Verbosity-Aware Rationale Reduction: Effective Reduction of Redundant Rationale via Principled Criteria
作者: Joonwon Jang, Jaehee Kim, Wonbin Kweon, Seonghyeon Lee, Hwanjo Yu
分类: cs.CL, cs.AI
发布日期: 2024-12-30 (更新: 2025-06-04)
备注: ACL 2025 FINDINGS
💡 一句话要点
提出基于冗余度的句子级推理精简框架,有效降低大语言模型推理成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理精简 冗余度 句子级别 似然性 推理成本 自然语言处理
📋 核心要点
- 现有token级推理精简方法缺乏明确标准,导致性能下降,无法有效降低LLM推理成本。
- 提出基于冗余度的句子级推理精简框架,选择性移除冗余推理句,保留推理能力。
- 实验结果表明,该方法在降低token生成量的同时,显著提升了模型在推理任务上的性能。
📝 摘要(中文)
大型语言模型(LLMs)依赖于生成大量的中间推理单元(例如,tokens,句子)来提高各种复杂任务的最终答案质量。虽然这种方法已被证明是有效的,但它不可避免地增加了大量的推理成本。先前采用token级别精简的方法,由于缺乏明确的标准,导致与使用完整推理训练的模型相比,性能较差。为了解决这个挑战,我们提出了一种新颖的句子级别推理精简框架,该框架利用基于似然性的标准,即冗余度,来识别和删除冗余的推理句子。与以往的方法不同,我们的方法利用冗余度来选择性地删除冗余的推理句子,同时保留推理能力。我们在各种推理任务上的实验结果表明,与使用完整推理路径训练的模型相比,我们的方法在减少19.87%的token生成的同时,性能平均提高了7.71%。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在推理过程中生成大量冗余信息,导致推理成本过高的问题。现有的token级别的精简方法缺乏明确的标准,容易删除关键信息,导致性能下降,无法在降低推理成本的同时保证模型性能。
核心思路:论文的核心思路是基于句子的冗余度进行推理精简。通过识别并删除冗余的推理句子,可以在减少token生成量的同时,保留关键的推理信息,从而在降低推理成本的同时,维持甚至提升模型性能。这种句子级别的精简避免了token级别精简可能造成的关键信息丢失。
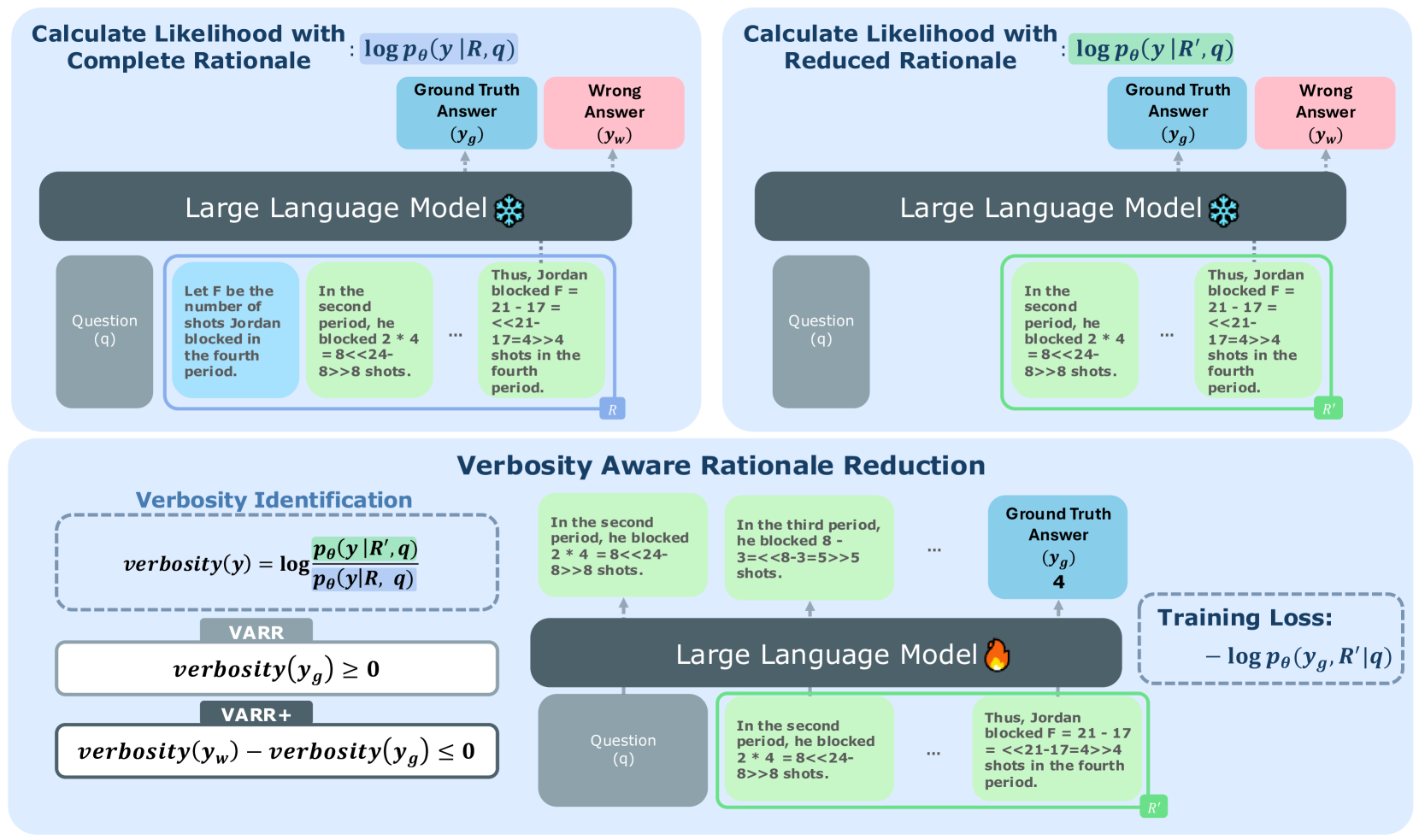
技术框架:该框架主要包含以下几个阶段:1) 使用大型语言模型生成完整的推理路径;2) 利用基于似然性的标准(冗余度)对每个句子进行评估;3) 根据冗余度选择性地删除冗余的推理句子;4) 使用精简后的推理路径进行最终答案的生成。整体流程旨在在保证推理能力的前提下,尽可能地减少推理过程中的冗余信息。
关键创新:论文的关键创新在于提出了基于冗余度的句子级别推理精简方法。与以往的token级别精简方法相比,该方法能够更有效地识别和删除冗余信息,同时保留关键的推理信息。此外,使用基于似然性的标准来衡量句子的冗余度,提供了一种可量化的、可解释的精简标准。
