Harnessing Large Language Models for Knowledge Graph Question Answering via Adaptive Multi-Aspect Retrieval-Augmentation
作者: Derong Xu, Xinhang Li, Ziheng Zhang, Zhenxi Lin, Zhihong Zhu, Zhi Zheng, Xian Wu, Xiangyu Zhao, Tong Xu, Enhong Chen
分类: cs.CL
发布日期: 2024-12-24 (更新: 2025-01-06)
备注: Accepted by AAAI'2025
💡 一句话要点
提出Amar框架,通过自适应多方面检索增强提升大语言模型在知识图谱问答中的表现。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱问答 大语言模型 检索增强 自适应学习 多方面知识 知识推理 自对齐 相关性门控
📋 核心要点
- 现有知识图谱问答方法易引入噪声,干扰大语言模型对关键信息的关注,导致推理错误。
- Amar框架通过自对齐模块减少噪声,并利用相关性门控模块筛选信息,提升LLM推理能力。
- 实验表明,Amar在WebQSP和CWQ数据集上均取得SOTA性能,显著提升了准确率和逻辑形式生成能力。
📝 摘要(中文)
大型语言模型(LLMs)展示了卓越的能力,但在处理复杂的知识推理任务时,由于幻觉和过时的知识,常常会产生不正确的输出。以往的研究试图通过从大规模知识图谱(KGs)中检索事实知识来辅助LLMs进行逻辑推理和答案预测,以此来缓解这个问题。然而,这种方法常常引入噪声和不相关的数据,尤其是在来自多个知识方面的广泛上下文中。这样,LLM的注意力可能会被问题和相关信息误导。在本研究中,我们引入了一种基于KG的自适应多方面检索增强(Amar)框架。该方法检索包括实体、关系和子图在内的知识,并将检索到的每一段文本转换为提示嵌入。Amar框架包含两个关键子组件:1)一个自对齐模块,用于对齐实体、关系和子图之间的共性,从而增强检索到的文本,减少噪声干扰;2)一个相关性门控模块,该模块采用一个软门来学习问题和多方面检索数据之间的相关性得分,以确定应该使用哪些信息来增强LLMs的输出,甚至完全过滤掉哪些信息。我们的方法在两个常见的数据集WebQSP和CWQ上取得了最先进的性能,在准确率上比最好的竞争对手提高了1.9%,在逻辑形式生成上比直接使用检索到的文本作为上下文提示的方法提高了6.6%。这些结果证明了Amar在提高LLMs推理能力方面的有效性。
🔬 方法详解
问题定义:论文旨在解决大语言模型在知识图谱问答任务中,因检索到的知识包含噪声和不相关信息,导致推理性能下降的问题。现有方法直接将检索到的知识作为上下文提示,容易误导LLM的注意力,降低答案的准确性。
核心思路:论文的核心思路是设计一个自适应的多方面检索增强框架,该框架能够从知识图谱中检索实体、关系和子图等多方面的知识,并通过自对齐模块减少噪声,利用相关性门控模块筛选信息,从而更有效地辅助LLM进行推理。
技术框架:Amar框架包含两个主要模块:1) 自对齐模块:该模块旨在对齐实体、关系和子图之间的共性,增强检索到的文本,减少噪声干扰。具体来说,它通过学习不同知识片段之间的相似性,突出关键信息,抑制无关信息。2) 相关性门控模块:该模块使用一个软门机制,学习问题和多方面检索数据之间的相关性得分,从而决定哪些信息应该用于增强LLM的输出,甚至完全过滤掉哪些信息。整个流程是先进行多方面知识检索,然后通过自对齐模块降噪,再通过相关性门控模块筛选,最后将筛选后的知识输入LLM进行推理。
关键创新:该论文的关键创新在于提出了自对齐模块和相关性门控模块。自对齐模块能够有效地减少检索到的知识中的噪声,提高知识的质量。相关性门控模块能够根据问题自适应地选择相关的知识,避免无关信息对LLM推理的干扰。与现有方法直接使用检索到的知识作为上下文提示相比,Amar框架能够更有效地利用知识图谱中的信息,提高LLM的推理性能。
关键设计:自对齐模块的具体实现方式未知,但推测可能使用了某种注意力机制或对比学习方法来学习不同知识片段之间的相似性。相关性门控模块使用了一个软门机制,具体实现方式未知,但推测可能使用了sigmoid函数或softmax函数来生成相关性得分。损失函数的设计未知,但推测可能包含了交叉熵损失或对比损失等。
🖼️ 关键图片
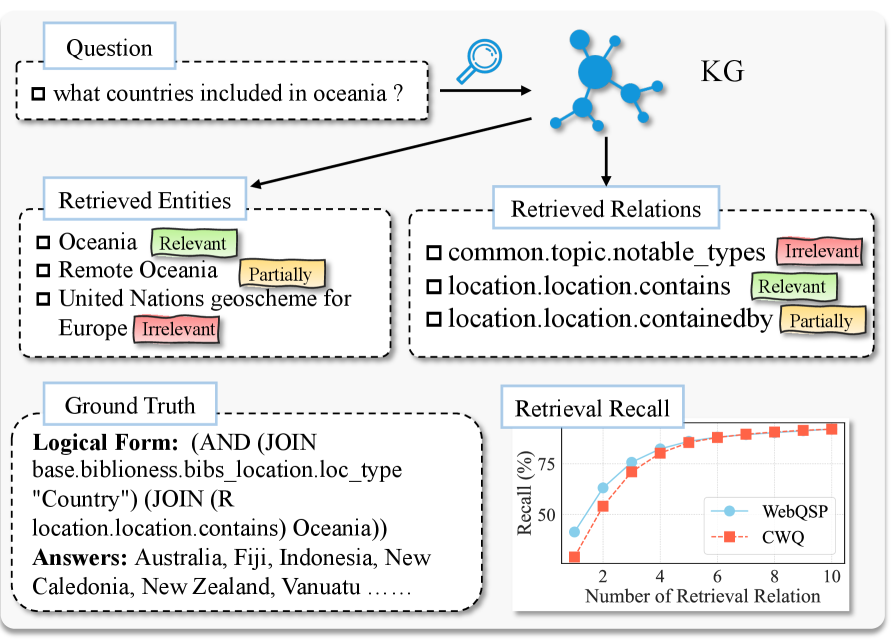
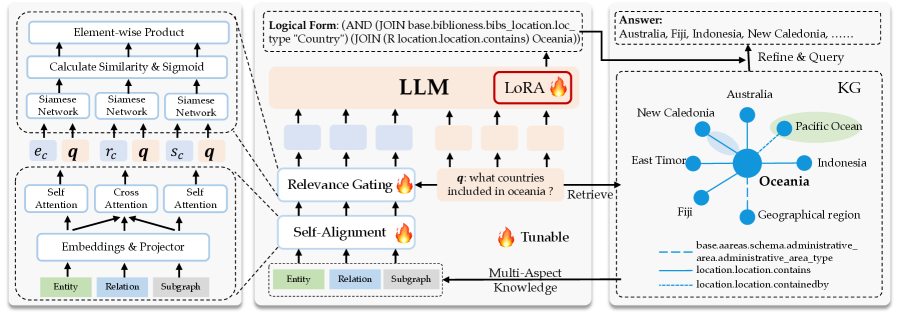
