Improving Factuality with Explicit Working Memory
作者: Mingda Chen, Yang Li, Karthik Padthe, Rulin Shao, Alicia Sun, Luke Zettlemoyer, Gargi Ghosh, Wen-tau Yih
分类: cs.CL
发布日期: 2024-12-24 (更新: 2025-06-02)
备注: ACL 2025 Camera Ready
💡 一句话要点
提出EWE:通过显式工作记忆提升长文本生成的事实准确性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本生成 事实性 检索增强生成 工作记忆 幻觉问题
📋 核心要点
- 现有检索增强生成(RAG)方法在长文本生成中存在事实性问题,受限于传统RAG的设计。
- EWE通过引入显式工作记忆,并根据外部反馈实时刷新记忆,从而纠正生成过程中的错误。
- 实验结果表明,EWE在多个数据集上显著提升了生成文本的事实准确性,且不影响文本的有用性。
📝 摘要(中文)
大型语言模型会生成事实不准确的内容,即产生幻觉。为了解决这个问题,现有工作基于检索增强生成(RAG)通过迭代提示来提高事实性,但这些方法受到传统RAG设计的限制。本文提出了一种新方法EWE(显式工作记忆),通过集成一个接收来自外部资源实时反馈的工作记忆来增强长文本生成的事实性。该记忆基于在线事实核查和检索反馈进行刷新,使EWE能够在生成过程中纠正错误的主张,并确保更准确和可靠的输出。实验表明,EWE在四个事实性长文本生成数据集上优于强大的基线,在不牺牲响应的有用性的前提下,将事实性指标VeriScore提高了2到6个绝对点。进一步的分析表明,记忆更新规则的设计、记忆单元的配置以及检索数据存储的质量是影响模型性能的关键因素。
🔬 方法详解
问题定义:现有的大型语言模型在生成长文本时,容易出现“幻觉”问题,即生成与事实不符的内容。传统的检索增强生成(RAG)方法虽然可以引入外部知识,但其迭代提示的方式仍然存在局限性,无法有效地纠正生成过程中的错误信息。因此,如何提高长文本生成的事实准确性是一个亟待解决的问题。
核心思路:EWE的核心思路是引入一个显式的工作记忆,该记忆可以接收来自外部资源的实时反馈,并根据这些反馈进行更新。通过这种方式,模型可以在生成过程中不断地检查和纠正自己的错误,从而提高生成文本的事实准确性。这种设计模拟了人类在写作或思考时,会不断地查阅资料、验证信息,并根据新的信息来调整自己的观点。
