The Impact of Prompt Programming on Function-Level Code Generation
作者: Ranim Khojah, Francisco Gomes de Oliveira Neto, Mazen Mohamad, Philipp Leitner
分类: cs.SE, cs.CL, cs.HC, cs.LG
发布日期: 2024-12-29 (更新: 2025-07-08)
备注: Accepted at Transactions on Software Engineering (TSE). CodePromptEval dataset and replication package on GitHub: https://github.com/icetlab/CodePromptEval
💡 一句话要点
CodePromptEval:评估提示工程对函数级代码生成的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 提示工程 大型语言模型 CodePromptEval 函数级代码
📋 核心要点
- 现有大型语言模型在代码生成方面存在局限性,例如生成不相关或不正确的代码,需要有效的提示工程来改善。
- 论文提出CodePromptEval数据集,用于评估五种提示技术及其组合对代码生成的影响,旨在深入理解提示工程的作用。
- 实验结果表明,某些提示技术对代码生成有显著影响,但组合多种技术不一定能提升效果,且正确性和质量之间存在权衡。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地被软件工程师用于代码生成。然而,LLMs的局限性,如生成不相关或不正确的代码,凸显了提示编程(或提示工程)的必要性,即工程师应用特定的提示技术(例如,思维链或输入-输出示例)来改进生成的代码。虽然已经研究了一些提示技术,但不同技术及其相互作用对代码生成的影响仍未完全理解。在本研究中,我们引入了CodePromptEval,一个包含7072个提示的数据集,旨在评估五种提示技术(少样本、角色扮演、思维链、函数签名、包列表)及其对三个LLMs(GPT-4o、Llama3和Mistral)生成的完整函数的正确性、相似性和质量的影响。我们的研究结果表明,虽然某些提示技术显著影响生成的代码,但组合多种技术并不一定能改善结果。此外,我们观察到在使用提示技术时,正确性和质量之间存在权衡。我们的数据集和复现包能够促进未来对改进LLM生成的代码和评估新的提示技术的研究。
🔬 方法详解
问题定义:论文旨在解决如何系统性地评估不同提示工程技术对函数级别代码生成的影响。现有方法缺乏对各种提示技术及其组合效果的深入理解,以及对代码正确性、质量和相似性之间权衡的量化分析。
核心思路:论文的核心思路是通过构建一个包含大量提示的数据集CodePromptEval,并利用该数据集对不同的提示技术进行实验评估。通过分析实验结果,揭示各种提示技术对代码生成的影响,以及它们之间的相互作用。
技术框架:论文的技术框架主要包括以下几个部分:1) 构建CodePromptEval数据集,该数据集包含7072个提示,涵盖五种提示技术(少样本、角色扮演、思维链、函数签名、包列表)及其组合;2) 使用三个大型语言模型(GPT-4o、Llama3和Mistral)对数据集中的提示进行代码生成;3) 对生成的代码进行评估,评估指标包括正确性、相似性和质量;4) 分析实验结果,揭示不同提示技术对代码生成的影响。
关键创新:论文的关键创新在于构建了CodePromptEval数据集,该数据集为研究提示工程对代码生成的影响提供了一个标准化的评估平台。此外,论文还深入分析了不同提示技术及其组合对代码生成的影响,揭示了正确性和质量之间的权衡。
