Ensuring Consistency for In-Image Translation
作者: Chengpeng Fu, Xiaocheng Feng, Yichong Huang, Wenshuai Huo, Baohang Li, Zhirui Zhang, Yunfei Lu, Dandan Tu, Duyu Tang, Hui Wang, Bing Qin, Ting Liu
分类: cs.CL
发布日期: 2024-12-24
💡 一句话要点
提出HCIIT框架,解决图像内翻译中翻译一致性和图像生成一致性问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像内翻译 多模态学习 扩散模型 一致性 大型语言模型
📋 核心要点
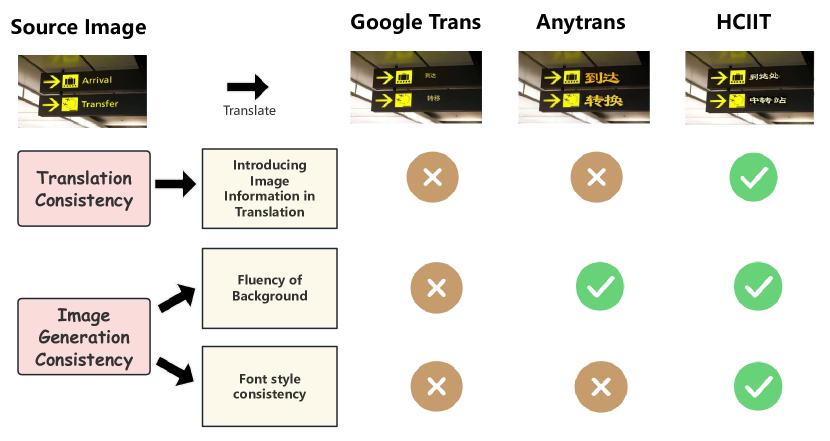
- 现有图像内翻译方法忽略了翻译一致性和图像生成一致性,导致翻译质量和图像逼真度下降。
- HCIIT框架通过多模态LLM进行文本翻译,并利用扩散模型进行风格一致的图像回填,保证一致性。
- 通过自建数据集训练,并在测试集上验证,HCIIT框架在一致性和翻译质量上均表现出色。
📝 摘要(中文)
图像内机器翻译任务涉及翻译图像中嵌入的文本,并将翻译结果以图像形式呈现。虽然此任务在电影海报翻译和日常场景图像翻译等多种场景中具有广泛应用,但现有方法经常忽略整个过程中的一致性。我们认为此任务需要维护两种类型的一致性:翻译一致性和图像生成一致性。前者需要在翻译过程中融入图像信息,而后者需要在文本图像的风格与原始图像之间保持一致性,确保背景完整性。为了满足这些一致性要求,我们提出了一种名为HCIIT(高一致性图像内翻译)的新型两阶段框架,该框架的第一阶段使用多模态多语言大型语言模型进行文本图像翻译,第二阶段使用扩散模型进行图像回填。第一阶段采用思维链学习,以增强模型在翻译过程中利用图像信息的能力。随后,经过风格一致的文本图像生成训练的扩散模型可确保图像中文本风格的统一性,并保留背景细节。我们还整理了一个包含40万个风格一致的伪文本图像对的数据集用于模型训练。在精心设计的测试集和真实图像测试集上获得的结果验证了我们的框架在确保一致性和生成高质量翻译图像方面的有效性。
🔬 方法详解
问题定义:图像内机器翻译旨在将图像中的文本翻译成另一种语言,并保持图像的整体视觉效果。现有方法的痛点在于难以同时保证翻译的准确性(翻译一致性)和生成图像的真实感(图像生成一致性)。具体来说,现有方法可能忽略图像上下文信息进行翻译,导致语义不一致;或者生成的文本与原始图像的风格不匹配,背景出现扭曲或缺失。
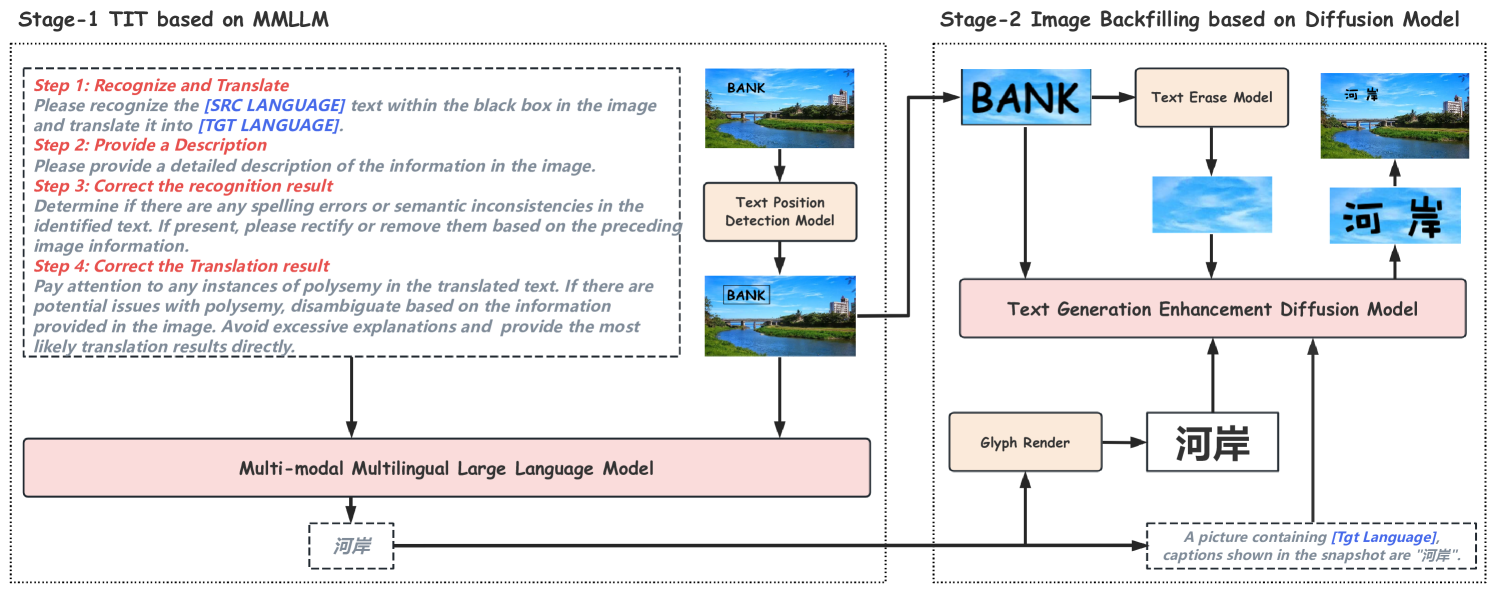
核心思路:HCIIT框架的核心思路是将图像内翻译任务分解为两个阶段:首先,利用多模态大型语言模型(LLM)进行文本翻译,同时考虑图像信息以保证翻译一致性;然后,使用扩散模型进行图像回填,以确保生成文本的风格与原始图像一致,并保持背景的完整性。这种两阶段解耦的设计允许针对每个阶段采用最适合的技术,从而更好地解决一致性问题。
