Interweaving Memories of a Siamese Large Language Model
作者: Xin Song, Zhikai Xue, Guoxiu He, Jiawei Liu, Wei Lu
分类: cs.CL
发布日期: 2024-12-23
备注: Accepted by AAAI 2025 Main Conference
💡 一句话要点
提出IMSM框架,通过交织Siamese LLM的记忆来缓解PEFT中的灾难性遗忘问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 参数高效微调 灾难性遗忘 Siamese网络 知识保留
📋 核心要点
- PEFT方法在优化LLM时易发生灾难性遗忘,导致模型丢失原始知识。
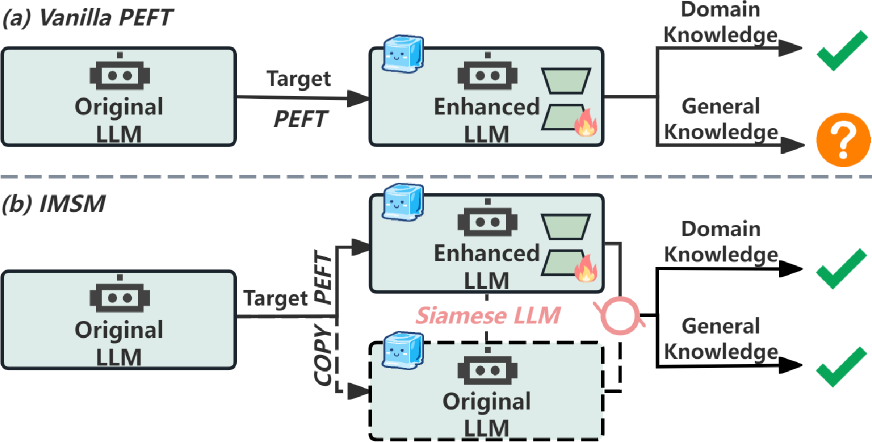
- IMSM框架通过Siamese LLM生成并交织预训练和微调后的记忆,从而保留原始知识。
- 实验表明,IMSM在保持效率的同时,显著提升了性能并有效缓解了灾难性遗忘。
📝 摘要(中文)
参数高效微调(PEFT)方法通过修改或引入少量参数来优化大型语言模型(LLM),以增强其在下游任务上的对齐。然而,这可能导致灾难性遗忘,即LLM优先考虑新知识而牺牲了全面的世界知识。一个有希望的缓解方法是回忆基于原始知识的先前记忆。为此,我们提出了一个模型无关的PEFT框架IMSM,它交织了Siamese LLM的记忆。具体来说,我们的Siamese LLM配备了现有的PEFT方法。给定一个传入的查询,它基于预训练和微调的参数生成两个不同的记忆。然后,IMSM结合了一种交织机制,该机制调节原始记忆和增强记忆在生成下一个token时的贡献。该框架在理论上适用于所有开源LLM和现有的PEFT方法。我们跨各种基准数据集进行了广泛的实验,评估了使用所提出的IMSM的流行开源LLM的性能,并将其与经典和领先的PEFT方法进行了比较。我们的研究结果表明,IMSM保持了与骨干PEFT方法相当的时间和空间效率,同时显著提高了性能并有效缓解了灾难性遗忘。
🔬 方法详解
问题定义:PEFT方法虽然能高效地使LLM适应下游任务,但容易导致灾难性遗忘,即模型在学习新知识的同时,会忘记或弱化原有的通用知识。现有方法难以在适应新任务和保持原有知识之间取得平衡。
核心思路:IMSM的核心思路是利用Siamese LLM同时维护两组参数:预训练参数和微调参数。对于每个输入,模型分别基于这两组参数生成两个记忆,分别代表原始知识和任务特定知识。然后,通过一个交织机制,动态地融合这两个记忆,从而在生成token时兼顾原始知识和新知识。
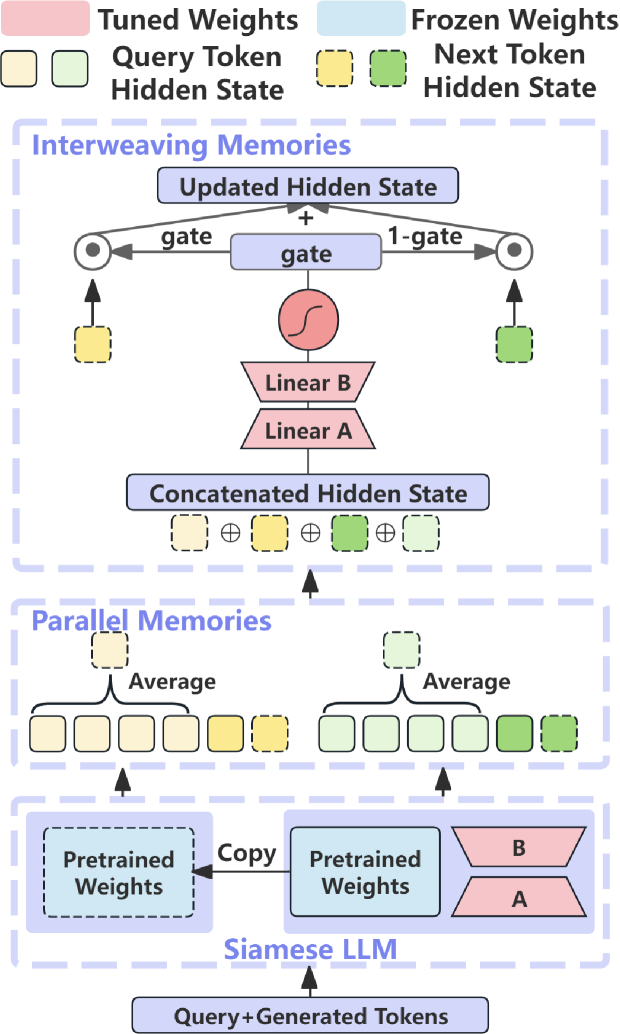
技术框架:IMSM框架包含以下几个主要模块:1) Siamese LLM:包含两组参数,分别对应预训练模型和微调模型。2) 记忆生成器:基于两组参数,为每个输入生成两个记忆。3) 交织机制:根据当前状态,动态地调整两个记忆的权重,并将它们融合。4) Token生成器:基于融合后的记忆,生成下一个token。整个流程是模型接收输入,Siamese LLM生成两个记忆,交织机制融合记忆,最后生成token。
关键创新:IMSM的关键创新在于其交织机制,它能够动态地平衡原始知识和任务特定知识的贡献。与传统的PEFT方法相比,IMSM不是简单地替换或修改原始参数,而是保留了原始参数,并通过交织机制来利用它们。这种方法能够更有效地缓解灾难性遗忘。
关键设计:交织机制的具体实现可能涉及多种方法,例如,可以使用一个门控网络来控制两个记忆的权重。损失函数可以包括任务相关的损失和知识保留相关的损失。具体的网络结构和参数设置需要根据具体的LLM和任务进行调整。论文中可能使用了某种特定的交织策略,但摘要中未明确说明。
🖼️ 关键图片
📊 实验亮点
