LLM2: Let Large Language Models Harness System 2 Reasoning
作者: Cheng Yang, Chufan Shi, Siheng Li, Bo Shui, Yujiu Yang, Wai Lam
分类: cs.CL, cs.AI
发布日期: 2024-12-29 (更新: 2025-02-28)
备注: Accepted to NAACL 2025 Main Conference
💡 一句话要点
LLM2:利用大语言模型进行系统2推理,提升问题解决能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 双过程理论 推理验证 数学问题解决 自洽性 token质量 系统1系统2
📋 核心要点
- 现有LLM的自回归架构缺乏区分理想和不良结果的机制,导致输出结果可能不尽如人意。
- LLM2框架结合了LLM(系统1)和基于过程的验证器(系统2),通过验证器提供反馈来区分理想和不良输出。
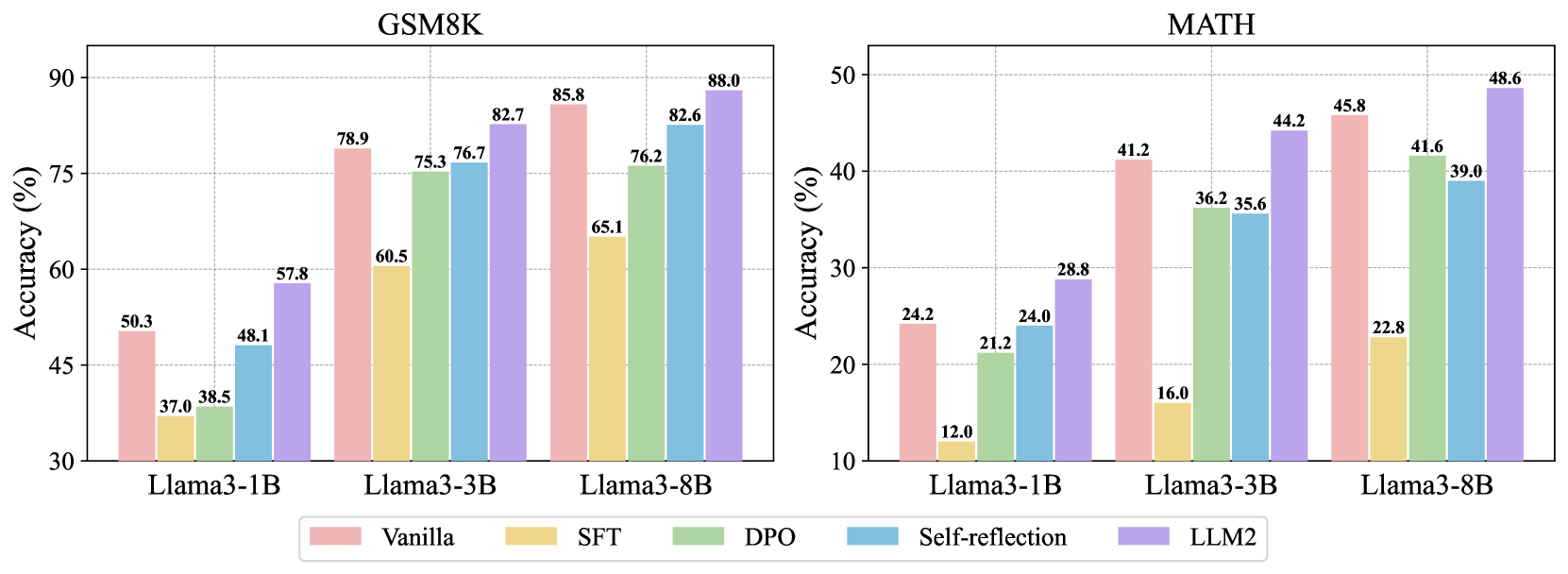
- 实验表明,LLM2在数学推理任务上显著提升了准确率,例如在GSM8K数据集上Llama3-1B的准确率提升了7.5%。
📝 摘要(中文)
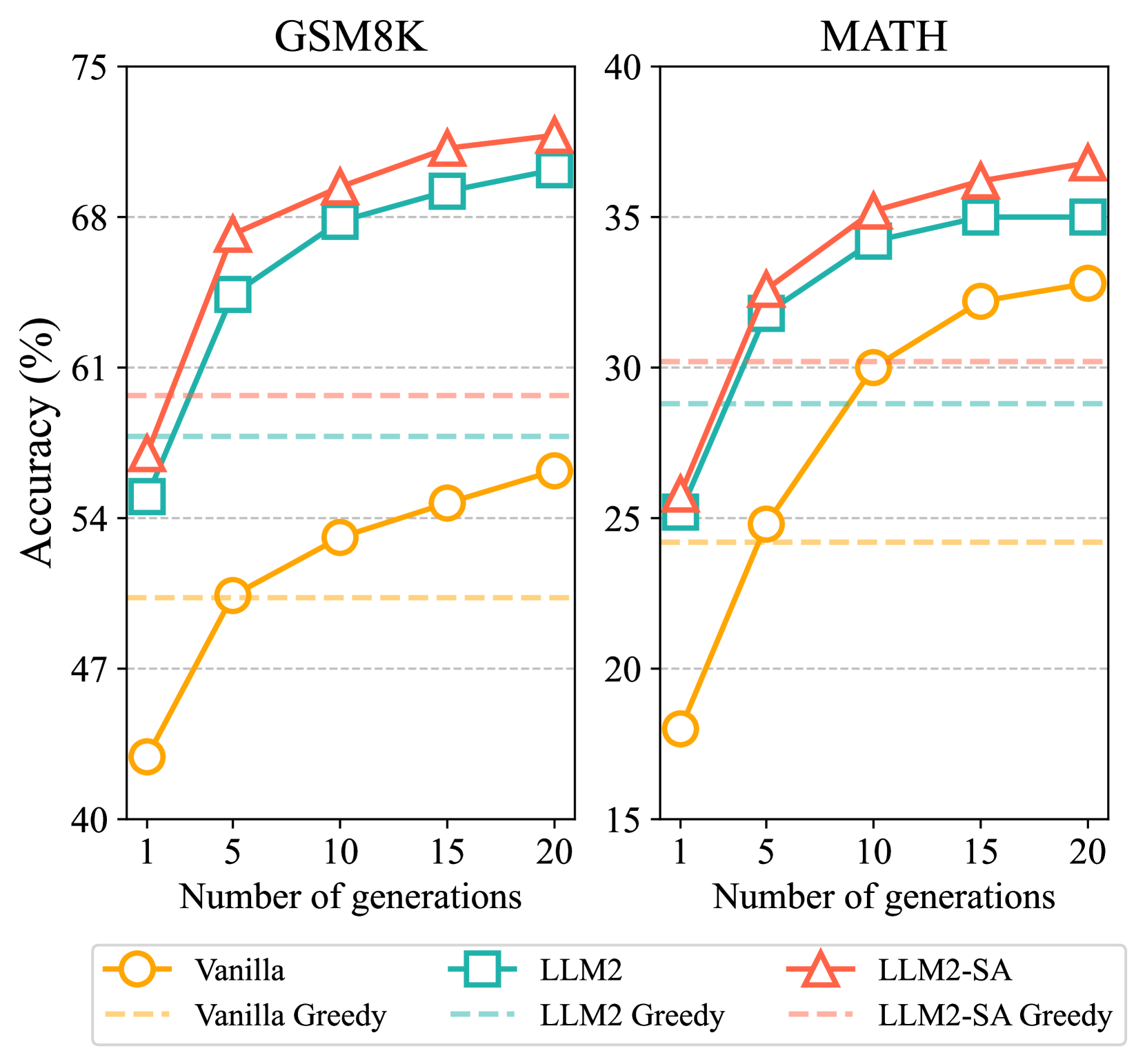
大型语言模型(LLMs)在各种任务中展现了令人印象深刻的能力,但偶尔也会产生不尽如人意的输出。我们认为这些局限性源于LLMs的自回归架构,该架构本质上缺乏区分理想和不良结果的机制。受人类认知双过程理论的启发,我们引入了LLM2,这是一个新颖的框架,它将LLM(系统1)与基于过程的验证器(系统2)相结合。在LLM2中,LLM负责生成合理的候选答案,而验证器提供及时的、基于过程的反馈,以区分理想和不良输出。验证器通过我们的token质量探索策略生成的合成过程监督数据,使用成对比较损失进行训练。在数学推理基准测试上的实验结果证实了LLM2的有效性,例如,Llama3-1B在GSM8K上的准确率从50.3提高到57.8(+7.5)。此外,当与自洽性结合使用时,LLM2实现了额外的改进,将major@20准确率从56.2提高到70.2(+14.0)。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在复杂推理任务中表现出的不稳定性问题,即LLM有时会产生不理想甚至错误的答案。现有的自回归架构缺乏有效区分和纠正这些错误的能力,导致模型在需要深度思考和逐步推理的任务中表现受限。
