DRT: Deep Reasoning Translation via Long Chain-of-Thought
作者: Jiaan Wang, Fandong Meng, Yunlong Liang, Jie Zhou
分类: cs.CL, cs.AI
发布日期: 2024-12-23 (更新: 2025-08-24)
备注: ACL 2025 Findings
🔗 代码/项目: GITHUB
💡 一句话要点
提出DRT:通过长链式思考进行深度推理翻译,提升隐喻和比喻句翻译质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器翻译 长链式思考 多智能体 比喻翻译 隐喻翻译 深度推理 神经机器翻译
📋 核心要点
- 现有神经机器翻译模型在处理包含比喻和隐喻的句子时,由于缺乏推理能力,难以准确捕捉原文含义。
- DRT通过多智能体框架模拟翻译过程中的长链式思考,利用翻译器、顾问和评估器协同工作,提升翻译质量。
- 实验结果表明,DRT模型在比喻和隐喻句子的翻译任务上,显著优于传统LLM和微调后的LLM。
📝 摘要(中文)
本文提出了DRT,旨在将长链式思考(CoT)的成功经验引入神经机器翻译(MT)领域。针对文学作品中常见的比喻和隐喻,由于文化差异,直接翻译往往难以有效传达原意。为了模拟大型语言模型(LLM)的长思考能力,我们首先从现有文学作品中挖掘包含比喻或隐喻的句子,然后开发了一个多智能体框架,通过长思考来翻译这些句子。在该框架中,翻译器在顾问的建议下迭代地翻译源句,并使用评估器量化每一轮的翻译质量,以确保长思考的有效性。由此,我们收集了数万条长思考的机器翻译数据,用于训练DRT。使用Qwen2.5和LLama-3.1作为骨干模型,DRT模型可以学习机器翻译过程中的思考过程,并且优于原始LLM以及简单地在配对句子上进行微调而没有长思考的LLM,证明了其有效性。合成数据和模型检查点已在https://github.com/krystalan/DRT上发布。
🔬 方法详解
问题定义:论文旨在解决神经机器翻译在处理文学作品中包含比喻、隐喻等复杂语义的句子时,由于缺乏推理能力而导致的翻译质量不高的问题。现有方法通常直接将源语言句子映射到目标语言句子,忽略了文化差异和深层语义理解,导致直译效果不佳。
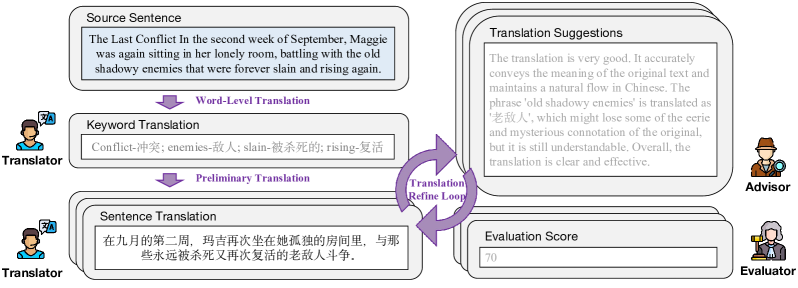
核心思路:论文的核心思路是借鉴大型语言模型在推理任务中使用的长链式思考(CoT)方法,模拟人类翻译员在翻译复杂句子时的思考过程。通过引入多个智能体协同工作,逐步分解翻译任务,并对中间结果进行评估和改进,从而提高翻译的准确性和流畅性。
技术框架:DRT采用多智能体框架,包含三个主要模块:翻译器(Translator)、顾问(Advisor)和评估器(Evaluator)。翻译器负责生成目标语言的翻译结果;顾问提供翻译建议,例如解释比喻的含义或提供更合适的表达方式;评估器评估翻译质量,并为翻译器和顾问提供反馈。这三个模块迭代工作,直到生成高质量的翻译结果。
关键创新:DRT的关键创新在于将长链式思考引入机器翻译领域,并设计了多智能体框架来实现这一思想。与传统的端到端翻译模型相比,DRT能够更好地理解源语言句子的深层语义,并生成更符合目标语言文化习惯的翻译结果。此外,DRT还通过数据合成的方式,构建了包含大量长思考过程的训练数据,为模型的训练提供了有力支持。
关键设计:论文使用Qwen2.5和LLama-3.1作为骨干模型,并对这些模型进行微调。在训练过程中,使用了合成的长思考数据,这些数据包含了翻译器、顾问和评估器之间的交互过程。损失函数的设计旨在鼓励翻译器生成高质量的翻译结果,并鼓励顾问提供有用的建议。具体的参数设置和网络结构细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片

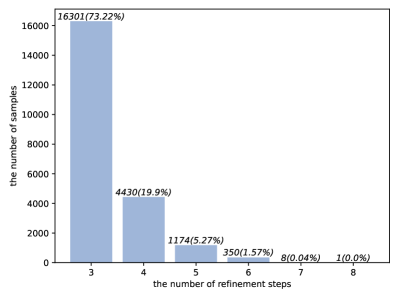
📊 实验亮点
实验结果表明,DRT模型在使用Qwen2.5和LLama-3.1作为骨干模型时,在比喻和隐喻句子的翻译任务上,显著优于原始LLM以及简单地在配对句子上进行微调而没有长思考的LLM。具体的性能数据和提升幅度在论文中没有明确给出,属于未知信息。
🎯 应用场景
DRT技术可应用于文学作品翻译、跨文化交流、教育等领域。通过提高机器翻译在处理复杂语义和文化差异方面的能力,DRT有助于促进不同文化之间的理解和交流。此外,DRT还可以作为辅助翻译工具,帮助人工翻译员提高工作效率和翻译质量。
📄 摘要(原文)
Recently, O1-like models have emerged as representative examples, illustrating the effectiveness of long chain-of-thought (CoT) in reasoning tasks such as math and coding tasks. In this paper, we introduce DRT, an attempt to bring the success of long CoT to neural machine translation (MT). Specifically, in view of the literature books that might involve similes and metaphors, translating these texts to a target language is very difficult in practice due to cultural differences. In such cases, literal translation often fails to convey the intended meaning effectively. Even for professional human translators, considerable thought must be given to preserving semantics throughout the translation process. To simulate LLMs' long thought ability in MT, we first mine sentences containing similes or metaphors from existing literature books, and then develop a multi-agent framework to translate these sentences via long thought. In the multi-agent framework, a translator is used to iteratively translate the source sentence under the suggestions provided by an advisor. To ensure the effectiveness of the long thoughts, an evaluator is also employed to quantify the translation quality in each round. In this way, we collect tens of thousands of long-thought MT data, which is used to train our DRT. Using Qwen2.5 and LLama-3.1 as the backbones, DRT models can learn the thought process during machine translation, and outperform vanilla LLMs as well as LLMs which are simply fine-tuning on the paired sentences without long thought, showing its effectiveness. The synthesized data and model checkpoints are released at https://github.com/krystalan/DRT.