ICLR: In-Context Learning of Representations
作者: Core Francisco Park, Andrew Lee, Ekdeep Singh Lubana, Yongyi Yang, Maya Okawa, Kento Nishi, Martin Wattenberg, Hidenori Tanaka
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-12-29 (更新: 2025-05-02)
备注: ICLR 2025
期刊: International Conference on Learning Representations, 2025
💡 一句话要点
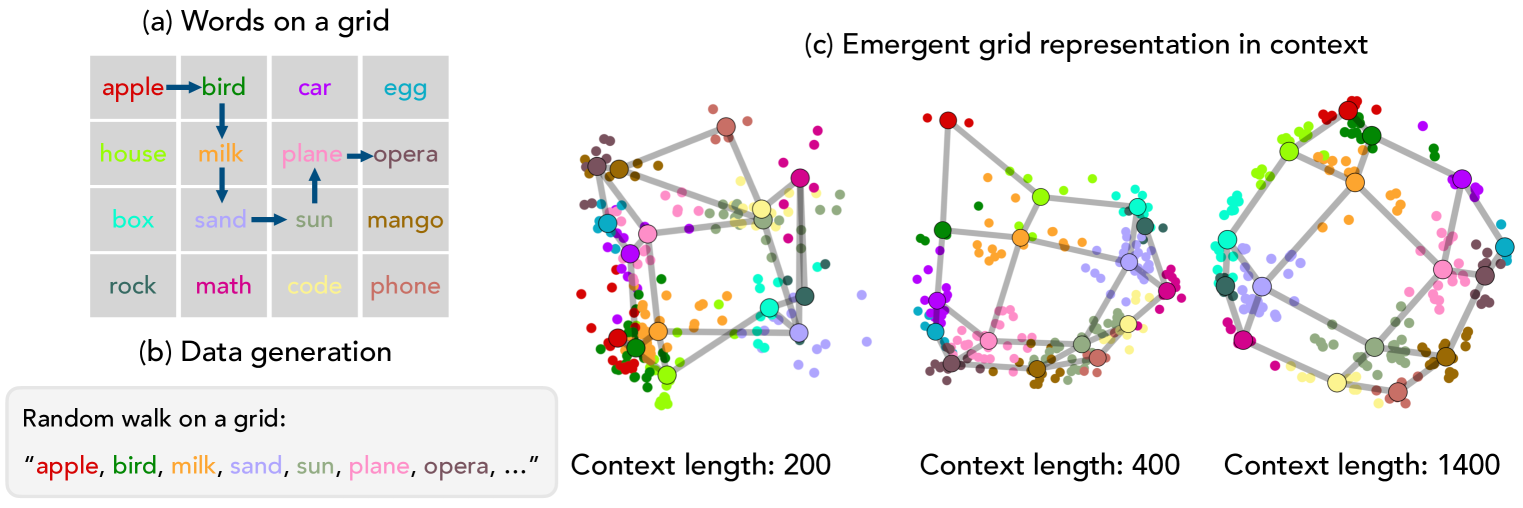
研究表明,上下文学习能使LLM重组表征,以适应新的语义角色。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 表征学习 大型语言模型 语义表示 图神经网络
📋 核心要点
- 大型语言模型(LLM)的表征方式受预训练数据语义的影响,但其在特定上下文中的适应性仍待研究。
- 论文提出通过图追踪任务,探究LLM是否能根据上下文示例重组其内部表征,以适应新的语义角色。
- 实验表明,随着上下文规模的扩大,LLM的表征会从预训练语义向上下文指定的图结构对齐,但语义相关概念会减弱这种重组。
📝 摘要(中文)
最近的研究表明,预训练数据所指定的语义会影响大型语言模型(LLM)中不同概念的表征组织方式。然而,考虑到LLM的开放性,例如其上下文学习能力,我们可以探究模型是否会改变这些预训练语义,转而采用由上下文指定的替代语义。具体来说,如果我们提供上下文示例,其中一个概念扮演的角色与预训练数据所暗示的不同,模型是否会根据这些新的语义重新组织其表征?为了回答这个问题,我们从概念角色语义理论中获得灵感,并定义了一个玩具“图追踪”任务,其中图的节点通过训练期间看到的(例如,苹果、鸟等)概念来引用,图的连通性通过一些预定义的结构(例如,正方形网格)来定义。给定指示图上随机游走的示例,我们分析模型的中间表征,发现随着上下文规模的扩大,会发生从预训练语义表征到与图结构对齐的上下文表征的突然重组。此外,我们发现当引用概念在其语义中具有相关性(例如,星期一、星期二等)时,上下文指定的图结构仍然存在于表征中,但无法主导预训练结构。为了解释这些结果,我们将我们的任务类比于预定义图拓扑的能量最小化,为推断上下文指定语义的隐式优化过程提供证据。总的来说,我们的发现表明,扩展上下文大小可以灵活地重新组织模型表征,可能解锁新的能力。
🔬 方法详解
问题定义:现有大型语言模型(LLM)的表征方式主要由预训练数据决定,缺乏对特定上下文的灵活适应性。现有方法难以探究LLM在特定上下文中如何调整其内部表征,以适应新的语义角色。
核心思路:论文的核心思路是利用上下文学习能力,通过提供特定的上下文示例,引导LLM学习新的概念关系。通过分析LLM的中间层表征,观察其如何从预训练语义向上下文指定的语义转变。这种方法借鉴了概念角色语义理论,将概念的意义定义为其在特定上下文中的角色。
技术框架:论文构建了一个“图追踪”任务,作为探究LLM上下文学习表征的实验平台。该任务包含以下几个主要步骤:1. 定义一个图结构(例如,正方形网格),图的节点用常见的概念(例如,苹果、鸟)来表示。2. 生成图上的随机游走轨迹,作为上下文示例。3. 将上下文示例输入LLM,并提取其中间层表征。4. 分析中间层表征,观察其与预训练语义和上下文指定的图结构之间的关系。
关键创新:论文的关键创新在于将上下文学习与表征分析相结合,提供了一种研究LLM内部表征如何适应新语义角色的方法。通过图追踪任务,能够定量地分析LLM的表征重组过程,并揭示上下文规模对表征的影响。此外,论文还发现语义相关的概念会影响表征的重组,为理解LLM的语义表示提供了新的视角。
关键设计:图追踪任务的关键设计包括:1. 图结构的选取:选择简单的图结构(如正方形网格)便于分析。2. 概念的选择:选择LLM在预训练期间见过的概念,以避免引入新的词汇。3. 上下文规模的控制:通过调整上下文示例的数量,研究上下文规模对表征重组的影响。4. 表征分析方法:使用线性探针等方法,分析中间层表征与预训练语义和图结构之间的关系。
🖼️ 关键图片


📊 实验亮点
实验结果表明,随着上下文规模的扩大,LLM的表征会发生显著的重组,从预训练语义向上下文指定的图结构对齐。当上下文示例足够多时,LLM能够有效地学习新的概念关系,并将其融入到内部表征中。然而,语义相关的概念会减弱这种重组,表明预训练语义仍然对LLM的表征产生影响。这些发现为理解LLM的上下文学习能力提供了重要的证据。
