Dovetail: A CPU/GPU Heterogeneous Speculative Decoding for LLM inference
作者: Libo Zhang, Zhaoning Zhang, Baizhou Xu, Rui Li, Zhiliang Tian, Songzhu Mei, Dongsheng Li
分类: cs.CL
发布日期: 2024-12-25 (更新: 2025-09-09)
备注: 14 pages, 6 figures
💡 一句话要点
提出Dovetail以解决LLM推理中的资源利用不足问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理加速 异构计算 动态门控融合 GPU优化 CPU验证 资源利用 自然语言处理
📋 核心要点
- 现有方法在LLM推理中面临计算资源和内存需求增加的挑战,导致效率低下。
- Dovetail通过在GPU上进行初步预测,并在CPU上验证输出,优化了异构硬件环境下的推理过程。
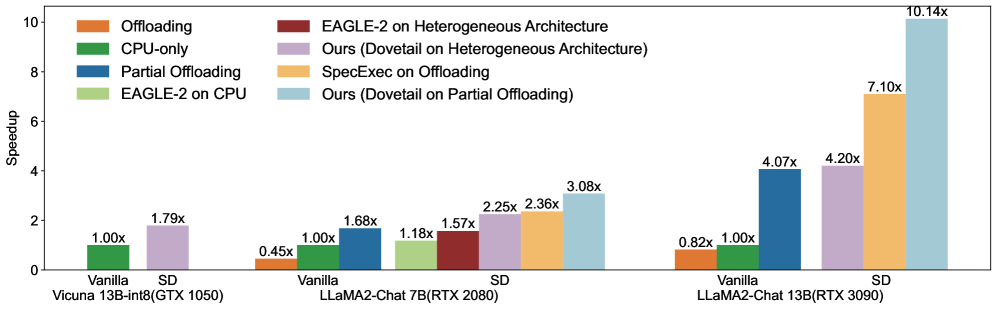
- 实验结果显示,Dovetail在13B模型上实现了1.79倍到10.1倍的推理速度提升,且生成文本质量稳定。
📝 摘要(中文)
随着大型语言模型(LLMs)性能的不断提升,其对计算资源和内存的需求显著增加,这给消费者级设备和传统服务器的高效推理带来了重大挑战。现有的参数卸载和部分卸载技术在一定程度上缓解了GPU内存压力,但由于通信延迟和硬件资源利用不佳,其效果有限。为此,本文提出Dovetail,一种无损推理加速方法,利用异构设备的互补特性和推测解码的优势。Dovetail在GPU上部署草稿模型进行初步预测,同时在CPU上运行目标模型验证这些输出。通过减少数据传输的粒度,Dovetail显著降低了通信开销。实验结果表明,Dovetail在不同设备上实现了1.79倍到10.1倍的推理加速,同时保持生成文本的一致性和稳定性。
🔬 方法详解
问题定义:本文旨在解决大型语言模型推理中由于计算资源和内存需求增加而导致的效率低下问题。现有的参数卸载和部分卸载技术在缓解GPU内存压力方面效果有限,主要受制于通信延迟和硬件资源利用不佳。
核心思路:Dovetail的核心思路是利用异构设备的互补特性,通过在GPU上部署草稿模型进行初步预测,并在CPU上进行验证,从而减少数据传输的粒度,降低通信开销。
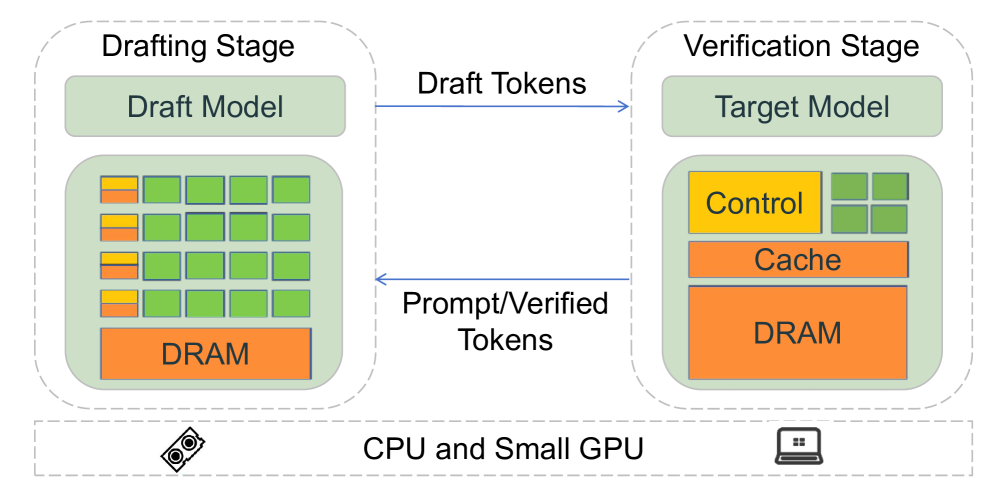
技术框架:Dovetail的整体架构包括草稿模型和目标模型两个主要模块。草稿模型在GPU上执行初步推理,目标模型在CPU上进行结果验证。通过动态调整草稿令牌数量和模型深度,进一步优化推理效率。
关键创新:Dovetail的关键创新在于引入了动态门控融合(DGF)机制,增强了特征和嵌入信息的整合能力。这一机制使得模型在异构硬件环境下能够更高效地运行,显著提升了推理速度。
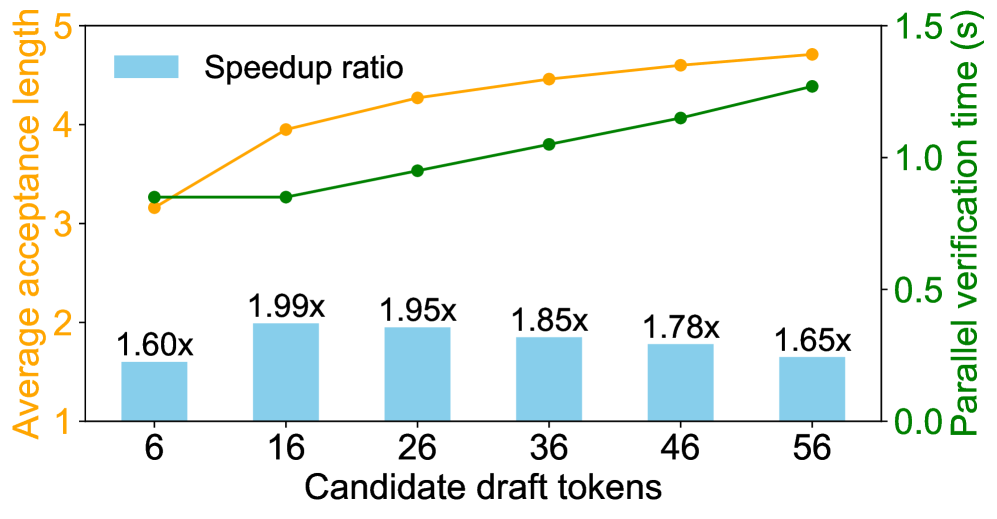
关键设计:在设计中,草稿模型的令牌数量被减少,以降低并行验证延迟,同时增加模型深度以增强预测能力。此外,DGF机制的引入是为了优化特征融合,提升模型整体性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Dovetail在13B模型上实现了1.79倍到10.1倍的推理速度提升,覆盖多种消费者级GPU设备,且生成文本的一致性和稳定性得到了有效保障。这一显著的性能提升为LLM在实际应用中的部署提供了新的可能性。
🎯 应用场景
Dovetail的研究成果具有广泛的应用潜力,特别是在资源受限的环境中,如移动设备、边缘计算和传统服务器等场景。通过提高大型语言模型的推理效率,该方法可以促进自然语言处理、智能助手和对话系统等领域的发展,提升用户体验和系统响应速度。
📄 摘要(原文)
