Investigating Large Language Models for Code Vulnerability Detection: An Experimental Study
作者: Xuefeng Jiang, Lvhua Wu, Sheng Sun, Jia Li, Jingjing Xue, Yuwei Wang, Tingting Wu, Min Liu
分类: cs.CL
发布日期: 2024-12-24 (更新: 2025-01-05)
备注: Under Review
🔗 代码/项目: GITHUB | HUGGINGFACE
💡 一句话要点
探索大型语言模型在代码漏洞检测中的应用与性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码漏洞检测 大型语言模型 微调 软件安全 代码智能
📋 核心要点
- 现有代码漏洞检测方法依赖于中等规模序列模型或小型神经网络,效果有限,且缺乏对大型语言模型(LLM)的探索。
- 本研究通过微调四种开源LLM,并与传统方法对比,探索LLM在代码漏洞检测任务中的性能。
- 实验结果表明,LLM在代码漏洞检测任务中具有潜力,并对类不平衡和样本长度等因素进行了定量分析。
📝 摘要(中文)
代码漏洞检测(CVD)对于解决和预防系统安全问题至关重要,在确保软件安全方面发挥着关键作用。以往基于学习的漏洞检测方法依赖于微调中等规模的序列模型或从头开始训练较小的神经网络。最近,大型预训练语言模型(LLM)在包括代码理解和生成在内的各种代码智能任务中展现出了卓越的能力。然而,LLM在检测代码漏洞方面的有效性在很大程度上尚未被充分探索。本研究旨在通过微调LLM用于CVD任务来填补这一空白,涉及四种广泛使用的开源LLM。我们还实现了其他五种先前的基于图或中等规模序列模型进行比较。实验在五个常用的CVD数据集上进行,包括短样本和长样本部分。此外,我们进行了定量实验,以研究类不平衡问题以及模型在不同长度样本上的性能,而这些问题在以前的研究中很少被研究。为了更好地促进社区发展,我们开源了本研究的所有代码和资源,地址为https://github.com/SakiRinn/LLM4CVD 和 https://huggingface.co/datasets/xuefen/VulResource。
🔬 方法详解
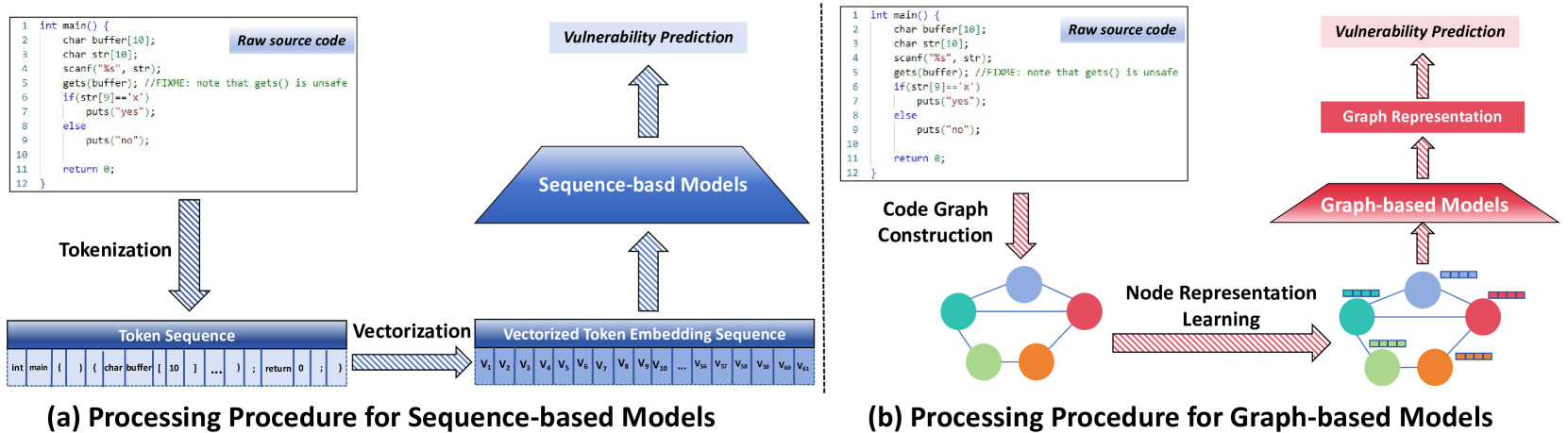
问题定义:代码漏洞检测旨在识别代码中存在的安全缺陷,防止潜在的攻击和系统崩溃。现有方法,如基于中等规模序列模型或小型神经网络的方法,在处理复杂代码和长代码片段时表现不足,且难以充分利用代码的语义信息。此外,类不平衡问题和不同长度样本对模型性能的影响也缺乏深入研究。
核心思路:本研究的核心思路是利用大型预训练语言模型(LLM)强大的代码理解和生成能力,通过微调LLM来提升代码漏洞检测的性能。LLM在海量代码数据上进行预训练,能够学习到丰富的代码语义知识,从而更好地识别代码中的漏洞模式。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择四种广泛使用的开源LLM作为基础模型。2) 在五个常用的代码漏洞检测数据集上对LLM进行微调。3) 实现五种先前的基于图或中等规模序列模型作为对比基线。4) 进行定量实验,分析类不平衡问题和样本长度对模型性能的影响。
关键创新:本研究的关键创新在于首次系统性地探索了大型语言模型在代码漏洞检测任务中的应用。以往研究主要集中在中等规模模型或小型神经网络上,而本研究将LLM引入该领域,并验证了其有效性。此外,该研究还对类不平衡和样本长度等因素进行了深入分析,为未来的研究提供了新的视角。
