov, Daniil Chernyshev
分类: cs.CL, cs.AI
发布日期: 2024-12-30
备注: Preprint version of an article published in the Journal of Language and Education. Copyright held by the owner/author(s). Publication rights licensed to the Journal of Language and Education
💡 一句话要点
提出LEP方法,通过学习嵌入传播实现大语言模型俄语高效适配,无需指令微调。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 语言适配 俄语 嵌入传播 低资源语言 指令微调 词汇扩展
📋 核心要点
- 现有开源LLM俄语适配依赖指令微调,成本高昂且数据需求大,限制了其在资源受限场景的应用。
- 论文提出学习嵌入传播(LEP)方法,通过直接将新语言知识植入现有指令调优模型,避免了耗时的指令微调。
- 实验表明,LEP在俄语适配上可与传统指令微调方法媲美,且通过自校准和持续调优可进一步提升性能。
📝 摘要(中文)
大型语言模型(LLM)技术的快速发展催生了强大的开源指令调优LLM,其文本生成质量与GPT-4等最先进的模型相当。虽然这些模型的出现加速了LLM技术在敏感信息环境中的应用,但其作者并未公开用于复现结果的训练数据,使得这些成果具有模型专属性。由于这些开源模型也是多语言的,这反过来降低了训练特定语言LLM的益处,因为提高推理计算效率成为这种代价高昂的程序唯一有保证的优势。词汇扩展和后续持续预训练等更具成本效益的选择也受到缺乏高质量指令调优数据的限制,因为这是LLM解决任务能力的主要因素。为了解决这些限制并降低语言适配流程的成本,我们提出了学习嵌入传播(LEP)。与现有方法不同,我们的方法对训练数据规模的要求较低,因为它对现有LLM知识的影响最小,我们使用新颖的临时嵌入传播程序来加强这些知识,该程序允许跳过指令调优步骤,而是将新的语言知识直接植入到任何现有的指令调优变体中。我们评估了LLaMa-3-8B和Mistral-7B的四种俄语词汇适配,表明LEP与传统的指令调优方法相比具有竞争力,实现了与OpenChat 3.5和LLaMa-3-8B-Instruct相当的性能,并通过自校准和持续调优进一步提高了任务解决能力。
🔬 方法详解
问题定义:现有的大型语言模型俄语适配方法,如指令微调,需要大量的训练数据和计算资源,成本高昂。同时,由于缺乏高质量的俄语指令调优数据,使得适配效果难以保证。现有方法的痛点在于数据依赖性强,训练成本高,且难以充分利用现有模型的知识。
核心思路:论文的核心思路是通过学习嵌入传播(Learned Embedding Propagation, LEP)的方式,将新的语言知识(例如俄语词汇)直接注入到预训练好的大型语言模型中,而无需进行大规模的指令微调。这样可以显著降低训练成本,并充分利用现有模型的知识。
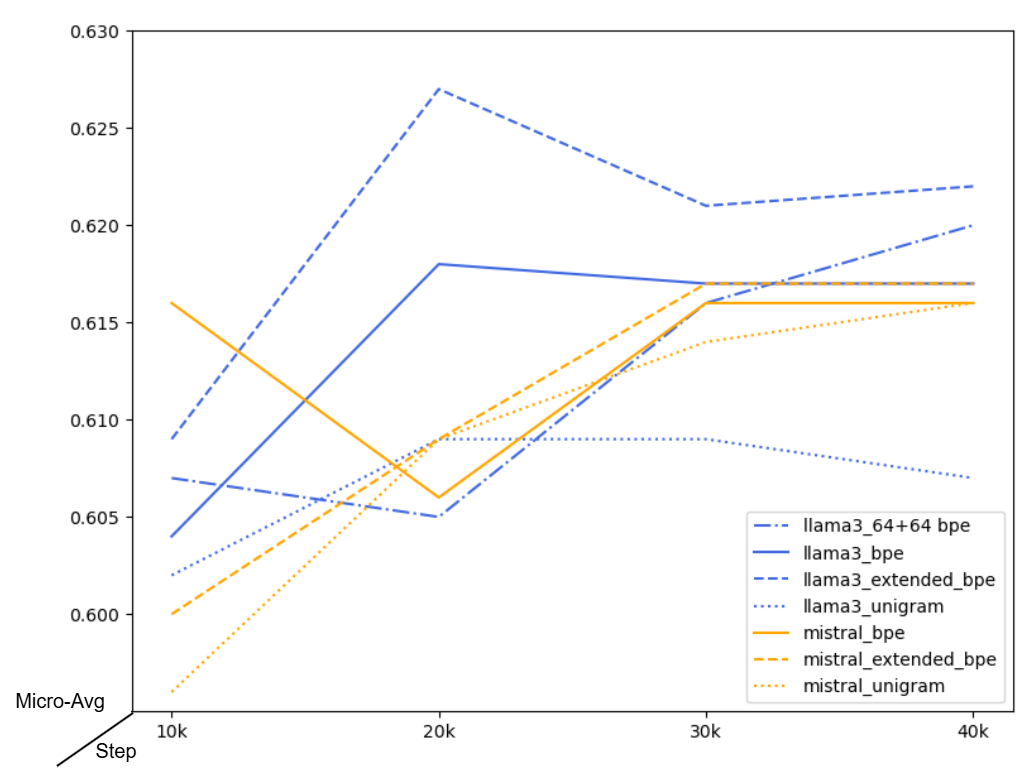
技术框架:LEP方法主要包含以下几个阶段:1) 词汇扩展:将新的俄语词汇添加到现有模型的词汇表中。2) 嵌入学习:学习新词汇的嵌入表示,使其与现有词汇的嵌入空间对齐。3) 嵌入传播:将学习到的新词汇嵌入传播到模型的其他层,以更新模型的知识。4) (可选) 自校准和持续调优:使用少量数据对模型进行微调,以进一步提升性能。
关键创新:LEP方法的关键创新在于其嵌入传播机制,它允许将新语言知识直接注入到现有模型中,而无需进行大规模的指令微调。与传统的指令微调方法相比,LEP方法的数据需求更低,训练成本更低,且能够更好地利用现有模型的知识。此外,LEP方法还引入了自校准和持续调优机制,以进一步提升模型的性能。
关键设计:LEP方法的关键设计包括:1) 嵌入学习的目标函数,用于学习新词汇的嵌入表示。2) 嵌入传播的策略,用于将学习到的嵌入传播到模型的其他层。3) 自校准和持续调优的数据选择和训练策略。具体参数设置和网络结构细节在论文中可能有所描述,但摘要中未明确提及。
🖼️ 关键图片

📊 实验亮点
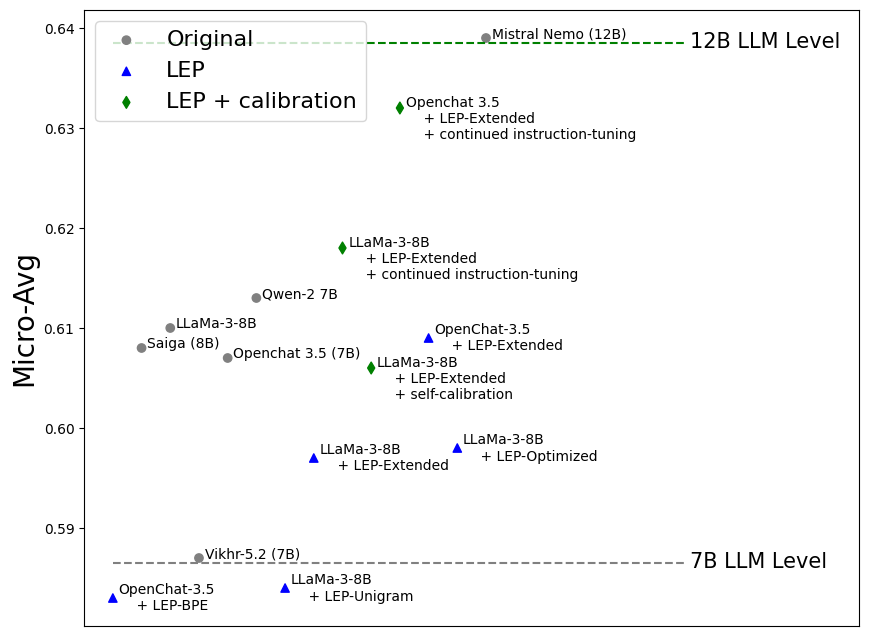
实验结果表明,LEP方法在LLaMa-3-8B和Mistral-7B模型上的俄语适配效果与传统的指令微调方法相当,甚至可以达到OpenChat 3.5和LLaMa-3-8B-Instruct的性能水平。通过自校准和持续调优,LEP方法的性能还可以进一步提升,表明其在低资源语言适配方面具有显著优势。