With the continuous advancement in the performance of large language models (LLMs), their demand for computational resources and memory has significantly increased, which poses major challenges for efficient inference on consumer-grade devices and legacy servers. These devices typically feature relatively weaker GPUs and stronger CPUs. Although techniques such as parameter offloading and partial offloading can alleviate GPU memory pressure to some extent, their effectiveness is limited due to communication latency and suboptimal hardware resource utilization. To address this issue, we propose Dovetail, a lossless inference acceleration method that leverages the complementary characteristics of heterogeneous devices and the advantages of speculative decoding. Dovetail deploys a draft model on the GPU to perform preliminary predictions, while a target model running on the CPU validates these outputs. By reducing the granularity of data transfer, Dovetail significantly minimizes communication overhead. To further improve efficiency, we optimize the draft model specifically for heterogeneous hardware environments by reducing the number of draft tokens to lower parallel verification latency, increasing model depth to enhance predictive capabilities, and introducing a Dynamic Gating Fusion (DGF) mechanism to improve the integration of feature and embedding information. We conduct comprehensive evaluations of Dovetail across various consumer-grade GPUs, covering multiple tasks and mainstream models. Experimental results on 13B models demonstrate that Dovetail achieves inference speedups ranging from 1.79x to 10.1x across different devices, while maintaining consistency and stability in the distribution of generated texts.