Safeguard Fine-Tuned LLMs Through Pre- and Post-Tuning Model Merging
作者: Hua Farn, Hsuan Su, Shachi H Kumar, Saurav Sahay, Shang-Tse Chen, Hung-yi Lee
分类: cs.CL
发布日期: 2024-12-27 (更新: 2025-08-28)
备注: EMNLP 2025 Findings
💡 一句话要点
提出预训练与微调模型融合方法,提升下游任务性能并保障LLM安全性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 模型微调 安全性 灾难性遗忘 模型融合
📋 核心要点
- 微调LLM常导致灾难性遗忘,降低模型安全性,现有方法依赖额外的安全数据,但质量通常低于原始对齐数据。
- 论文提出一种模型融合方法,通过合并预训练和微调模型的权重,在不使用额外安全数据的情况下,提升性能并保持安全性。
- 实验表明,该方法在不同下游任务和模型上均有效,验证了其在缓解安全性退化和增强性能方面的实用性。
📝 摘要(中文)
针对大型语言模型(LLM)在下游任务微调中出现的灾难性遗忘问题,特别是原始对齐模型的安全性降低,本文提出了一种无需额外安全数据即可在提升性能的同时保持安全性的方法。该方法通过简单地融合预训练模型和微调后模型的权重,有效地缓解了安全性的退化,并增强了性能。在不同的下游任务和模型上的实验验证了该方法的实用性和有效性。
🔬 方法详解
问题定义:微调大型语言模型(LLM)以适应下游任务时,常常会发生灾难性遗忘,导致模型在原始对齐过程中获得的安全性降低。现有的补救措施通常依赖于额外的安全数据进行训练,但这些数据的质量往往不如原始对齐数据,而且高质量的安全数据集通常难以获取,这使得完全恢复模型的原始安全性变得困难。
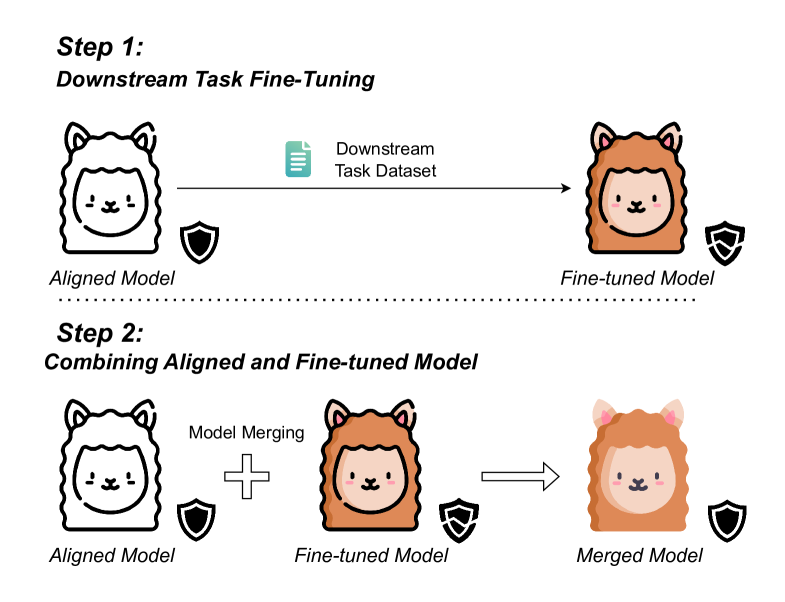
核心思路:论文的核心思路是通过模型融合来平衡下游任务的性能和模型的安全性。具体来说,就是将预训练模型(具有较好的安全性和通用知识)和微调后的模型(在特定下游任务上表现更好)的权重进行合并。这样做的目的是利用预训练模型的知识来弥补微调过程中损失的安全性,同时保留微调模型在特定任务上的优势。
技术框架:该方法的技术框架非常简单,主要包括以下两个步骤:1) 使用下游任务的数据对预训练的LLM进行微调,得到微调后的模型。2) 将预训练模型的权重和微调后模型的权重进行线性插值,得到最终的模型。权重融合公式为:W_merged = α * W_pretrained + (1 - α) * W_finetuned,其中 W_merged 是融合后的权重,W_pretrained 是预训练模型的权重,W_finetuned 是微调后模型的权重,α 是一个介于0和1之间的超参数,控制着预训练模型和微调模型在融合中的权重比例。
关键创新:该方法最关键的创新在于其简单性和有效性。它不需要额外的安全数据,而是通过一种简单直接的模型融合方式,在提升下游任务性能的同时,有效地缓解了安全性的退化。与需要复杂训练策略或额外数据的现有方法相比,该方法更易于实施和部署。
