Utilizing Multimodal Data for Edge Case Robust Call-sign Recognition and Understanding
作者: Alexander Blatt, Dietrich Klakow
分类: cs.CL
发布日期: 2024-12-29
💡 一句话要点
提出多模态呼号命令恢复模型CCR,提升空管场景下呼号识别的边缘情况鲁棒性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 呼号识别 空中交通管制 边缘情况鲁棒性 语音识别 自然语言处理
📋 核心要点
- 空管场景下的呼号识别与理解任务面临噪声录音和录音剪切等边缘情况的挑战,导致传统方法性能下降。
- 论文提出多模态呼号命令恢复模型(CCR),利用多模态数据提升模型在恶劣条件下的鲁棒性。
- 实验表明,CCR模型在边缘情况下性能提升高达15%,并提出了更高效的CallSBERT模型。
📝 摘要(中文)
在基于机器学习的辅助系统中,鲁棒性至关重要,尤其是在空中交通管制(ATC)领域。架构的鲁棒性在边缘情况下尤为明显,例如由嘈杂的ATC录音导致的高词错误率(WER)转录或因录音剪切导致的部分转录。为了提高呼号识别和理解(CRU)的边缘情况鲁棒性,这是ATC语音处理中的核心任务,我们提出了多模态呼号命令恢复模型(CCR)。CCR架构使边缘情况下的性能提高了15%。我们在我们提出的第二个架构CallSBERT上展示了这一点。CallSBERT是一个CRU模型,它具有更少的参数,可以更快地进行微调,并且在微调过程中比最先进的CRU模型更鲁棒。此外,我们证明了针对边缘情况进行优化可以显著提高广泛操作范围内的准确性。
🔬 方法详解
问题定义:论文旨在解决空中交通管制(ATC)场景下,由于噪声、录音剪切等因素导致呼号识别和理解(CRU)任务性能下降的问题。现有方法在处理这些边缘情况时鲁棒性不足,严重影响了实际应用效果。
核心思路:论文的核心思路是利用多模态数据(例如语音和文本)的互补信息,提高模型在恶劣条件下的鲁棒性。即使语音转录质量不高,模型仍然可以利用其他模态的信息进行准确识别。
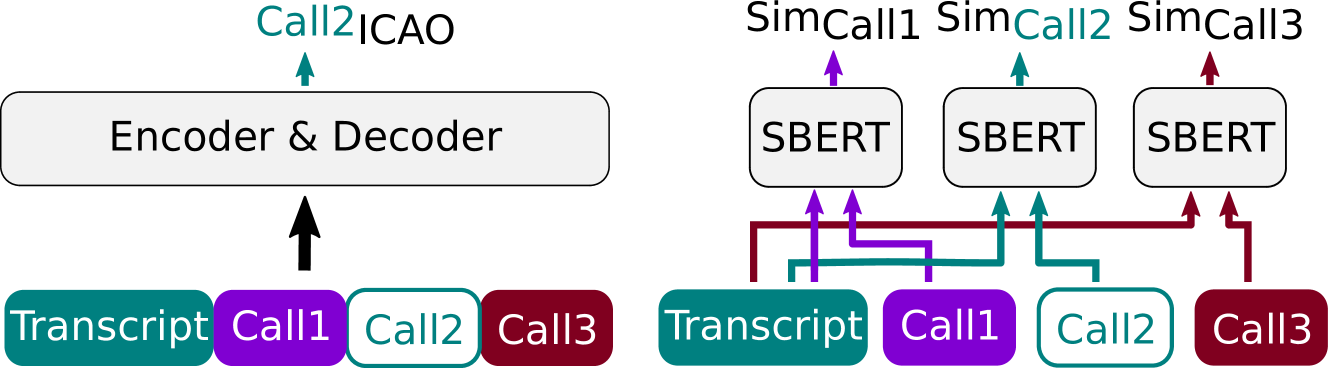
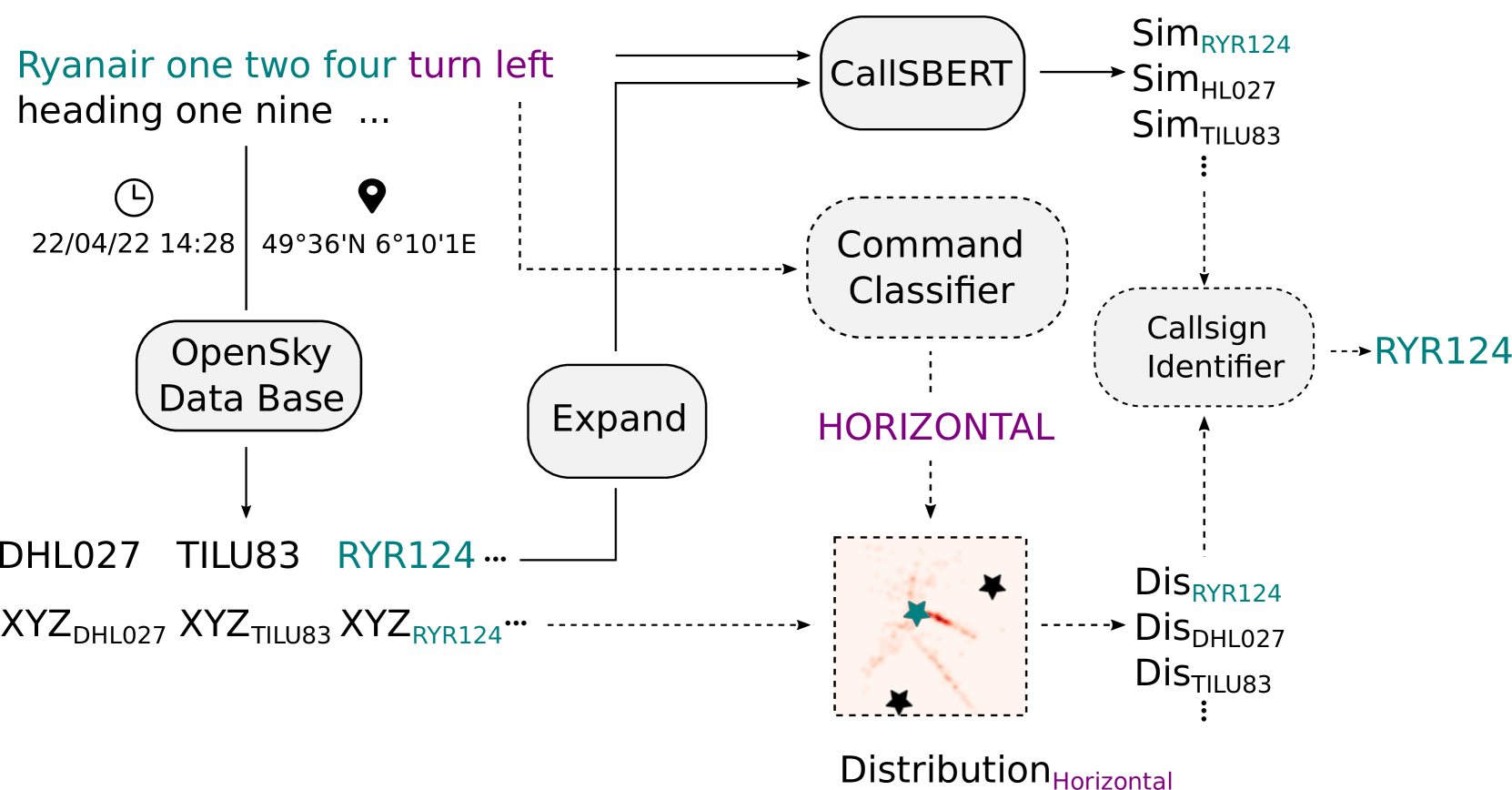
技术框架:论文提出了多模态呼号命令恢复模型(CCR)。该架构包含语音识别模块、文本处理模块和多模态融合模块。语音识别模块负责将语音信号转换为文本,文本处理模块负责提取文本特征,多模态融合模块将语音和文本特征进行融合,最终进行呼号识别和理解。此外,论文还提出了CallSBERT模型,这是一个参数更少、微调速度更快、鲁棒性更强的CRU模型。
关键创新:论文的关键创新在于提出了多模态融合的CCR架构,并针对边缘情况进行了优化。通过融合语音和文本信息,模型可以更好地应对噪声和录音剪切等挑战。此外,CallSBERT模型在参数效率和微调鲁棒性方面也进行了改进。