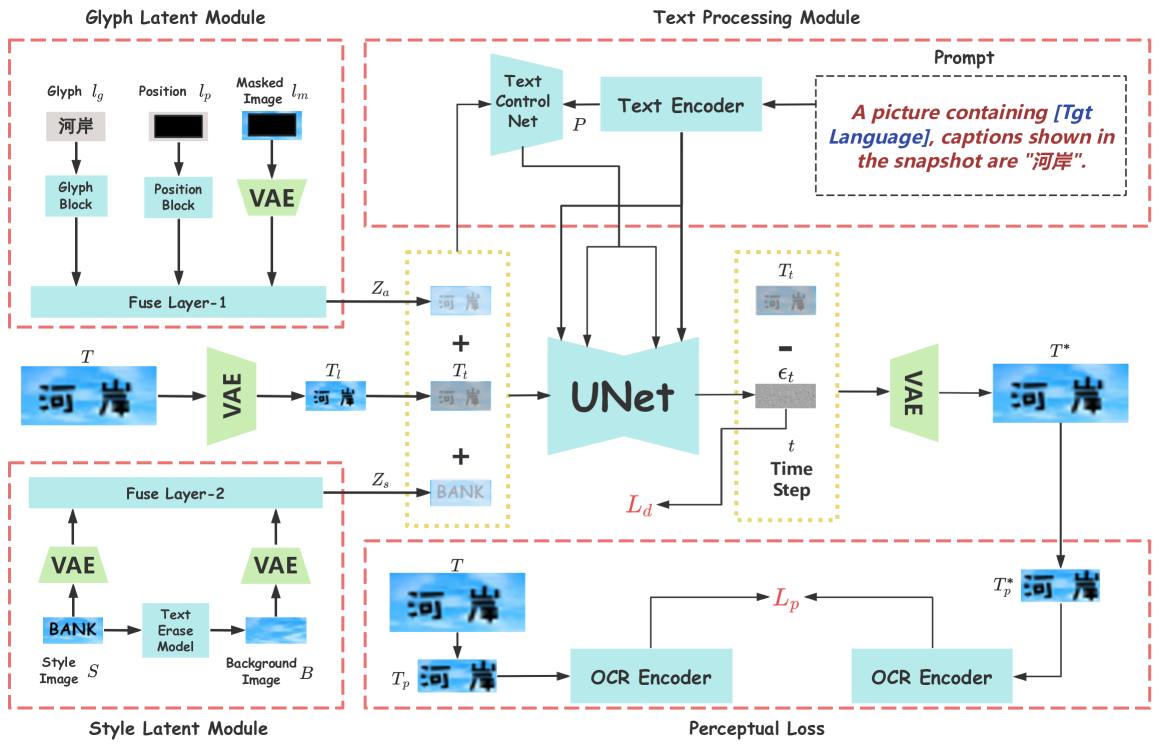
技术框架:HCIIT框架包含两个主要阶段: 1. 文本图像翻译阶段:使用多模态多语言LLM,输入包括原始图像和需要翻译的文本区域,输出为翻译后的文本。 2. 图像回填阶段:使用扩散模型,输入包括原始图像和翻译后的文本,输出为包含翻译后文本的图像。扩散模型负责将翻译后的文本无缝地融入到原始图像中,并保持风格一致性。
关键创新:HCIIT框架的关键创新在于: 1. 两阶段解耦:将翻译和图像生成解耦,允许针对每个阶段采用最适合的技术。 2. 多模态LLM与思维链学习:利用多模态LLM在翻译过程中融入图像信息,并通过思维链学习增强模型利用图像信息的能力。 3. 风格一致的扩散模型:使用专门训练的扩散模型进行图像回填,确保生成文本的风格与原始图像一致,并保持背景的完整性。
关键设计: 1. 多模态LLM:具体使用的LLM架构未知,但强调了多模态输入(图像和文本)和多语言支持。 2. 思维链学习:通过思维链学习,引导LLM逐步推理,从而更好地利用图像信息进行翻译。 3. 扩散模型训练:使用包含40万个风格一致的伪文本图像对的数据集训练扩散模型,以确保生成图像的风格一致性。 4. 损失函数:论文中未明确提及具体的损失函数设计,但推测可能包括用于保证翻译准确性的损失函数和用于保证图像生成质量的损失函数。
🖼️ 关键图片
📊 实验亮点
HCIIT框架在自建的测试集和真实图像测试集上都取得了显著的成果。实验结果表明,HCIIT框架能够有效地保证翻译一致性和图像生成一致性,生成高质量的翻译图像。具体的性能数据和对比基线在摘要中没有明确给出,但强调了该框架在一致性和翻译质量方面的优越性。自建数据集包含40万风格一致的伪文本图像对,为模型训练提供了充足的数据支持。
🎯 应用场景
HCIIT框架在电影海报翻译、商品标签翻译、街景图像翻译等领域具有广泛的应用前景。它可以帮助用户快速准确地理解外语图像内容,促进跨文化交流和信息共享。此外,该技术还可以应用于增强现实(AR)和虚拟现实(VR)等领域,为用户提供更沉浸式的翻译体验。未来,该技术有望进一步发展,实现更智能、更自然的图像内翻译。
📄 摘要(原文)
The in-image machine translation task involves translating text embedded within images, with the translated results presented in image format. While this task has numerous applications in various scenarios such as film poster translation and everyday scene image translation, existing methods frequently neglect the aspect of consistency throughout this process. We propose the need to uphold two types of consistency in this task: translation consistency and image generation consistency. The former entails incorporating image information during translation, while the latter involves maintaining consistency between the style of the text-image and the original image, ensuring background integrity. To address these consistency requirements, we introduce a novel two-stage framework named HCIIT (High-Consistency In-Image Translation) which involves text-image translation using a multimodal multilingual large language model in the first stage and image backfilling with a diffusion model in the second stage. Chain of thought learning is utilized in the first stage to enhance the model's ability to leverage image information during translation. Subsequently, a diffusion model trained for style-consistent text-image generation ensures uniformity in text style within images and preserves background details. A dataset comprising 400,000 style-consistent pseudo text-image pairs is curated for model training. Results obtained on both curated test sets and authentic image test sets validate the effectiveness of our framework in ensuring consistency and producing high-quality translated images.