关键设计:CodePromptEval数据集的设计考虑了五种常见的提示技术,并对这些技术进行了组合,以评估它们之间的相互作用。评估指标包括代码的正确性(例如,是否通过单元测试)、相似性(例如,与参考代码的相似度)和质量(例如,代码的可读性和可维护性)。具体参数设置和损失函数等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


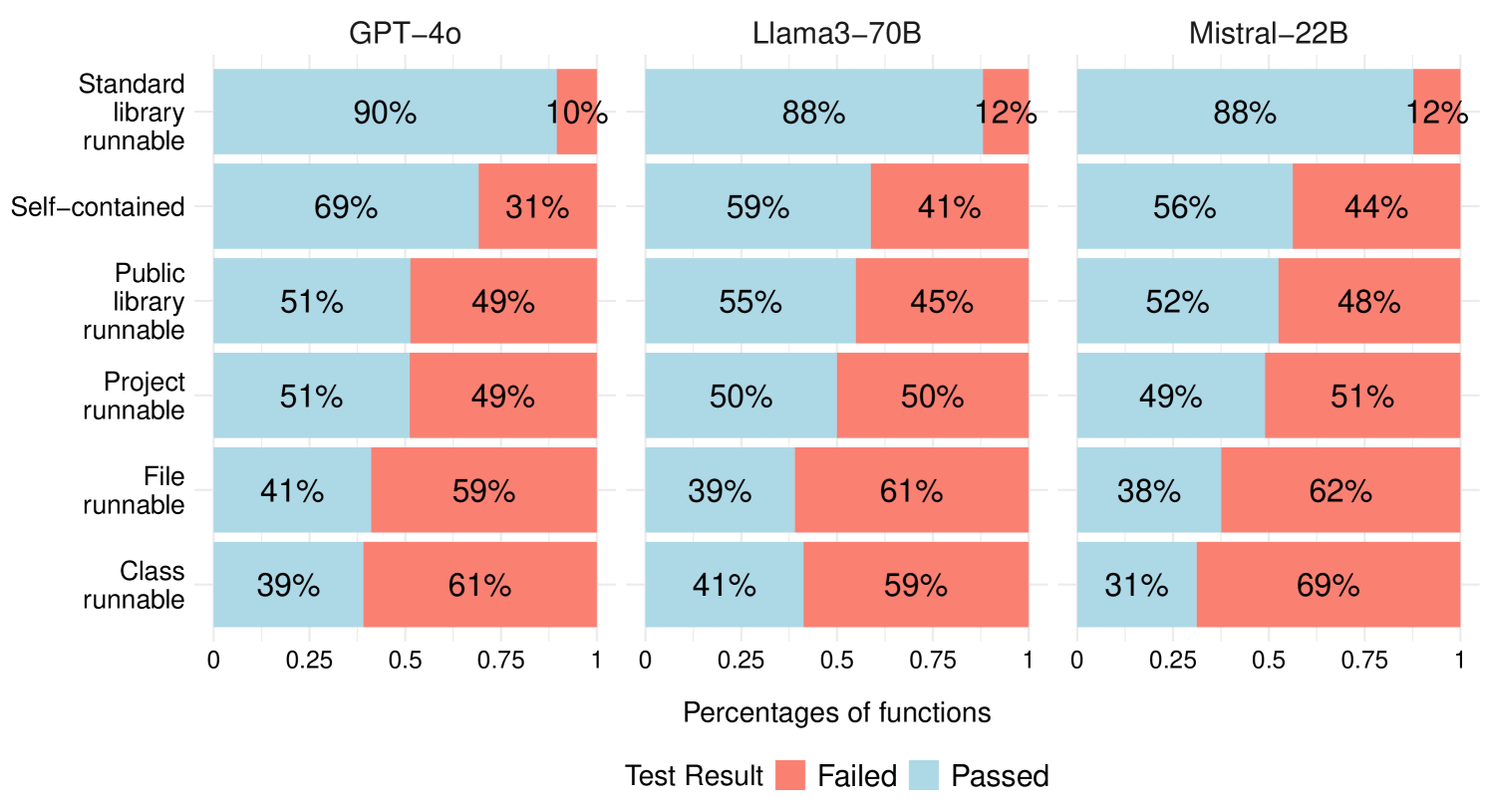
📊 实验亮点
实验结果表明,不同的提示技术对代码生成有显著影响,但组合多种技术并不一定能改善结果。此外,研究发现正确性和质量之间存在权衡,即提高代码正确性的提示技术可能会降低代码的质量,反之亦然。CodePromptEval数据集和复现包的发布为未来的研究提供了便利。
🎯 应用场景
该研究成果可应用于软件开发领域,帮助工程师选择合适的提示技术来提高代码生成的质量和效率。此外,CodePromptEval数据集可以作为评估新的提示技术和改进LLM代码生成能力的基准平台,促进相关研究的进展。该研究还有助于理解LLM在代码生成方面的优势和局限性,为未来的模型设计提供指导。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly used by software engineers for code generation. However, limitations of LLMs such as irrelevant or incorrect code have highlighted the need for prompt programming (or prompt engineering) where engineers apply specific prompt techniques (e.g., chain-of-thought or input-output examples) to improve the generated code. While some prompt techniques have been studied, the impact of different techniques -- and their interactions -- on code generation is still not fully understood. In this study, we introduce CodePromptEval, a dataset of 7072 prompts designed to evaluate five prompt techniques (few-shot, persona, chain-of-thought, function signature, list of packages) and their effect on the correctness, similarity, and quality of complete functions generated by three LLMs (GPT-4o, Llama3, and Mistral). Our findings show that while certain prompt techniques significantly influence the generated code, combining multiple techniques does not necessarily improve the outcome. Additionally, we observed a trade-off between correctness and quality when using prompt techniques. Our dataset and replication package enable future research on improving LLM-generated code and evaluating new prompt techniques.