Natural Language Fine-Tuning
作者: Jia Liu, Yue Wang, Zhiqi Lin, Min Chen, Yixue Hao, Long Hu
分类: cs.CL, cs.AI
发布日期: 2024-12-29
🔗 代码/项目: GITHUB
💡 一句话要点
提出自然语言微调(NLFT),解决小样本特定领域大语言模型微调难题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自然语言微调 小样本学习 大语言模型 token级别优化 特定领域微调
📋 核心要点
- 现有大语言模型微调方法依赖大量标注数据和外部指导,在特定领域小样本场景下表现不佳。
- NLFT利用自然语言指导token级别输出,通过显著性token识别,提升模型在小样本场景下的微调效果。
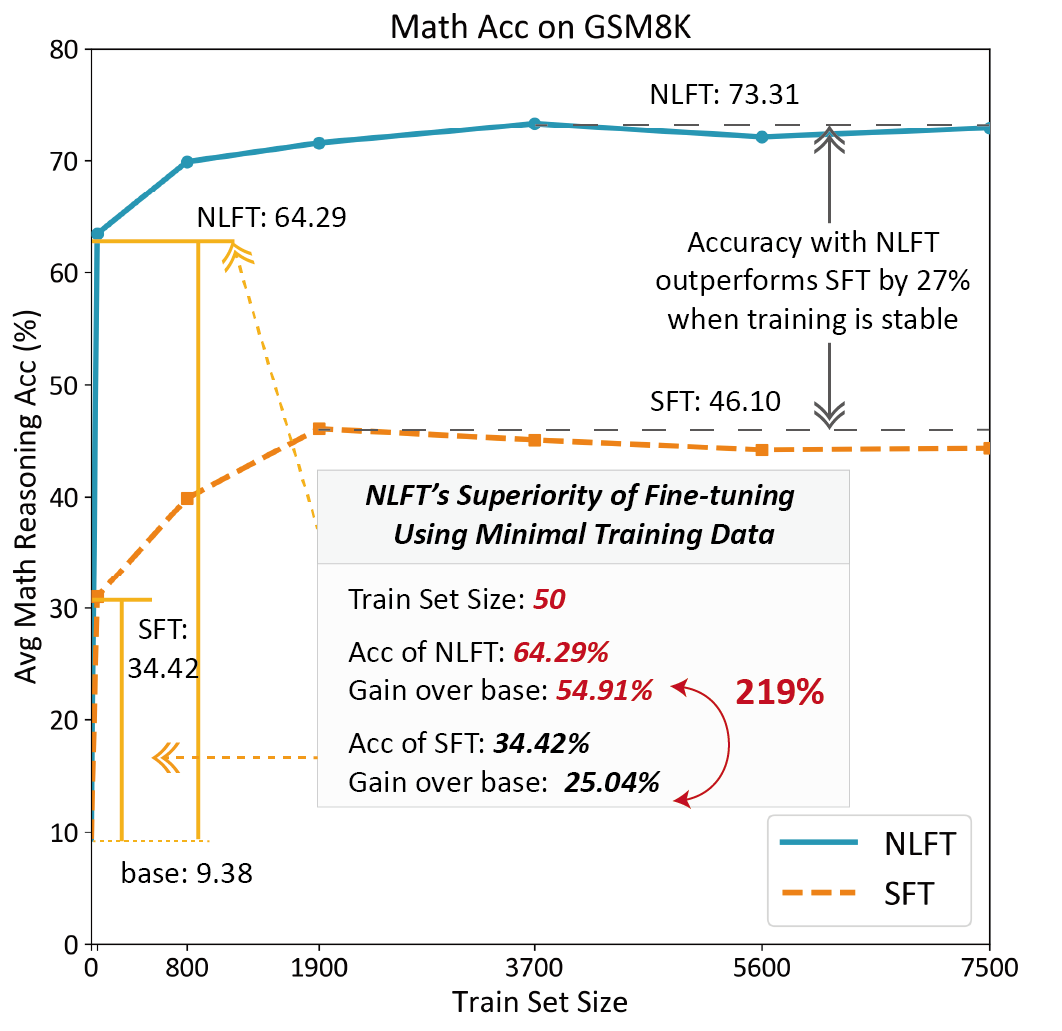
- 实验表明,NLFT在GSM8K数据集上仅用50个样本,准确率提升超过SFT 219%,且显著降低了时间和空间复杂度。
📝 摘要(中文)
大型语言模型微调技术通常依赖于大量的标注数据、外部指导和反馈,例如人工对齐、标量奖励和演示。然而,在实际应用中,特定知识的稀缺性给现有的微调技术带来了前所未有的挑战。本文针对数据有限的特定领域微调任务,首次引入自然语言微调(NLFT),利用自然语言进行微调。通过利用目标语言模型的强大语言理解能力,NLFT将自然语言的指导附加到token级别的输出上。然后,通过计算概率识别显著性token。由于NLFT有效地利用了语言信息,因此我们提出的方法显著降低了训练成本。它显著提高了训练效率,在准确性、节省时间和资源方面全面优于强化微调算法。此外,在宏观层面上,NLFT可以被视为SFT的token级别细粒度优化,从而有效地取代SFT过程,而无需预热(与ReFT需要多轮SFT预热相反)。与SFT相比,NLFT不增加算法复杂度,保持O(n)。在GSM8K数据集上的大量实验表明,NLFT仅使用50个数据实例,其准确率提升超过SFT 219%。与ReFT相比,NLFT的时间复杂度和空间复杂度分别降低了78.27%和92.24%。NLFT的卓越技术为在网络边缘资源有限的情况下部署各种创新的LLM微调应用铺平了道路。