关键设计:研究中使用了常见的微调策略,针对不同的LLM,可能需要调整学习率、batch size等超参数。损失函数通常采用交叉熵损失,用于衡量模型预测结果与真实标签之间的差异。数据集划分方面,通常采用标准的训练集、验证集和测试集划分方式。此外,为了解决类不平衡问题,可以采用过采样、欠采样或代价敏感学习等方法。
🖼️ 关键图片


📊 实验亮点
该研究通过实验验证了LLM在代码漏洞检测任务中的潜力。实验结果表明,经过微调的LLM在多个数据集上取得了具有竞争力的性能。此外,定量分析揭示了类不平衡和样本长度对模型性能的影响,为未来的研究提供了重要的参考。
🎯 应用场景
该研究成果可应用于软件开发生命周期的各个阶段,例如代码审查、静态分析和安全测试。通过集成LLM驱动的代码漏洞检测工具,可以显著提高漏洞检测的效率和准确性,降低软件安全风险,并为开发者提供及时的安全反馈。
📄 摘要(原文)
Code vulnerability detection (CVD) is essential for addressing and preventing system security issues, playing a crucial role in ensuring software security. Previous learning-based vulnerability detection methods rely on either fine-tuning medium-size sequence models or training smaller neural networks from scratch. Recent advancements in large pre-trained language models (LLMs) have showcased remarkable capabilities in various code intelligence tasks including code understanding and generation. However, the effectiveness of LLMs in detecting code vulnerabilities is largely under-explored. This work aims to investigate the gap by fine-tuning LLMs for the CVD task, involving four widely-used open-source LLMs. We also implement other five previous graph-based or medium-size sequence models for comparison. Experiments are conducted on five commonly-used CVD datasets, including both the part of short samples and long samples. In addition, we conduct quantitative experiments to investigate the class imbalance issue and the model's performance on samples of different lengths, which are rarely studied in previous works. To better facilitate communities, we open-source all codes and resources of this study in https://github.com/SakiRinn/LLM4CVD and https://huggingface.co/datasets/xuefen/VulResource.