LiveIdeaBench: Evaluating LLMs' Divergent Thinking for Scientific Idea Generation with Minimal Context
作者: Kai Ruan, Xuan Wang, Jixiang Hong, Peng Wang, Yang Liu, Hao Sun
分类: cs.CL, cs.AI
发布日期: 2024-12-23 (更新: 2025-04-28)
备注: Updated manuscript and title
💡 一句话要点
LiveIdeaBench:通过单关键词提示评估LLM在科学构思中发散性思维能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 科学构思 发散性思维 基准测试 创造力评估
📋 核心要点
- 现有评估基准主要依赖丰富的上下文输入,缺乏对LLM在科学构思中发散性思维能力的有效评估。
- LiveIdeaBench通过单关键词提示,评估LLM在原创性、可行性、流畅性、灵活性和清晰度五个维度上的科学构思能力。
- 实验表明,LLM的科学构思能力与通用智能指标相关性弱,表明需要专门的训练策略来提升LLM的科学创造力。
📝 摘要(中文)
本文提出了LiveIdeaBench,一个综合性的基准测试,旨在评估大型语言模型(LLM)在科学构思方面的能力,通过使用单关键词提示来评估其发散性思维。该基准借鉴了吉尔福特的创造力理论,采用动态的先进LLM专家组来评估生成的想法,涵盖原创性、可行性、流畅性、灵活性和清晰度五个关键维度。通过对22个科学领域中1180个关键词的40多个领先模型进行广泛实验,结果表明,该基准测试所衡量的科学构思能力与通用智能的标准指标相关性较弱。研究发现,QwQ-32B-preview等模型在创造性表现上可与claude-3.7-sonnet:thinking等顶级模型相媲美,尽管它们在通用智能得分上存在显著差距。这些发现强调了针对科学构思的专门评估基准的必要性,并表明增强LLM的构思能力可能需要与提高通用问题解决能力不同的训练策略,从而为科学过程的不同阶段定制更广泛的AI工具。
🔬 方法详解
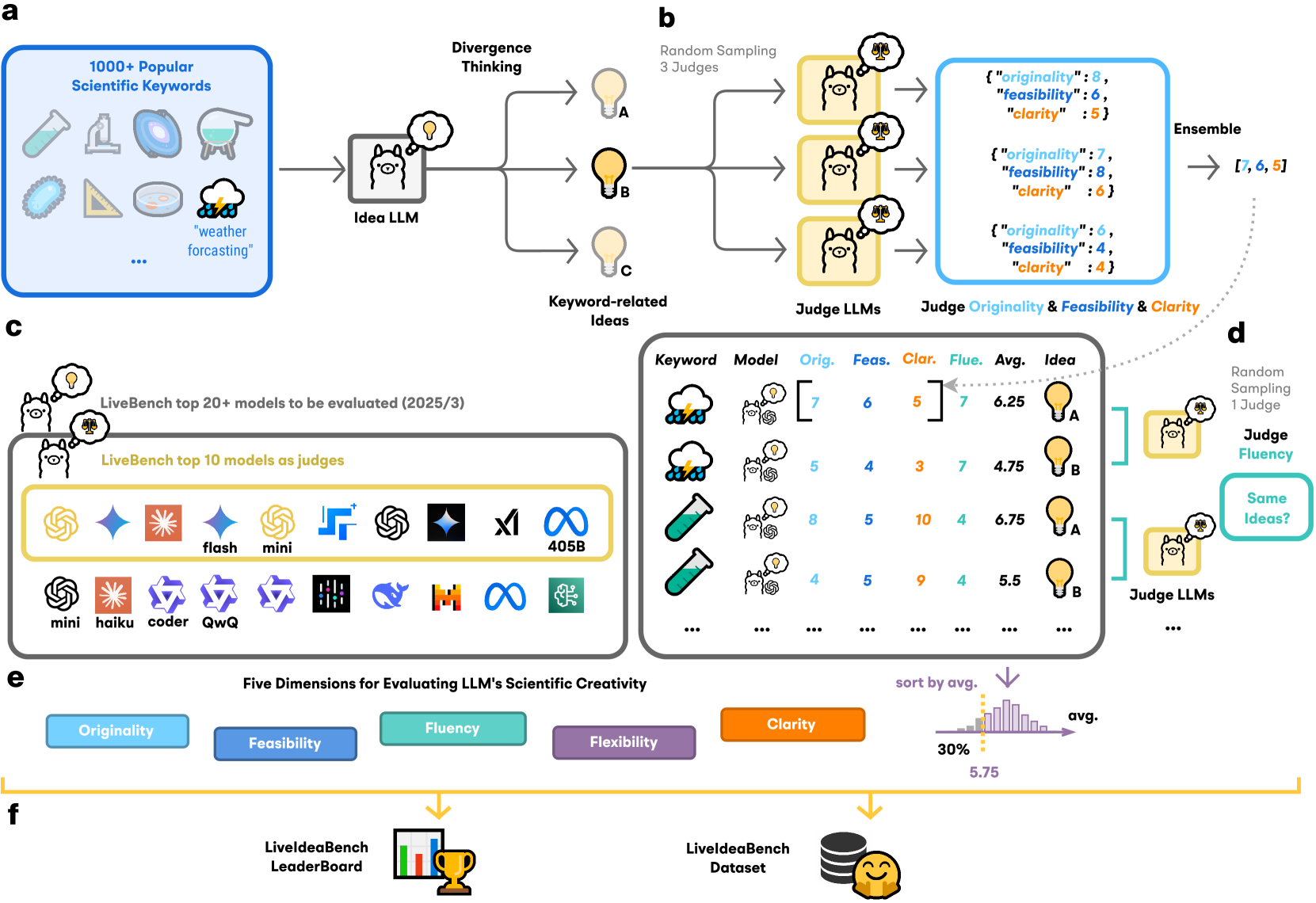
问题定义:现有的大型语言模型评估基准主要依赖于丰富的上下文信息,缺乏对LLM在科学构思中发散性思维能力的有效评估。这使得我们难以准确衡量LLM在科学研究早期阶段,例如头脑风暴和假设生成等方面的潜力。现有方法无法有效区分通用智能和科学创造力,阻碍了针对性地提升LLM在科学领域的应用能力。
核心思路:本文的核心思路是借鉴吉尔福特的创造力理论,设计一个基于单关键词提示的评估基准,专注于衡量LLM的发散性思维能力。通过减少上下文信息的依赖,更直接地考察LLM在给定简单提示下产生新颖、可行、流畅、灵活和清晰的科学想法的能力。这种设计旨在模拟科学家在研究初期,仅凭少量信息进行探索性思考的过程。
技术框架:LiveIdeaBench包含以下主要组成部分:1) 关键词库:涵盖22个科学领域的1180个关键词;2) LLM专家组:由多个先进的LLM组成,用于评估生成的想法;3) 评估维度:包括原创性、可行性、流畅性、灵活性和清晰度五个维度;4) 评估流程:LLM根据关键词生成想法,然后由LLM专家组对这些想法进行评估,最终得到每个LLM在各个维度上的得分。
关键创新:LiveIdeaBench的关键创新在于其评估方法,它使用动态的LLM专家组来评估生成的想法。与传统的静态评估方法相比,这种方法能够更全面、更客观地评估LLM的创造力。此外,该基准测试专注于评估LLM的发散性思维能力,这与现有基准测试主要关注的收敛性思维能力形成了鲜明对比。
关键设计:在评估维度方面,采用了吉尔福特创造力理论中的五个关键维度,并针对科学构思的特点进行了调整。在LLM专家组的构建上,选择了多个具有代表性的先进LLM,并设计了合理的评估流程,以确保评估结果的可靠性和有效性。具体参数设置和损失函数未在论文中详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LiveIdeaBench所衡量的科学构思能力与通用智能指标相关性较弱。例如,QwQ-32B-preview模型在创造性表现上可与claude-3.7-sonnet:thinking等顶级模型相媲美,尽管其通用智能得分较低。这表明,提升LLM的科学构思能力可能需要与提高通用问题解决能力不同的训练策略。
