Multilingual Mathematical Reasoning: Advancing Open-Source LLMs in Hindi and English
作者: Avinash Anand, Kritarth Prasad, Chhavi Kirtani, Ashwin R Nair, Manvendra Kumar Nema, Raj Jaiswal, Rajiv Ratn Shah
分类: cs.CL, cs.AI
发布日期: 2024-12-24
备注: Accepted at AAAI 2025
💡 一句话要点
提出多语言数学推理方法,提升开源LLM在印地语和英语上的数学能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数学推理 多语言LLM 印地语 课程学习 分解策略 结构化解决方案 开源模型
📋 核心要点
- 现有LLM在数学推理方面表现不佳,尤其是在印地语等非英语语言中,面临数据和模型能力的挑战。
- 论文提出课程学习、分解策略和结构化解决方案设计,以提升LLM在数学推理上的性能。
- 实验表明,WizardMath 7B在英语数据集上超越Gemini,在印地语数据集上与Gemini性能相当,验证了方法的有效性。
📝 摘要(中文)
本文旨在提升小型、资源高效的开源LLM在印地语和英语上的数学推理能力。研究评估了OpenHathi 7B、LLaMA-2 7B、WizardMath 7B、Mistral 7B、LLeMMa 7B、MAmmoTH 7B、Gemini Pro和GPT-4等模型,采用零样本、少样本思维链(CoT)方法和监督微调。该方法结合了课程学习,逐步训练模型解决难度递增的问题;一种新颖的分解策略,用于简化复杂的算术运算;以及一种结构化解决方案设计,将解决方案划分为多个阶段。实验结果表明性能显著提升。WizardMath 7B在英语数据集上的准确率超过Gemini 6%,在印地语数据集上与Gemini的性能相匹配。采用结合英语和印地语样本的双语方法,实现了与单独语言模型相当的结果,证明了模型在两种语言中学习数学推理的能力。这项研究突出了改进开源LLM数学推理的潜力。
🔬 方法详解
问题定义:论文旨在解决开源LLM在印地语和英语等多种语言中数学推理能力不足的问题。现有方法在处理复杂数学问题时,尤其是在资源受限的场景下,面临准确率低、泛化性差等痛点。
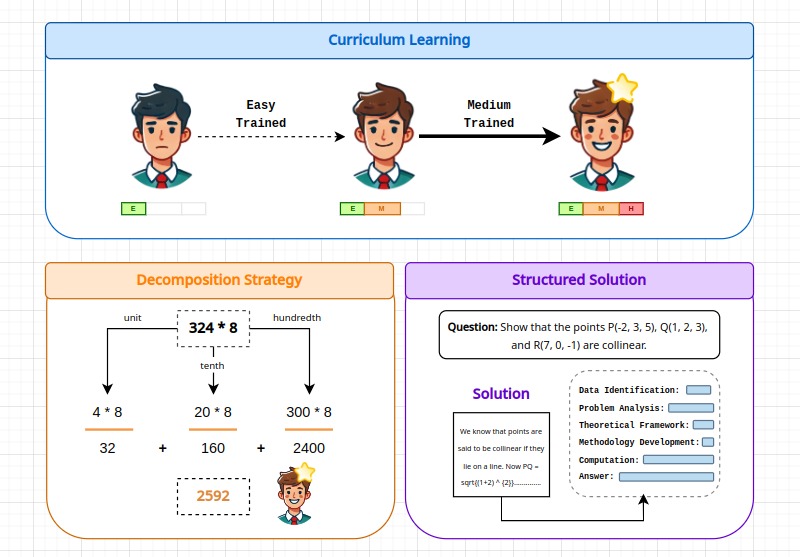
核心思路:论文的核心思路是通过课程学习,逐步提升模型解决问题的能力;利用分解策略简化复杂运算;并采用结构化解决方案设计,使模型能够更清晰地组织推理过程。这种设计旨在提高模型在多语言环境下的数学推理能力。
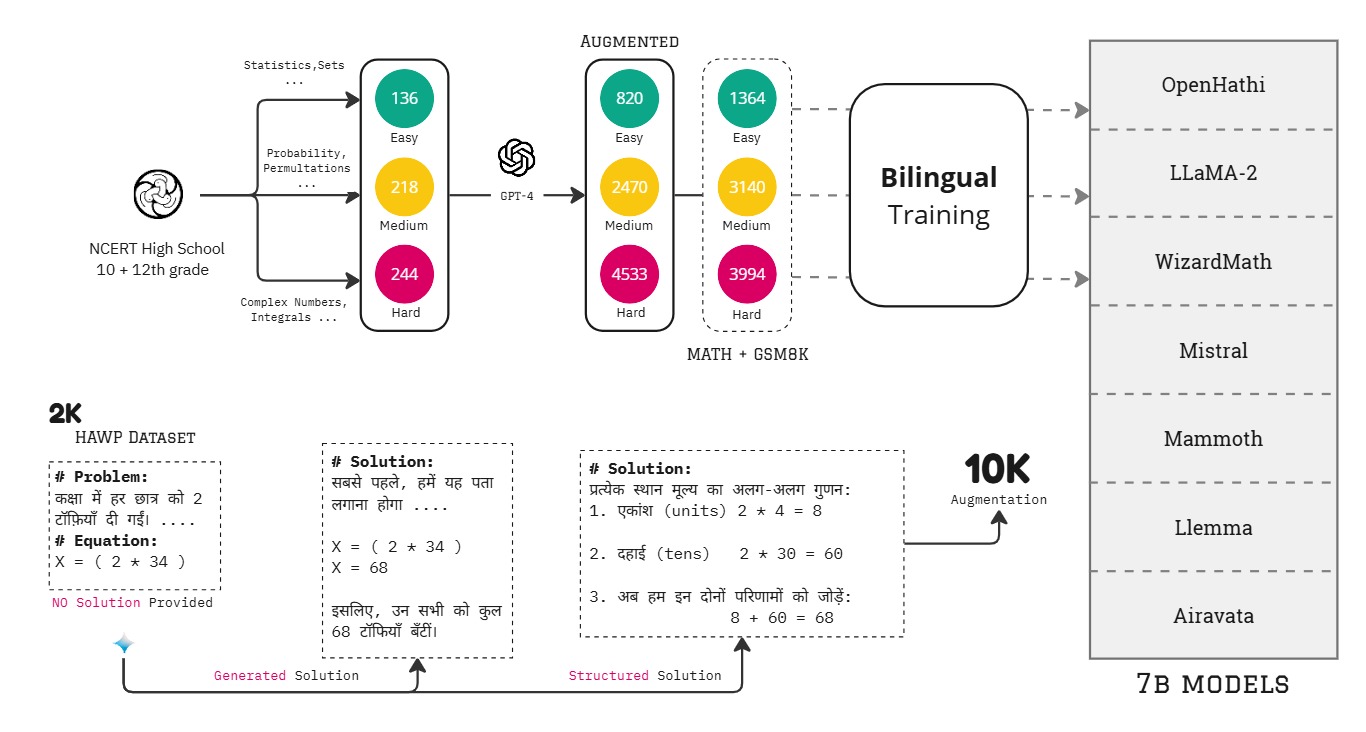
技术框架:整体框架包括数据准备、模型选择、训练策略和评估指标四个主要部分。数据准备阶段构建包含英语和印地语数学题的数据集。模型选择阶段选取多个开源LLM作为基线模型。训练策略包括零样本、少样本CoT和监督微调,并结合课程学习、分解策略和结构化解决方案设计。评估指标包括准确率等。
关键创新:论文的关键创新在于:1) 结合课程学习,使模型能够逐步学习更复杂的数学概念;2) 提出分解策略,将复杂运算分解为更简单的步骤,降低模型推理难度;3) 采用结构化解决方案设计,引导模型按照预定义的步骤进行推理,提高推理的可靠性。
关键设计:课程学习的具体实现方式是按照题目难度进行排序,先训练简单题目,再逐步增加难度。分解策略的具体实现方式是,将复杂的算术运算分解为加减乘除等基本运算。结构化解决方案设计将解题过程划分为多个阶段,例如问题理解、公式选择、计算执行和答案验证。损失函数采用交叉熵损失函数,优化器采用AdamW优化器。
