Measuring Contextual Informativeness in Child-Directed Text
作者: Maria Valentini, Téa Wright, Ali Marashian, Jennifer Weber, Eliana Colunga, Katharina von der Wense
分类: cs.CL
发布日期: 2024-12-23
备注: COLING 2025 main conference short paper
💡 一句话要点
提出一种基于大型语言模型的方法,用于评估儿童故事中词汇的语境信息量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 儿童故事 语境信息量 大型语言模型 自然语言处理 教育内容生成
📋 核心要点
- 现有方法在评估儿童故事中词汇的语境信息量方面存在不足,这限制了教育内容的自动生成。
- 论文提出利用大型语言模型(LLM)来自动化评估儿童故事中目标词汇的语境信息量,从而更好地传达词汇语义。
- 实验结果表明,该方法在衡量儿童和成人文本的语境信息量方面均优于现有基线方法,Spearman相关系数最高达到0.4983。
📝 摘要(中文)
为了解决儿童词汇丰富故事创作中的一个重要缺口,我们研究了如何自动评估故事传达目标词汇语义的能力。这项任务对于生成教育内容具有重要意义,我们称之为衡量儿童故事中的语境信息量。我们为此任务提供了正式的任务定义和一个数据集。此外,我们提出了一种使用大型语言模型(LLM)自动执行该任务的方法。实验表明,我们的方法与人类对信息量的判断达到了0.4983的Spearman相关系数,而最强的基线仅获得0.3534的相关系数。进一步的分析表明,基于LLM的方法能够推广到衡量成人文本中的语境信息量,并且也优于所有基线。
🔬 方法详解
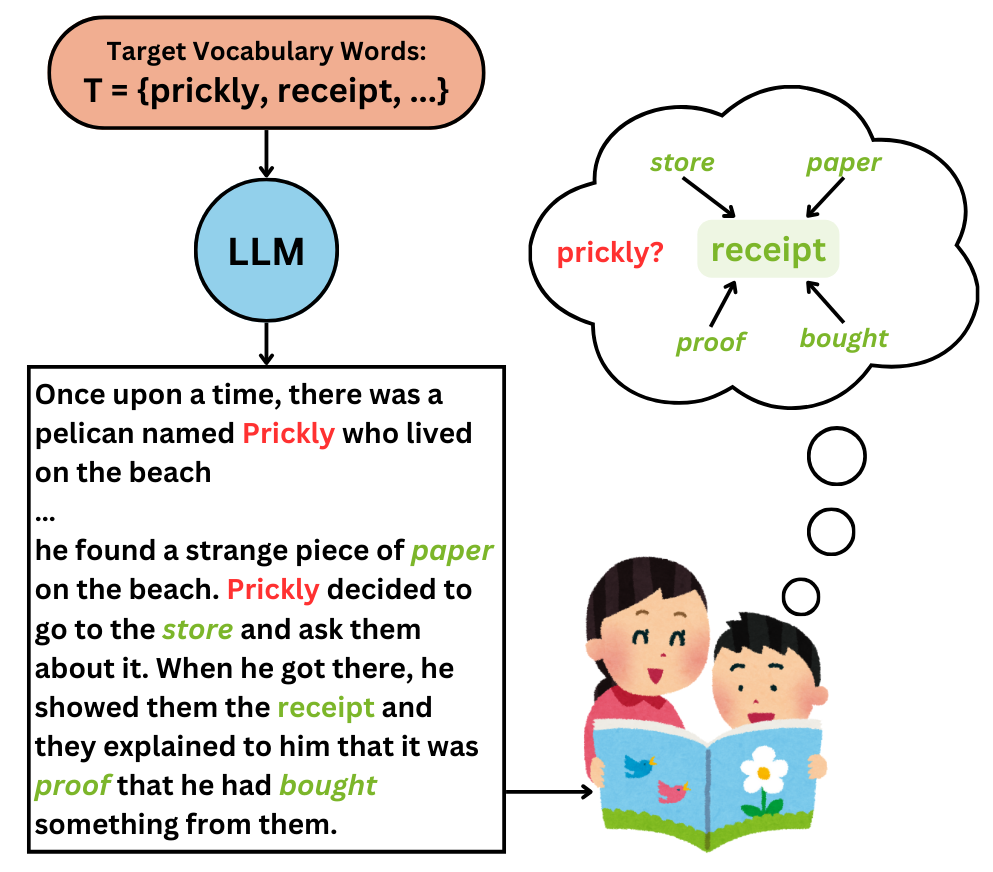
问题定义:论文旨在解决如何自动评估儿童故事中目标词汇的语境信息量的问题。现有方法缺乏有效手段来衡量故事在多大程度上能够帮助儿童理解和学习新的词汇。这使得自动生成高质量的、具有词汇丰富功能的儿童故事变得困难。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大语义理解能力,让LLM来判断给定的故事片段是否能够有效地传达目标词汇的含义。LLM可以模拟人类的理解过程,从而对语境信息量进行评估。
技术框架:该方法主要包含以下步骤:1) 构建一个包含儿童故事和目标词汇的数据集,并由人工标注语境信息量;2) 使用LLM对每个故事片段进行编码,提取其语义特征;3) 将提取的语义特征输入到一个回归模型中,预测该故事片段的语境信息量;4) 使用标注数据训练回归模型,使其能够准确预测语境信息量。
关键创新:该方法最重要的创新点在于将大型语言模型应用于评估儿童故事的语境信息量。与传统的基于规则或统计的方法相比,LLM能够更好地理解故事的语义,从而更准确地评估语境信息量。此外,该方法还能够推广到评估成人文本的语境信息量。
关键设计:论文中使用了预训练的语言模型作为LLM,并针对语境信息量评估任务进行了微调。回归模型可以使用简单的线性回归或更复杂的神经网络。损失函数可以选择均方误差或Huber损失等。关键在于如何有效地利用LLM的语义表示能力,并将其与语境信息量联系起来。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在衡量儿童故事的语境信息量方面取得了显著的成果。与最强的基线方法相比,该方法的Spearman相关系数提高了约41%(从0.3534到0.4983)。此外,该方法还能够推广到衡量成人文本的语境信息量,并且也优于所有基线,表明了该方法的泛化能力。
🎯 应用场景
该研究成果可应用于自动生成儿童教育内容,例如词汇学习故事、阅读理解材料等。通过自动评估语境信息量,可以帮助创作者生成更有效的、能够帮助儿童学习新词汇的故事。此外,该方法还可以应用于评估现有儿童读物的质量,为家长和教师提供参考。
📄 摘要(原文)
To address an important gap in creating children's stories for vocabulary enrichment, we investigate the automatic evaluation of how well stories convey the semantics of target vocabulary words, a task with substantial implications for generating educational content. We motivate this task, which we call measuring contextual informativeness in children's stories, and provide a formal task definition as well as a dataset for the task. We further propose a method for automating the task using a large language model (LLM). Our experiments show that our approach reaches a Spearman correlation of 0.4983 with human judgments of informativeness, while the strongest baseline only obtains a correlation of 0.3534. An additional analysis shows that the LLM-based approach is able to generalize to measuring contextual informativeness in adult-directed text, on which it also outperforms all baselines.