Deliberation in Latent Space via Differentiable Cache Augmentation
作者: Luyang Liu, Jonas Pfeiffer, Jiaxing Wu, Jun Xie, Arthur Szlam
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-12-23
💡 一句话要点
提出基于可微缓存增强的潜在空间审议方法,提升LLM推理能力并降低延迟。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理增强 键值缓存 潜在空间 可微编程 离线协处理器 困惑度 语言建模
📋 核心要点
- 现有LLM推理方法生成离散token序列,导致延迟高且难以优化。
- 提出一种离线协处理器,通过潜在嵌入增强LLM的kv缓存,提升解码保真度。
- 实验表明,该方法能降低困惑度,提升推理密集型任务的性能,无需特定任务训练。
📝 摘要(中文)
本文提出了一种增强大型语言模型(LLM)推理能力的技术,通过生成并关注中间推理步骤来解决复杂问题。与标准方法直接生成离散token序列不同,本文利用一个离线协处理器来操作LLM的键值(kv)缓存。该协处理器通过一组潜在嵌入来增强缓存,旨在提高后续解码的保真度。协处理器使用来自解码器的语言建模损失在标准预训练数据上进行训练,同时保持解码器本身冻结。这种方法使模型能够以端到端可微的方式学习如何将额外的计算提炼到其kv缓存中。由于解码器保持不变,因此协处理器可以离线和异步运行。实验表明,当缓存被增强时,解码器在许多后续token上实现了较低的困惑度。即使没有任何特定于任务的训练,缓存增强也能持续降低困惑度并提高一系列推理密集型任务的性能。
🔬 方法详解
问题定义:现有大型语言模型在解决复杂推理问题时,通常采用生成中间推理步骤的方式,但这种方法直接生成离散token序列,导致推理延迟较高,并且优化过程较为困难。因此,如何提升LLM的推理能力,同时降低延迟,是一个亟待解决的问题。
核心思路:本文的核心思路是利用一个离线协处理器来增强LLM的键值(kv)缓存。通过在kv缓存中注入精心设计的潜在嵌入,使得模型在后续解码过程中能够获得更丰富的信息,从而提高解码的保真度。这种方法的核心在于将额外的计算负担转移到离线协处理器,从而避免了在线推理过程中的延迟。
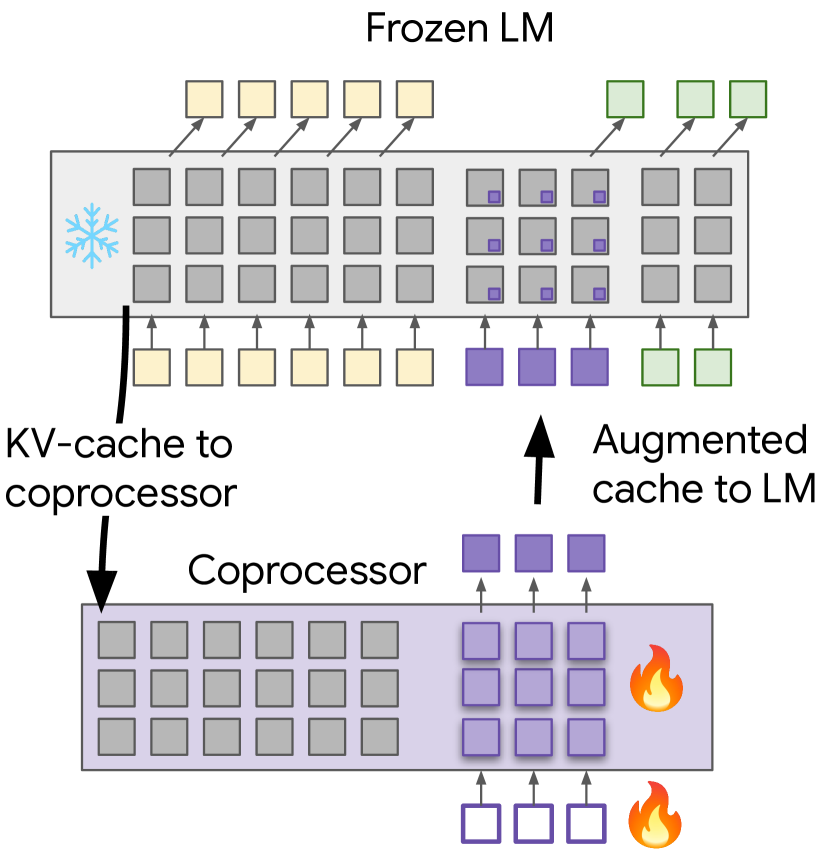