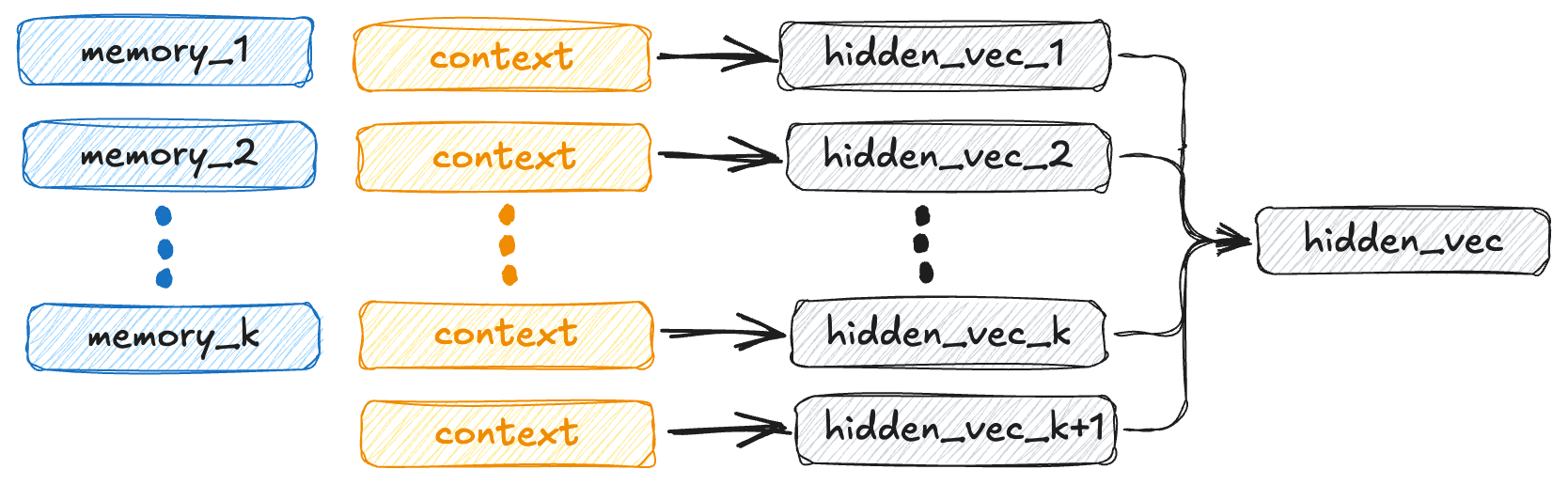
技术框架:EWE的整体框架包含以下几个主要模块:1) 文本生成器:负责生成长文本内容。2) 工作记忆:存储当前生成过程中的关键信息,并接收来自外部资源的反馈。3) 事实核查器:用于验证生成文本的事实准确性。4) 检索模块:用于从外部知识库中检索相关信息。5) 记忆更新模块:根据事实核查器和检索模块的反馈,更新工作记忆的内容。整个流程是,文本生成器生成文本,事实核查器和检索模块对文本进行验证和检索,记忆更新模块根据验证和检索结果更新工作记忆,然后文本生成器根据更新后的工作记忆继续生成文本。
关键创新:EWE最重要的技术创新点在于引入了显式的工作记忆,并将其与外部反馈机制相结合。与传统的RAG方法相比,EWE的工作记忆可以实时地接收和处理来自外部资源的反馈,从而更有效地纠正生成过程中的错误。此外,EWE的记忆更新机制也更加灵活,可以根据不同的反馈类型和重要性来调整记忆的内容。
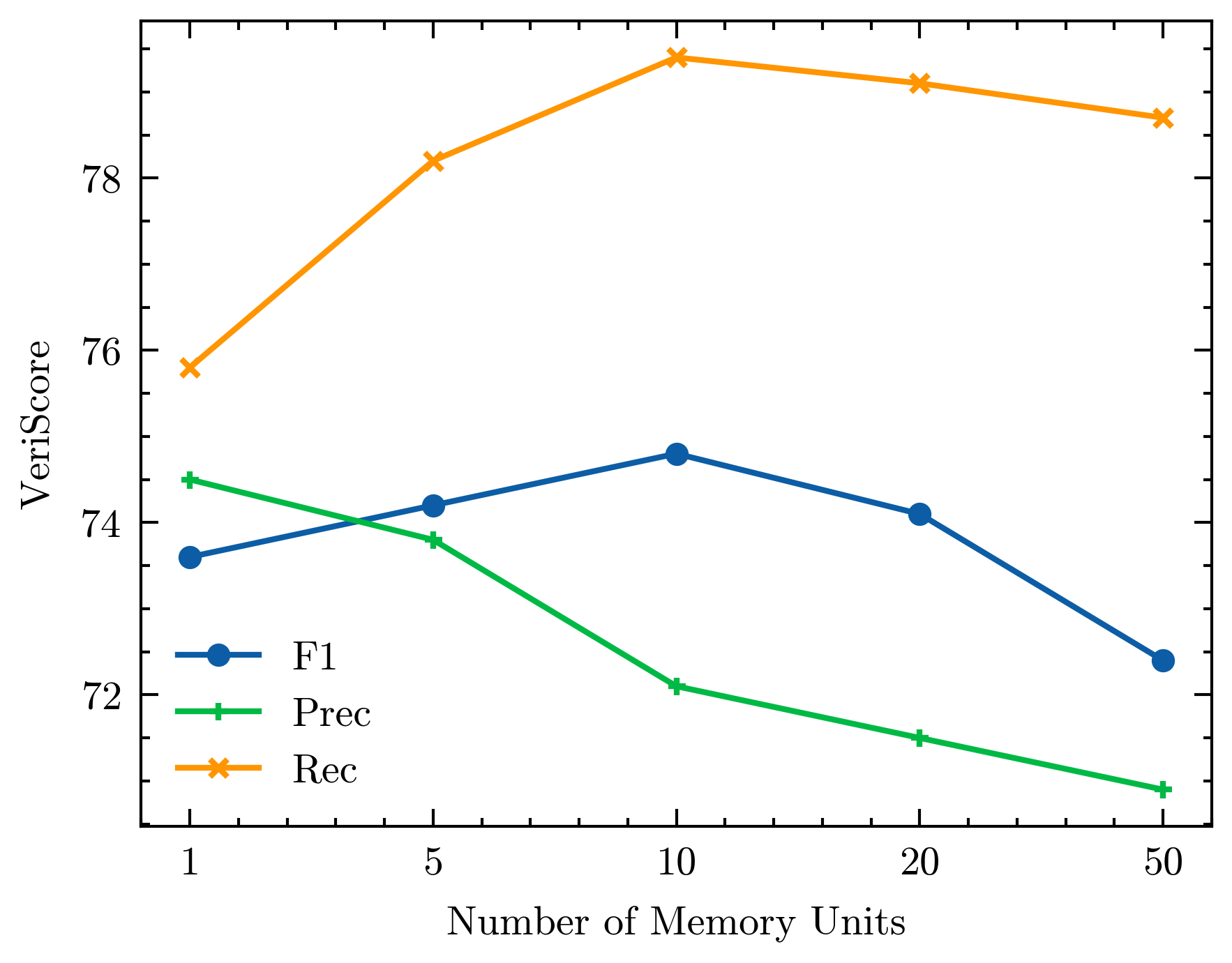
关键设计:EWE的关键设计包括:1) 记忆更新规则:定义了如何根据事实核查器和检索模块的反馈来更新工作记忆的内容。2) 记忆单元的配置:包括记忆单元的大小、数量和类型等。3) 检索数据存储的质量:高质量的检索数据存储可以提供更准确和可靠的外部知识,从而提高模型的事实准确性。论文中还探讨了不同的损失函数和网络结构对模型性能的影响,但没有给出具体的细节。
🖼️ 关键图片

📊 实验亮点
实验结果表明,EWE在四个事实性长文本生成数据集上优于强大的基线模型,将VeriScore指标提高了2到6个绝对点,同时保持了响应的有用性。这表明EWE能够有效地提高生成文本的事实准确性,并且不会牺牲文本的质量。
🎯 应用场景
EWE具有广泛的应用前景,可以应用于新闻报道、科学写作、法律文件生成等需要高度事实准确性的领域。通过提高生成文本的事实准确性,EWE可以帮助人们更有效地获取和利用信息,减少错误信息的传播,并提高决策的质量。未来,EWE还可以与其他技术相结合,例如知识图谱、自然语言推理等,以进一步提高其性能和应用范围。
📄 摘要(原文)
Large language models can generate factually inaccurate content, a problem known as hallucination. Recent works have built upon retrieved-augmented generation to improve factuality through iterative prompting but these methods are limited by the traditional RAG design. To address these challenges, we introduce EWE (Explicit Working Memory), a novel approach that enhances factuality in long-form text generation by integrating a working memory that receives real-time feedback from external resources. The memory is refreshed based on online fact-checking and retrieval feedback, allowing EWE to rectify false claims during the generation process and ensure more accurate and reliable outputs. Our experiments demonstrate that Ewe outperforms strong baselines on four fact-seeking long-form generation datasets, increasing the factuality metric, VeriScore, by 2 to 6 points absolute without sacrificing the helpfulness of the responses. Further analysis reveals that the design of rules for memory updates, configurations of memory units, and the quality of the retrieval datastore are crucial factors for influencing model performance.