🔬 方法详解
问题定义:论文旨在解决特定领域内,当标注数据极度稀缺时,如何高效地微调大型语言模型的问题。现有微调方法,如SFT和ReFT,在小样本场景下要么效果不佳,要么需要大量的计算资源和预热步骤,难以满足实际应用需求。
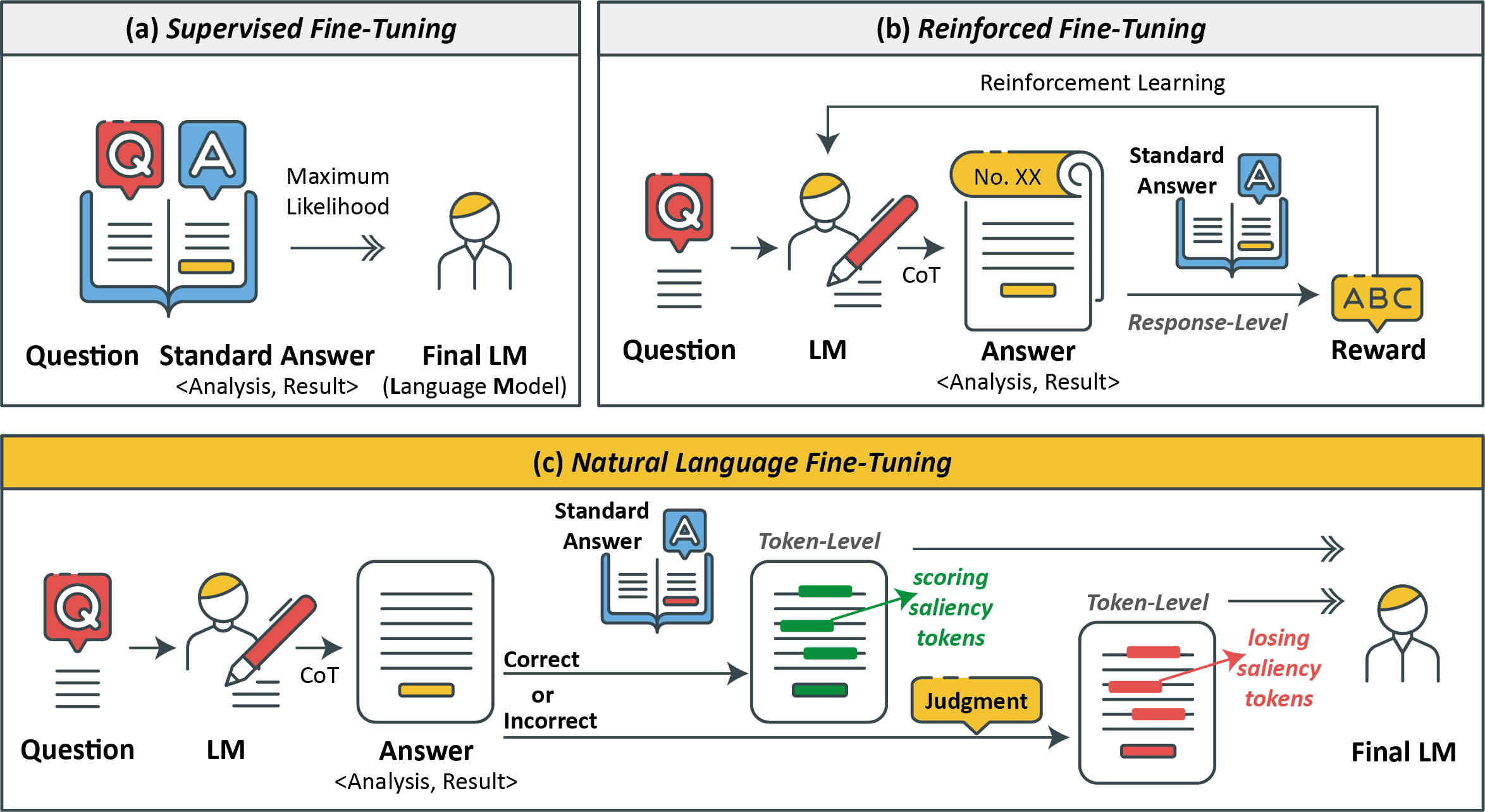
核心思路:NLFT的核心思路是利用自然语言的表达能力,将领域知识和指导信息融入到token级别的输出中。通过让模型学习自然语言的指导,可以更有效地利用有限的数据,并提升模型在特定任务上的性能。这种方法类似于人类学习,通过阅读指导手册或听取专家建议来快速掌握新技能。
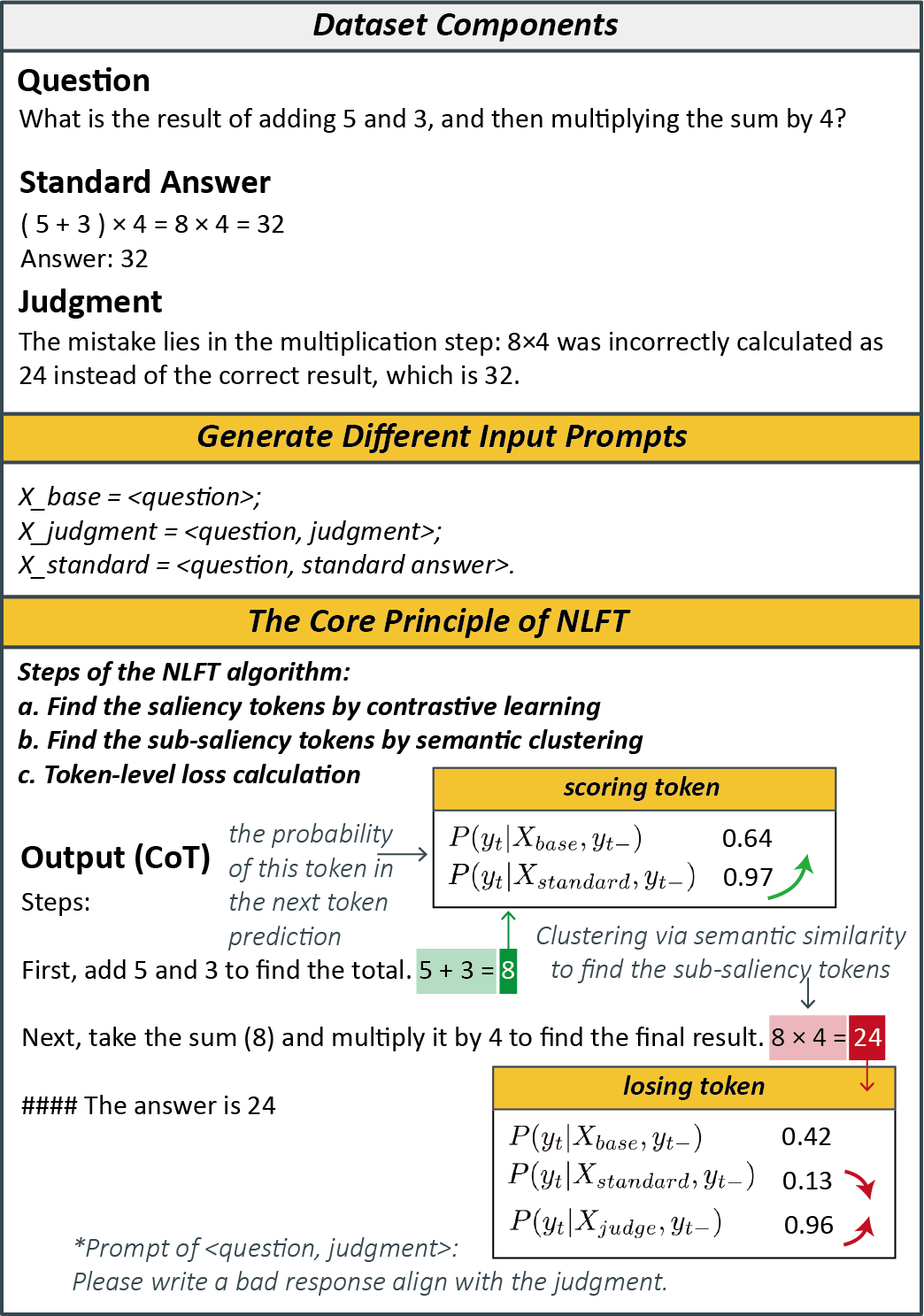
技术框架:NLFT的整体框架包括以下几个主要步骤:1) 自然语言指导生成:为每个训练样本生成相应的自然语言指导,例如解释解题步骤或提供背景知识。2) token级别指导注入:将自然语言指导附加到模型生成的token序列上,形成新的训练数据。3) 显著性token识别:通过计算每个token的概率,识别出对任务贡献最大的显著性token。4) 模型微调:使用修改后的训练数据微调大型语言模型。
关键创新:NLFT的关键创新在于首次将自然语言指导引入到token级别的微调过程中。与传统的SFT方法相比,NLFT能够更有效地利用语言信息,从而在小样本场景下取得更好的性能。与ReFT相比,NLFT无需预热步骤,并且具有更低的计算复杂度和空间复杂度。
关键设计:NLFT的关键设计包括:1) 自然语言指导的格式:自然语言指导需要设计成易于模型理解和学习的格式,例如使用简洁明了的句子和关键词。2) 显著性token的计算方法:可以使用不同的方法来计算token的显著性,例如基于梯度的方法或基于注意力机制的方法。3) 损失函数的设计:损失函数需要能够鼓励模型学习自然语言指导,并生成正确的token序列。论文中未明确给出这些细节,属于未知信息。
🖼️ 关键图片
📊 实验亮点
NLFT在GSM8K数据集上,仅使用50个训练样本,就实现了超过SFT 219%的准确率提升。与ReFT相比,NLFT的时间复杂度降低了78.27%,空间复杂度降低了92.24%。这些结果表明,NLFT在小样本微调方面具有显著的优势。
🎯 应用场景