关键设计:论文使用基于似然性的标准来衡量句子的冗余度,具体实现细节未知。关键在于如何定义和计算句子的冗余度,以及如何根据冗余度来选择性地删除句子。此外,如何平衡推理成本和模型性能,也是一个重要的设计考虑因素。具体的损失函数和网络结构等技术细节在摘要中没有提及,属于未知信息。
🖼️ 关键图片
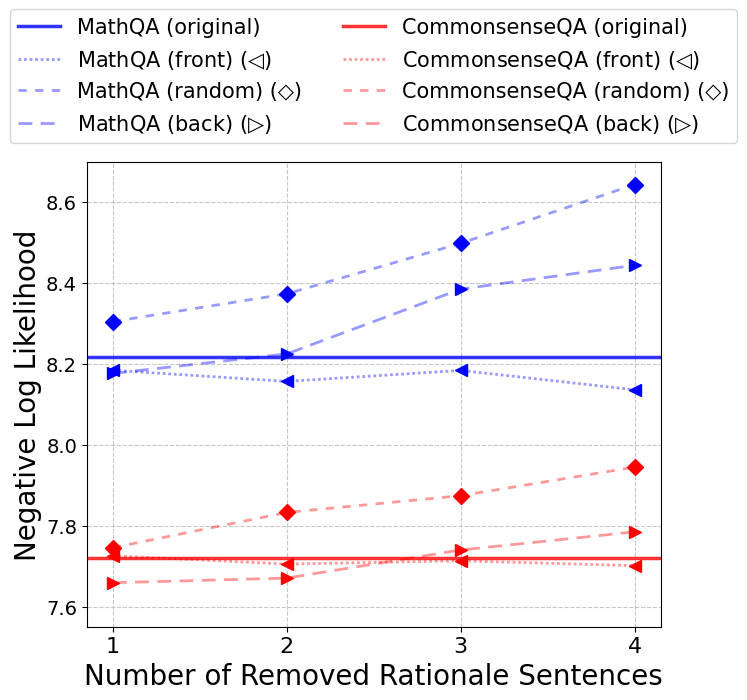

📊 实验亮点
实验结果表明,该方法在各种推理任务上,与使用完整推理路径训练的模型相比,在减少19.87%的token生成的同时,性能平均提高了7.71%。这表明该方法能够在显著降低推理成本的同时,有效提升模型性能,优于以往的token级别精简方法。
🎯 应用场景
该研究成果可应用于各种需要进行复杂推理的任务中,例如问答系统、自然语言推理、知识图谱推理等。通过降低LLM的推理成本,可以使其在资源受限的环境中得到更广泛的应用,并加速LLM在实际场景中的部署。此外,该方法还可以用于提高LLM的可解释性,通过精简推理路径,更容易理解模型的推理过程。
📄 摘要(原文)
Large Language Models (LLMs) rely on generating extensive intermediate reasoning units (e.g., tokens, sentences) to enhance final answer quality across a wide range of complex tasks. While this approach has proven effective, it inevitably increases substantial inference costs. Previous methods adopting token-level reduction without clear criteria result in poor performance compared to models trained with complete rationale. To address this challenge, we propose a novel sentence-level rationale reduction framework leveraging likelihood-based criteria, verbosity, to identify and remove redundant reasoning sentences. Unlike previous approaches, our method leverages verbosity to selectively remove redundant reasoning sentences while preserving reasoning capabilities. Our experimental results across various reasoning tasks demonstrate that our method improves performance by an average of 7.71% while reducing token generation by 19.87% compared to model trained with complete reasoning paths.