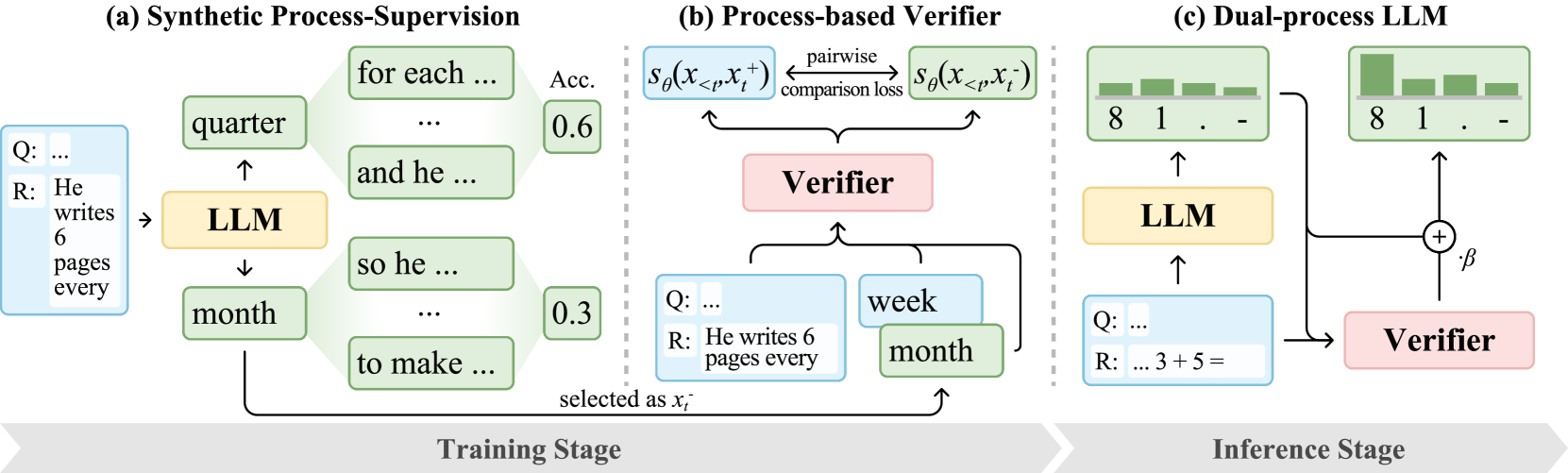
核心思路:论文的核心思路是借鉴人类认知中的双过程理论,引入一个额外的“系统2”验证器来对LLM(“系统1”)的输出进行评估和修正。系统1快速生成候选答案,系统2则进行更深入的、基于过程的验证,从而提高最终答案的质量和可靠性。
技术框架:LLM2框架包含两个主要模块:LLM(系统1)和验证器(系统2)。LLM负责生成候选答案,验证器则负责评估LLM生成的token序列的质量,并提供反馈。验证器通过一个token质量探索策略生成的合成数据进行训练,该策略旨在模拟人类专家对推理过程的评估。整个流程可以迭代进行,系统2的反馈可以用于指导系统1生成更好的候选答案。
关键创新:该论文的关键创新在于将人类认知中的双过程理论应用于LLM,并设计了一个可训练的验证器来模拟“系统2”的推理过程。与传统的LLM相比,LLM2能够更好地识别和纠正推理过程中的错误,从而提高最终答案的准确性。此外,token质量探索策略也是一个重要的创新,它能够有效地生成用于训练验证器的合成数据。
关键设计:验证器使用成对比较损失进行训练,目标是区分好的和坏的token序列。Token质量探索策略用于生成训练数据,该策略通过对LLM生成的token序列进行扰动,并根据扰动后的结果对原始序列进行评分。具体的网络结构和参数设置在论文中没有详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM2在数学推理基准测试中取得了显著的性能提升。例如,在GSM8K数据集上,LLM2将Llama3-1B的准确率从50.3%提高到57.8%(+7.5%)。当与自洽性方法结合使用时,LLM2的major@20准确率进一步提高到70.2%(+14.0%),表明LLM2具有很强的泛化能力和实用价值。
🎯 应用场景
LLM2框架具有广泛的应用前景,可以应用于需要复杂推理和问题解决的领域,例如数学、科学、工程等。通过提高LLM的准确性和可靠性,LLM2可以帮助人们更好地解决各种实际问题,并促进人工智能在这些领域的应用。此外,LLM2的设计思想也可以应用于其他类型的AI系统,例如机器人和自动驾驶汽车。
📄 摘要(原文)
Large language models (LLMs) have exhibited impressive capabilities across a myriad of tasks, yet they occasionally yield undesirable outputs. We posit that these limitations are rooted in the foundational autoregressive architecture of LLMs, which inherently lacks mechanisms for differentiating between desirable and undesirable results. Drawing inspiration from the dual-process theory of human cognition, we introduce LLM2, a novel framework that combines an LLM (System 1) with a process-based verifier (System 2). Within LLM2, the LLM is responsible for generating plausible candidates, while the verifier provides timely process-based feedback to distinguish desirable and undesirable outputs. The verifier is trained with a pairwise comparison loss on synthetic process-supervision data generated through our token quality exploration strategy. Empirical results on mathematical reasoning benchmarks substantiate the efficacy of LLM2, exemplified by an accuracy enhancement from 50.3 to 57.8 (+7.5) for Llama3-1B on GSM8K. Furthermore, when combined with self-consistency, LLM2 achieves additional improvements, boosting major@20 accuracy from 56.2 to 70.2 (+14.0).