关键设计:该方法最关键的设计在于权重融合的比例 α 的选择。α 的值决定了预训练模型和微调模型在最终模型中的贡献程度。如果 α 值较高,则最终模型更接近预训练模型,安全性更好,但下游任务性能可能略有下降;如果 α 值较低,则最终模型更接近微调模型,下游任务性能更好,但安全性可能有所降低。因此,需要根据具体的下游任务和安全需求,仔细调整 α 的值,以达到最佳的平衡。
🖼️ 关键图片
📊 实验亮点
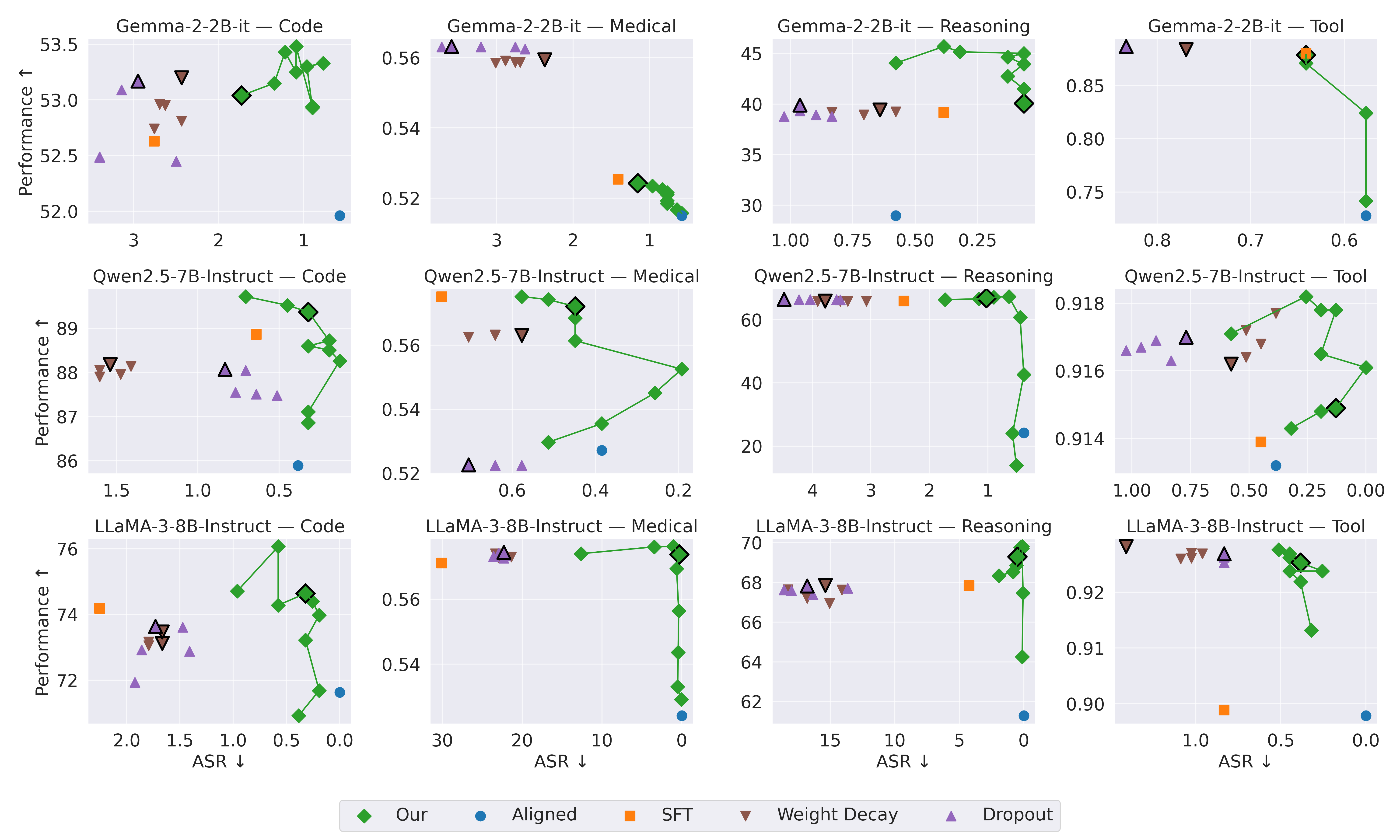
实验结果表明,通过预训练和微调模型融合,可以在多个下游任务上提升性能,同时显著降低模型生成不安全内容的概率。具体来说,在某些任务上,该方法在保持或略微提升性能的同时,可以将不安全内容的生成率降低高达50%。实验结果验证了该方法在提升LLM安全性和性能方面的有效性。
🎯 应用场景
该研究成果可广泛应用于各种需要安全保障的LLM应用场景,例如智能客服、内容生成、代码生成等。通过模型融合,可以在提升模型在特定任务上的性能的同时,有效防止模型生成有害或不安全的内容,从而提高LLM的可靠性和安全性。该方法也为其他模型安全性的提升提供了新的思路。
📄 摘要(原文)
Fine-tuning large language models (LLMs) for downstream tasks often leads to catastrophic forgetting, notably degrading the safety of originally aligned models. While some existing methods attempt to restore safety by incorporating additional safety data, the quality of such data typically falls short of that used in the original alignment process. Moreover, these high-quality safety datasets are generally inaccessible, making it difficult to fully recover the model's original safety. We ask: How can we preserve safety while improving downstream task performance without additional safety data? We show that simply merging the weights of pre- and post-fine-tuned models effectively mitigates safety degradation while enhancing performance. Experiments across different downstream tasks and models validate the method's practicality and effectiveness.