Confidence v.s. Critique: A Decomposition of Self-Correction Capability for LLMs
作者: Zhe Yang, Yichang Zhang, Yudong Wang, Ziyao Xu, Junyang Lin, Zhifang Sui
分类: cs.CL
发布日期: 2024-12-27
备注: 16 pages, 10 figures
💡 一句话要点
分解LLM自纠错能力:置信度与批判性分析框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自纠错 置信度 批判性 评估指标 监督微调 SFT数据格式 模型分析
📋 核心要点
- 现有LLM自纠错能力评估不足,缺乏对纠错行为的细粒度分析,难以解释纠错成败的原因。
- 论文将自纠错能力分解为置信度和批判性,并提出概率性指标进行量化评估,从而深入理解LLM的纠错行为。
- 实验表明,不同模型在置信度和批判性上表现各异,且两者存在权衡关系。通过改进SFT数据格式,可有效提升自纠错能力。
📝 摘要(中文)
大型语言模型(LLM)能够纠正其自身生成的回复,但也观察到自纠错后准确率下降的现象。为了更深入地理解自纠错,本文致力于分解、评估和分析LLM的自纠错行为。通过枚举和分析自纠错前后答案的正确性,我们将自纠错能力分解为置信度(有信心纠正答案)和批判性(将错误答案转为正确答案)两种能力,并从概率角度提出两个指标来衡量这两种能力,以及另一个指标用于评估整体自纠错能力。基于我们的分解和评估指标,我们进行了广泛的实验并得出了一些经验性结论。例如,我们发现不同的模型可以表现出不同的行为:一些模型更自信,而另一些模型更具批判性。我们还发现,当通过提示或上下文学习来操纵模型自纠错行为时,这两种能力之间存在权衡(即,提高一种能力可能会导致另一种能力下降)。此外,我们发现了一种简单而有效的策略,通过转换监督微调(SFT)数据格式来提高自纠错能力,并且我们的策略在两种能力上都优于原始SFT,并在自纠错后实现了更高的准确率。我们的代码将在GitHub上公开。
🔬 方法详解
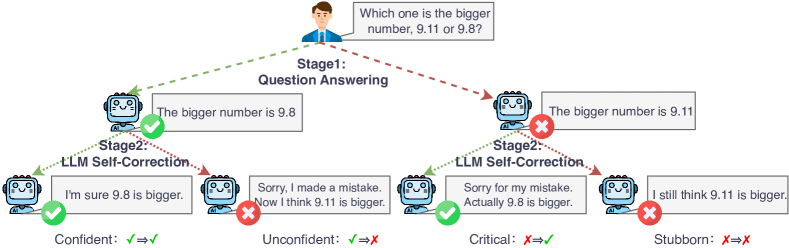
问题定义:论文旨在解决大型语言模型自纠错能力评估不充分的问题。现有方法无法区分模型是因为有信心纠正错误而进行纠错,还是因为能够识别并改正错误而进行纠错。这种笼统的评估方式阻碍了对自纠错机制的深入理解和优化。
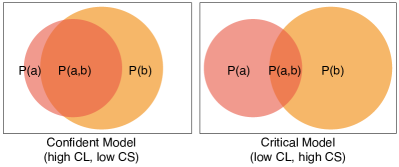
核心思路:论文的核心思路是将自纠错能力分解为两个关键维度:置信度(Confidence)和批判性(Critique)。置信度衡量模型纠正答案的意愿,批判性衡量模型将错误答案转化为正确答案的能力。通过分别评估这两个维度,可以更清晰地了解模型自纠错行为的内在机制。
技术框架:论文的技术框架主要包含三个部分:1) 自纠错行为的分解:将自纠错过程划分为“原始答案”、“纠正后的答案”两个阶段,并根据答案的正确性定义置信度和批判性。2) 评估指标的提出:从概率角度出发,设计了用于衡量置信度、批判性以及整体自纠错能力的指标。这些指标能够量化模型在不同维度上的表现。3) 实验验证:通过在不同模型和数据集上进行实验,验证所提出的分解方法和评估指标的有效性,并分析不同因素对自纠错能力的影响。
关键创新:论文最重要的技术创新在于对LLM自纠错能力的分解。以往的研究通常将自纠错视为一个整体,而本文首次将其分解为置信度和批判性两个独立但相关的维度。这种分解方式为深入理解和优化LLM的自纠错机制提供了新的视角。
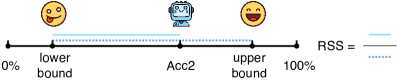
关键设计:论文的关键设计包括:1) 置信度指标的设计:该指标基于模型在给出错误答案后选择纠正的概率。2) 批判性指标的设计:该指标基于模型将错误答案纠正为正确答案的概率。3) 整体自纠错能力指标的设计:该指标综合考虑了置信度和批判性,能够全面评估模型的自纠错表现。此外,论文还提出了一种通过转换SFT数据格式来提升自纠错能力的策略,具体实现细节未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,不同的LLM模型在置信度和批判性上表现出显著差异。通过改进SFT数据格式,可以有效提升模型的自纠错能力,并在两种能力上均优于原始SFT方法。具体提升幅度未知,但表明该方法具有实际应用价值。
🎯 应用场景
该研究成果可应用于提升LLM在各种任务中的可靠性和准确性,例如问答系统、文本生成和代码生成。通过深入理解和优化LLM的自纠错能力,可以减少错误信息的传播,提高AI系统的整体性能和用户体验。此外,该研究也为开发更智能、更可靠的AI系统提供了理论基础。
📄 摘要(原文)
Large Language Models (LLMs) can correct their self-generated responses, but a decline in accuracy after self-correction is also witnessed. To have a deeper understanding of self-correction, we endeavor to decompose, evaluate, and analyze the self-correction behaviors of LLMs. By enumerating and analyzing answer correctness before and after self-correction, we decompose the self-correction capability into confidence (being confident to correct answers) and critique (turning wrong answers to correct) capabilities, and propose two metrics from a probabilistic perspective to measure these 2 capabilities, along with another metric for overall self-correction capability evaluation. Based on our decomposition and evaluation metrics, we conduct extensive experiments and draw some empirical conclusions. For example, we find different models can exhibit distinct behaviors: some models are confident while others are more critical. We also find the trade-off between the two capabilities (i.e. improving one can lead to a decline in the other) when manipulating model self-correction behavior by prompts or in-context learning. Further, we find a simple yet efficient strategy to improve self-correction capability by transforming Supervision Fine-Tuning (SFT) data format, and our strategy outperforms vanilla SFT in both capabilities and achieves much higher accuracy after self-correction. Our code will be publicly available on GitHub.