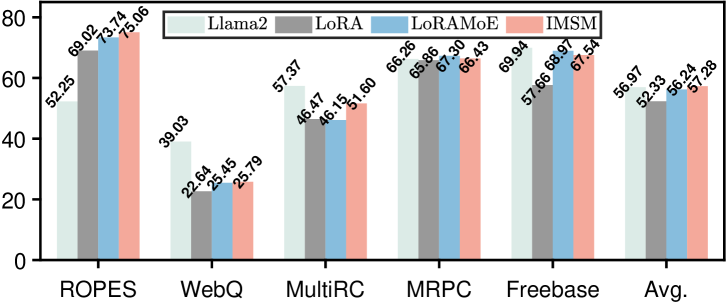
实验结果表明,IMSM在多个基准数据集上显著优于传统的PEFT方法,并且在时间和空间效率上与骨干PEFT方法相当。这意味着IMSM能够在不显著增加计算成本的情况下,有效地缓解灾难性遗忘,并提高LLM的性能。具体的性能提升幅度未知,需要在论文中查找。
🎯 应用场景
IMSM框架可广泛应用于需要持续学习和知识保留的场景,例如:智能客服、知识图谱问答、医疗诊断等。通过缓解灾难性遗忘,IMSM可以使LLM在适应新任务的同时,保持其原有的通用知识,从而提高模型的可靠性和泛化能力。该研究对于提升LLM在实际应用中的性能具有重要意义。
📄 摘要(原文)
Parameter-efficient fine-tuning (PEFT) methods optimize large language models (LLMs) by modifying or introducing a small number of parameters to enhance alignment with downstream tasks. However, they can result in catastrophic forgetting, where LLMs prioritize new knowledge at the expense of comprehensive world knowledge. A promising approach to mitigate this issue is to recall prior memories based on the original knowledge. To this end, we propose a model-agnostic PEFT framework, IMSM, which Interweaves Memories of a Siamese Large Language Model. Specifically, our siamese LLM is equipped with an existing PEFT method. Given an incoming query, it generates two distinct memories based on the pre-trained and fine-tuned parameters. IMSM then incorporates an interweaving mechanism that regulates the contributions of both original and enhanced memories when generating the next token. This framework is theoretically applicable to all open-source LLMs and existing PEFT methods. We conduct extensive experiments across various benchmark datasets, evaluating the performance of popular open-source LLMs using the proposed IMSM, in comparison to both classical and leading PEFT methods. Our findings indicate that IMSM maintains comparable time and space efficiency to backbone PEFT methods while significantly improving performance and effectively mitigating catastrophic forgetting.