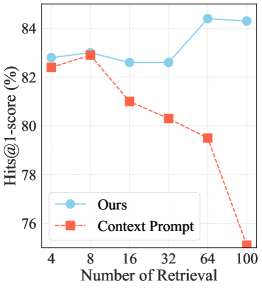
📊 实验亮点
Amar框架在WebQSP和CWQ两个知识图谱问答数据集上取得了SOTA性能。在WebQSP上,Amar的准确率比最佳竞争对手提高了1.9%。在CWQ上,Amar在逻辑形式生成方面比直接使用检索文本作为上下文提示的方法提高了6.6%。这些结果表明,Amar框架能够有效地提高LLM在知识图谱问答任务中的推理能力。
🎯 应用场景
该研究成果可应用于智能问答系统、知识图谱构建、推荐系统等领域。通过提升大语言模型在知识推理方面的能力,可以构建更智能、更可靠的AI应用,例如:医疗诊断辅助、金融风险评估、智能客服等。未来,该技术有望进一步扩展到更复杂的知识密集型任务中。
📄 摘要(原文)
Large Language Models (LLMs) demonstrate remarkable capabilities, yet struggle with hallucination and outdated knowledge when tasked with complex knowledge reasoning, resulting in factually incorrect outputs. Previous studies have attempted to mitigate it by retrieving factual knowledge from large-scale knowledge graphs (KGs) to assist LLMs in logical reasoning and prediction of answers. However, this kind of approach often introduces noise and irrelevant data, especially in situations with extensive context from multiple knowledge aspects. In this way, LLM attention can be potentially mislead from question and relevant information. In our study, we introduce an Adaptive Multi-Aspect Retrieval-augmented over KGs (Amar) framework. This method retrieves knowledge including entities, relations, and subgraphs, and converts each piece of retrieved text into prompt embeddings. The Amar framework comprises two key sub-components: 1) a self-alignment module that aligns commonalities among entities, relations, and subgraphs to enhance retrieved text, thereby reducing noise interference; 2) a relevance gating module that employs a soft gate to learn the relevance score between question and multi-aspect retrieved data, to determine which information should be used to enhance LLMs' output, or even filtered altogether. Our method has achieved state-of-the-art performance on two common datasets, WebQSP and CWQ, showing a 1.9\% improvement in accuracy over its best competitor and a 6.6\% improvement in logical form generation over a method that directly uses retrieved text as context prompts. These results demonstrate the effectiveness of Amar in improving the reasoning of LLMs.