🖼️ 关键图片

📊 实验亮点
实验结果表明,WizardMath 7B在英语数据集上的准确率超过Gemini 6%,在印地语数据集上与Gemini的性能相匹配。采用结合英语和印地语样本的双语方法,实现了与单独语言模型相当的结果,证明了模型在两种语言中学习数学推理的能力。这些结果表明,该研究提出的方法能够有效提升开源LLM在多语言环境下的数学推理能力。
🎯 应用场景
该研究成果可应用于教育领域,例如开发智能辅导系统,帮助学生提高数学能力。此外,还可应用于金融、科学计算等领域,提升LLM在复杂问题求解方面的能力。未来,该研究有望推动多语言LLM在更广泛领域的应用。
📄 摘要(原文)
Large Language Models (LLMs) excel in linguistic tasks but struggle with mathematical reasoning, particularly in non English languages like Hindi. This research aims to enhance the mathematical reasoning skills of smaller, resource efficient open-source LLMs in both Hindi and English. We evaluate models like OpenHathi 7B, LLaMA-2 7B, WizardMath 7B, Mistral 7B, LLeMMa 7B, MAmmoTH 7B, Gemini Pro, and GPT-4 using zero-shot, few-shot chain-of-thought (CoT) methods, and supervised fine-tuning. Our approach incorporates curriculum learning, progressively training models on increasingly difficult problems, a novel Decomposition Strategy to simplify complex arithmetic operations, and a Structured Solution Design that divides solutions into phases. Our experiments result in notable performance enhancements. WizardMath 7B exceeds Gemini's accuracy on English datasets by +6% and matches Gemini's performance on Hindi datasets. Adopting a bilingual approach that combines English and Hindi samples achieves results comparable to individual language models, demonstrating the capability to learn mathematical reasoning in both languages. This research highlights the potential for improving mathematical reasoning in open-source LLMs.