Intra- and Inter-modal Context Interaction Modeling for Conversational Speech Synthesis
作者: Zhenqi Jia, Rui Liu
分类: cs.CL, cs.SD, eess.AS
发布日期: 2024-12-25
备注: Accepted by ICASSP 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出III-CSS模型,显式建模对话语音合成中的模内与模间上下文交互
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 会话语音合成 多模态对话历史 模内交互 模间交互 对比学习 语音韵律 语音合成
📋 核心要点
- 现有会话语音合成方法未能充分建模多模态对话历史中模内和模间上下文的复杂交互。
- III-CSS模型通过对比学习,显式学习历史文本/语音与目标文本/语音之间的模内和模间关系。
- 在DailyTalk数据集上的实验表明,III-CSS在韵律表达方面显著优于现有先进方法。
📝 摘要(中文)
会话语音合成(CSS)旨在有效地利用多模态对话历史(MDH)为目标话语生成具有适当会话韵律的语音。CSS的关键挑战在于建模MDH与目标话语之间的交互。MDH中的文本和语音模态具有其独特的影响,并且它们相互补充,从而对目标话语产生全面的影响。先前的工作没有明确地建模这种模内和模间交互。为了解决这个问题,我们提出了一种新的基于模内和模间上下文交互方案的CSS系统,称为III-CSS。具体来说,在训练阶段,我们将MDH与目标话语中的文本和语音模态相结合,以获得四种模态组合,包括历史文本-下一个文本,历史语音-下一个语音,历史文本-下一个语音和历史语音-下一个文本。然后,我们设计了两个基于对比学习的模内交互模块和两个模间交互模块,以深入学习模内和模间上下文交互。在推理阶段,我们采用MDH并采用经过训练的交互模块来充分推断目标话语文本内容的语音韵律。在DailyTalk数据集上的主观和客观实验表明,III-CSS在韵律表达方面优于先进的基线。
🔬 方法详解
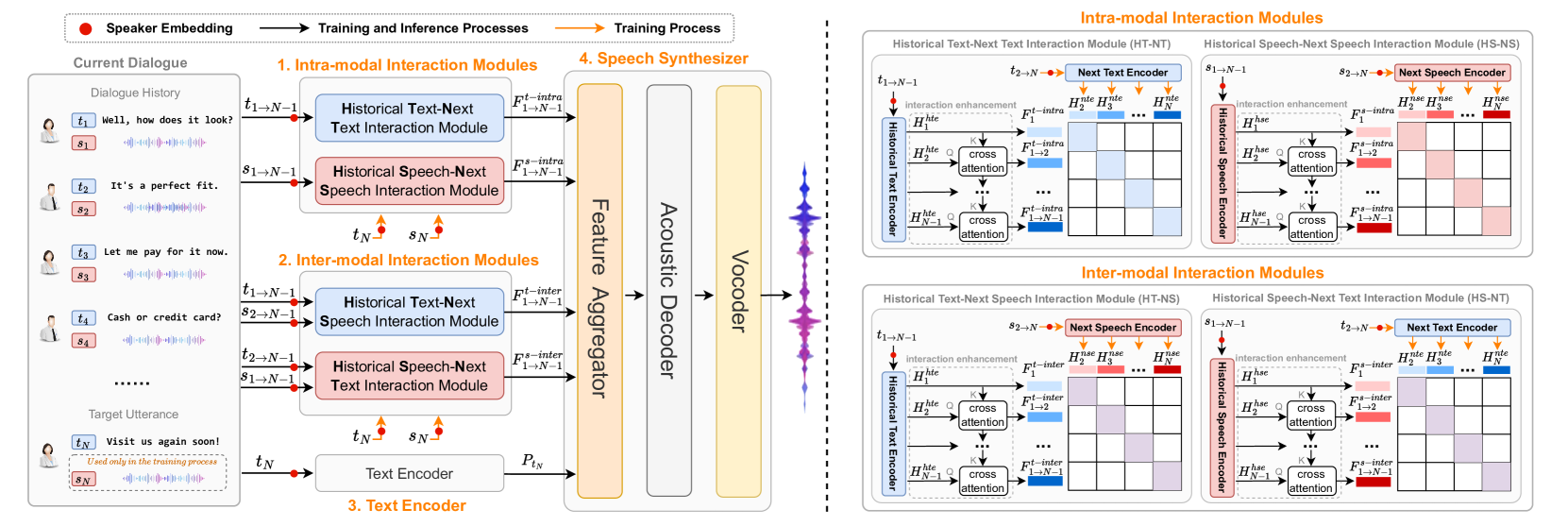
问题定义:会话语音合成(CSS)旨在根据多模态对话历史(MDH)生成具有合适韵律的语音。现有方法未能充分挖掘MDH中不同模态(文本和语音)内部以及模态之间的复杂交互关系,导致合成语音的韵律表达不够自然和丰富。
核心思路:该论文的核心思路是显式地建模MDH中文本和语音模态的模内和模间交互。通过将历史文本/语音与目标文本/语音进行组合,并利用对比学习,使模型能够学习到不同模态组合之间的关联性,从而更好地预测目标语音的韵律。
技术框架:III-CSS系统主要分为训练和推理两个阶段。在训练阶段,首先将MDH与目标话语的文本和语音进行组合,形成四种模态组合。然后,通过两个模内交互模块和两个模间交互模块,利用对比学习来学习这些模态组合之间的交互关系。在推理阶段,将MDH输入到训练好的交互模块中,以推断目标话语文本内容的语音韵律。
关键创新:该论文的关键创新在于提出了模内和模间上下文交互建模方案。与以往方法不同,III-CSS显式地建模了文本和语音模态内部以及模态之间的交互关系,从而更全面地利用了MDH的信息。
关键设计:该论文设计了四个交互模块:历史文本-下一个文本(模内)、历史语音-下一个语音(模内)、历史文本-下一个语音(模间)和历史语音-下一个文本(模间)。每个模块都基于对比学习,通过最大化正样本之间的相似性,最小化负样本之间的相似性,来学习模态之间的交互关系。具体的损失函数未知,网络结构也未详细描述。
🖼️ 关键图片
📊 实验亮点
在DailyTalk数据集上的实验结果表明,III-CSS模型在韵律表达方面优于先进的基线方法。主观听觉测试和客观指标均显示,III-CSS能够生成更自然、更具表现力的语音,证明了显式建模模内和模间交互的有效性。具体的性能提升数据未知。