技术框架:整体框架包含一个冻结的LLM解码器和一个离线协处理器。协处理器首先接收LLM的kv缓存作为输入,然后生成一组潜在嵌入,并将这些嵌入添加到kv缓存中。增强后的kv缓存被传递给LLM解码器,用于生成最终的输出。协处理器与解码器是分离的,可以异步运行,从而避免了对在线推理过程的干扰。
关键创新:最重要的创新点在于引入了可微缓存增强的概念,通过一个离线协处理器来操作LLM的kv缓存。与传统的直接生成token序列的方法不同,本文的方法通过在潜在空间中进行审议,从而提高了推理效率和性能。此外,该方法还实现了端到端的可微训练,使得协处理器能够更好地适应LLM解码器的需求。
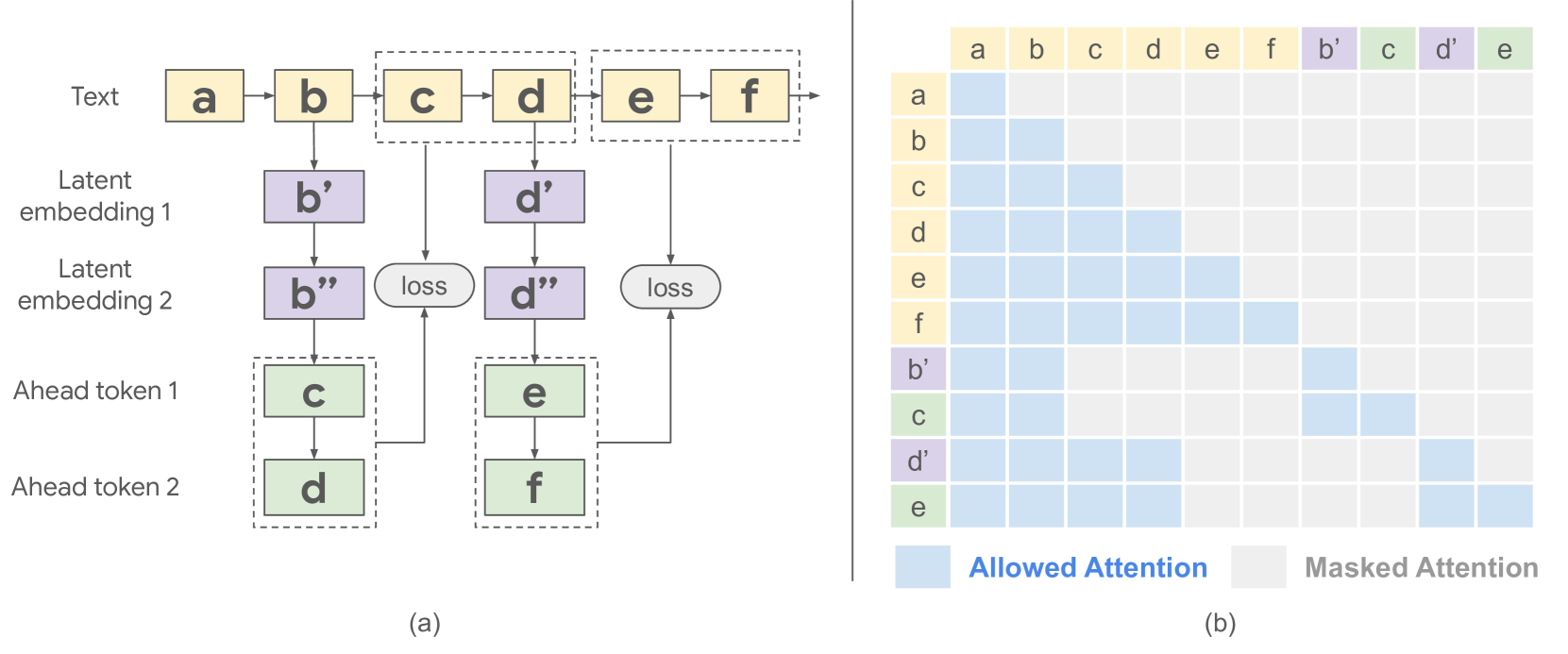
关键设计:协处理器使用语言建模损失进行训练,目标是最小化解码器在后续token上的困惑度。解码器本身保持冻结,以确保协处理器不会影响LLM的原始性能。潜在嵌入的维度和数量是关键的超参数,需要根据具体的任务进行调整。此外,还可以采用一些正则化技术来防止协处理器过度拟合训练数据。
🖼️ 关键图片
📊 实验亮点
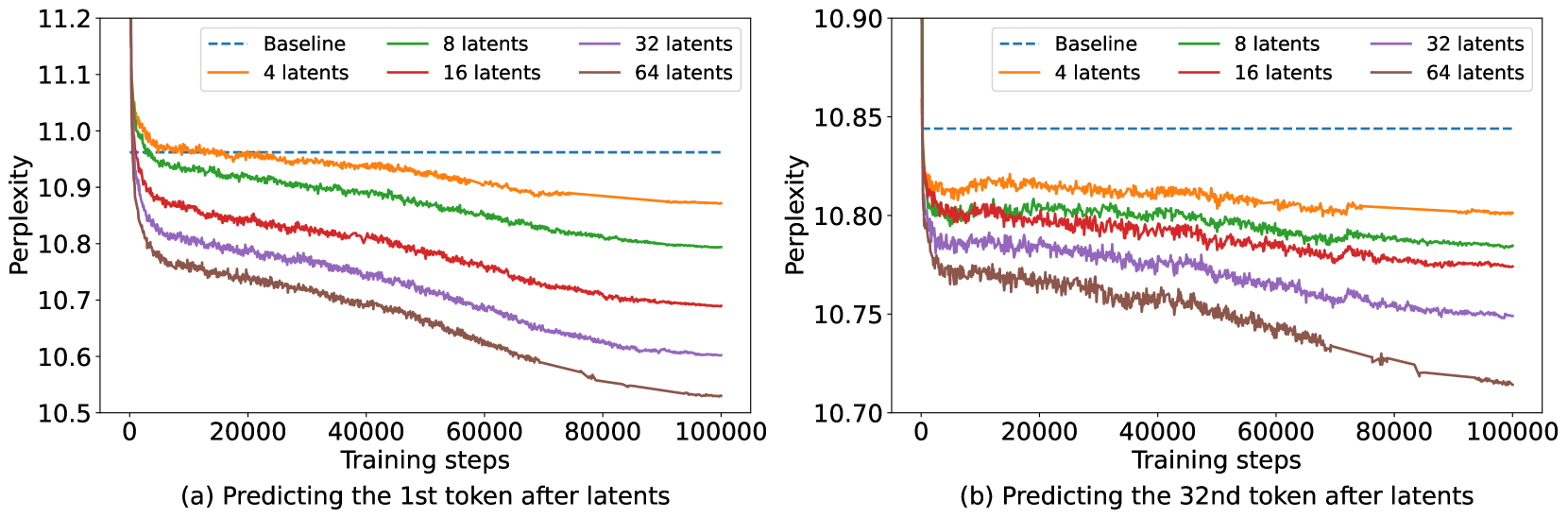
实验结果表明,通过缓存增强,解码器在多个后续token上实现了更低的困惑度。即使没有针对特定任务进行训练,缓存增强也能持续降低困惑度,并提高一系列推理密集型任务的性能。例如,在某些任务上,性能提升幅度达到了显著水平,证明了该方法的有效性。
🎯 应用场景
该研究成果可应用于各种需要复杂推理的场景,例如问答系统、对话生成、代码生成等。通过降低推理延迟和提高推理准确性,可以提升用户体验,并扩展LLM的应用范围。未来,该方法还可以与其他推理增强技术相结合,进一步提升LLM的性能。
📄 摘要(原文)
Techniques enabling large language models (LLMs) to "think more" by generating and attending to intermediate reasoning steps have shown promise in solving complex problems. However, the standard approaches generate sequences of discrete tokens immediately before responding, and so they can incur significant latency costs and be challenging to optimize. In this work, we demonstrate that a frozen LLM can be augmented with an offline coprocessor that operates on the model's key-value (kv) cache. This coprocessor augments the cache with a set of latent embeddings designed to improve the fidelity of subsequent decoding. We train this coprocessor using the language modeling loss from the decoder on standard pretraining data, while keeping the decoder itself frozen. This approach enables the model to learn, in an end-to-end differentiable fashion, how to distill additional computation into its kv-cache. Because the decoder remains unchanged, the coprocessor can operate offline and asynchronously, and the language model can function normally if the coprocessor is unavailable or if a given cache is deemed not to require extra computation. We show experimentally that when a cache is augmented, the decoder achieves lower perplexity on numerous subsequent tokens. Furthermore, even without any task-specific training, our experiments demonstrate that cache augmentation consistently reduces perplexity and improves performance across a range of reasoning-intensive tasks.