NLFT适用于各种资源受限的边缘计算场景,例如智能客服、金融风控、医疗诊断等。在这些场景下,往往缺乏大量的标注数据,但需要快速部署定制化的语言模型。NLFT能够以较低的成本和较短的时间,提升模型在特定任务上的性能,具有广阔的应用前景。
📄 摘要(原文)
Large language model fine-tuning techniques typically depend on extensive labeled data, external guidance, and feedback, such as human alignment, scalar rewards, and demonstration. However, in practical application, the scarcity of specific knowledge poses unprecedented challenges to existing fine-tuning techniques. In this paper, focusing on fine-tuning tasks in specific domains with limited data, we introduce Natural Language Fine-Tuning (NLFT), which utilizes natural language for fine-tuning for the first time. By leveraging the strong language comprehension capability of the target LM, NLFT attaches the guidance of natural language to the token-level outputs. Then, saliency tokens are identified with calculated probabilities. Since linguistic information is effectively utilized in NLFT, our proposed method significantly reduces training costs. It markedly enhances training efficiency, comprehensively outperforming reinforcement fine-tuning algorithms in accuracy, time-saving, and resource conservation. Additionally, on the macro level, NLFT can be viewed as a token-level fine-grained optimization of SFT, thereby efficiently replacing the SFT process without the need for warm-up (as opposed to ReFT requiring multiple rounds of warm-up with SFT). Compared to SFT, NLFT does not increase the algorithmic complexity, maintaining O(n). Extensive experiments on the GSM8K dataset demonstrate that NLFT, with only 50 data instances, achieves an accuracy increase that exceeds SFT by 219%. Compared to ReFT, the time complexity and space complexity of NLFT are reduced by 78.27% and 92.24%, respectively. The superior technique of NLFT is paving the way for the deployment of various innovative LLM fine-tuning applications when resources are limited at network edges. Our code has been released at https://github.com/Julia-LiuJ/NLFT.