🎯 应用场景
该研究成果可应用于智能客服、语音助手、游戏角色配音等领域,提升人机交互的自然度和表现力。通过更精准地理解对话历史,合成更具表现力的语音,从而改善用户体验,使人机交互更加自然流畅。未来,该技术有望应用于更广泛的语音合成场景,例如个性化语音定制、情感语音合成等。
📄 摘要(原文)
Conversational Speech Synthesis (CSS) aims to effectively take the multimodal dialogue history (MDH) to generate speech with appropriate conversational prosody for target utterance. The key challenge of CSS is to model the interaction between the MDH and the target utterance. Note that text and speech modalities in MDH have their own unique influences, and they complement each other to produce a comprehensive impact on the target utterance. Previous works did not explicitly model such intra-modal and inter-modal interactions. To address this issue, we propose a new intra-modal and inter-modal context interaction scheme-based CSS system, termed III-CSS. Specifically, in the training phase, we combine the MDH with the text and speech modalities in the target utterance to obtain four modal combinations, including Historical Text-Next Text, Historical Speech-Next Speech, Historical Text-Next Speech, and Historical Speech-Next Text. Then, we design two contrastive learning-based intra-modal and two inter-modal interaction modules to deeply learn the intra-modal and inter-modal context interaction. In the inference phase, we take MDH and adopt trained interaction modules to fully infer the speech prosody of the target utterance's text content. Subjective and objective experiments on the DailyTalk dataset show that III-CSS outperforms the advanced baselines in terms of prosody expressiveness. Code and speech samples are available at https://github.com/AI-S2-Lab/I3CSS.