🎯 应用场景
该研究成果可应用于低资源语言的大型语言模型快速适配,降低多语言模型开发的成本和门槛。尤其适用于对计算资源和数据量有严格限制的场景,例如边缘计算设备上的多语言应用,以及快速构建特定领域的小语种模型。
📄 摘要(原文)
Rapid advancements of large language model (LLM) technologies led to the introduction of powerful open-source instruction-tuned LLMs that have the same text generation quality as the state-of-the-art counterparts such as GPT-4. While the emergence of such models accelerates the adoption of LLM technologies in sensitive-information environments the authors of such models don not disclose the training data necessary for replication of the results thus making the achievements model-exclusive. Since those open-source models are also multilingual this in turn reduces the benefits of training a language specific LLMs as improved inference computation efficiency becomes the only guaranteed advantage of such costly procedure. More cost-efficient options such as vocabulary extension and subsequent continued pre-training are also inhibited by the lack of access to high-quality instruction-tuning data since it is the major factor behind the resulting LLM task-solving capabilities. To address the limitations and cut the costs of the language adaptation pipeline we propose Learned Embedding Propagation (LEP). Unlike existing approaches our method has lower training data size requirements due to minimal impact on existing LLM knowledge which we reinforce using novel ad-hoc embedding propagation procedure that allows to skip the instruction-tuning step and instead implant the new language knowledge directly into any existing instruct-tuned variant. We evaluated four Russian vocabulary adaptations for LLaMa-3-8B and Mistral-7B, showing that LEP is competitive with traditional instruction-tuning methods, achieving performance comparable to OpenChat 3.5 and LLaMa-3-8B-Instruct, with further improvements via self-calibration and continued tuning enhancing task-solving capabilities.