关键设计:论文中关于多模态融合的具体方法和CallSBERT模型的网络结构等技术细节未详细描述,属于未知信息。损失函数的设计可能侧重于提升模型在边缘情况下的性能,例如,可以采用对抗训练或数据增强等技术来模拟恶劣条件。
🖼️ 关键图片

📊 实验亮点
实验结果表明,所提出的CCR模型在边缘情况下性能提升高达15%。此外,CallSBERT模型在参数量、微调速度和鲁棒性方面均优于现有最先进的CRU模型。实验还证明,针对边缘情况进行优化可以显著提高模型在广泛操作范围内的准确性。
🎯 应用场景
该研究成果可应用于提升空中交通管制系统的智能化水平,提高飞行安全性和效率。通过更准确的呼号识别和理解,可以减少人为错误,优化空域资源分配,并为飞行员提供更可靠的辅助信息。此外,该方法也可推广到其他语音识别和理解任务中,尤其是在噪声环境或数据不完整的情况下。
📄 摘要(原文)
Operational machine-learning based assistant systems must be robust in a wide range of scenarios. This hold especially true for the air-traffic control (ATC) domain. The robustness of an architecture is particularly evident in edge cases, such as high word error rate (WER) transcripts resulting from noisy ATC recordings or partial transcripts due to clipped recordings. To increase the edge-case robustness of call-sign recognition and understanding (CRU), a core tasks in ATC speech processing, we propose the multimodal call-sign-command recovery model (CCR). The CCR architecture leads to an increase in the edge case performance of up to 15%. We demonstrate this on our second proposed architecture, CallSBERT. A CRU model that has less parameters, can be fine-tuned noticeably faster and is more robust during fine-tuning than the state of the art for CRU. Furthermore, we demonstrate that optimizing for edge cases leads to a significantly higher accuracy across a wide operational range.