🎯 应用场景
LiveIdeaBench可用于评估和提升LLM在科学研究领域的应用能力,例如辅助科学家进行头脑风暴、生成新的研究假设、设计实验方案等。该基准测试的提出,有助于开发更智能、更高效的AI科研助手,加速科学发现的进程,并推动各学科领域的创新发展。
📄 摘要(原文)
While Large Language Models (LLMs) demonstrate remarkable capabilities in scientific tasks such as literature analysis and experimental design (e.g., accurately extracting key findings from papers or generating coherent experimental procedures), existing evaluation benchmarks primarily assess performance using rich contextual inputs. We introduce LiveIdeaBench, a comprehensive benchmark evaluating LLMs' scientific idea generation by assessing divergent thinking capabilities using single-keyword prompts. Drawing from Guilford's creativity theory, our benchmark employs a dynamic panel of state-of-the-art LLMs to assess generated ideas across five key dimensions: originality, feasibility, fluency, flexibility, and clarity. Through extensive experimentation with over 40 leading models across 1,180 keywords spanning 22 scientific domains, we reveal that the scientific idea generation capabilities measured by our benchmark, are poorly predicted by standard metrics of general intelligence. Our results demonstrate that models like QwQ-32B-preview achieve creative performance comparable to top-tier models such as claude-3.7-sonnet:thinking, despite significant gaps in their general intelligence scores. These findings highlight the need for specialized evaluation benchmarks for scientific idea generation and suggest that enhancing these idea generation capabilities in LLMs may require different training strategies than those used for improving general problem-solving abilities, potentially enabling a wider range of AI tools tailored for different stages of the scientific process.