🎯 应用场景
该研究成果可应用于提升LLM在特定领域的适应性和泛化能力。例如,在知识图谱推理、对话系统和机器人控制等领域,可以通过上下文学习引导LLM学习新的概念关系和任务规则,从而提高其性能和鲁棒性。此外,该研究也有助于理解LLM的内部工作机制,为开发更高效、更可控的LLM提供理论基础。
📄 摘要(原文)
Recent work has demonstrated that semantics specified by pretraining data influence how representations of different concepts are organized in a large language model (LLM). However, given the open-ended nature of LLMs, e.g., their ability to in-context learn, we can ask whether models alter these pretraining semantics to adopt alternative, context-specified ones. Specifically, if we provide in-context exemplars wherein a concept plays a different role than what the pretraining data suggests, do models reorganize their representations in accordance with these novel semantics? To answer this question, we take inspiration from the theory of conceptual role semantics and define a toy "graph tracing" task wherein the nodes of the graph are referenced via concepts seen during training (e.g., apple, bird, etc.) and the connectivity of the graph is defined via some predefined structure (e.g., a square grid). Given exemplars that indicate traces of random walks on the graph, we analyze intermediate representations of the model and find that as the amount of context is scaled, there is a sudden re-organization from pretrained semantic representations to in-context representations aligned with the graph structure. Further, we find that when reference concepts have correlations in their semantics (e.g., Monday, Tuesday, etc.), the context-specified graph structure is still present in the representations, but is unable to dominate the pretrained structure. To explain these results, we analogize our task to energy minimization for a predefined graph topology, providing evidence towards an implicit optimization process to infer context-specified semantics. Overall, our findings indicate scaling context-size can flexibly re-organize model representations, possibly unlocking novel capabilities.