Teaching LLMs to Refine with Tools
作者: Dian Yu, Yuheng Zhang, Jiahao Xu, Tian Liang, Linfeng Song, Zhaopeng Tu, Haitao Mi, Dong Yu
分类: cs.CL
发布日期: 2024-12-22
💡 一句话要点
提出CaP方法,利用外部工具优化LLM的CoT推理,实现跨推理方式的有效改进。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 思维链 工具使用 偏好优化 推理改进
📋 核心要点
- 现有LLM改进方法局限于同一推理格式,难以纠正深层错误,限制了自我提升能力。
- CaP方法利用外部工具,对LLM的CoT推理进行优化,实现跨推理方式的有效改进。
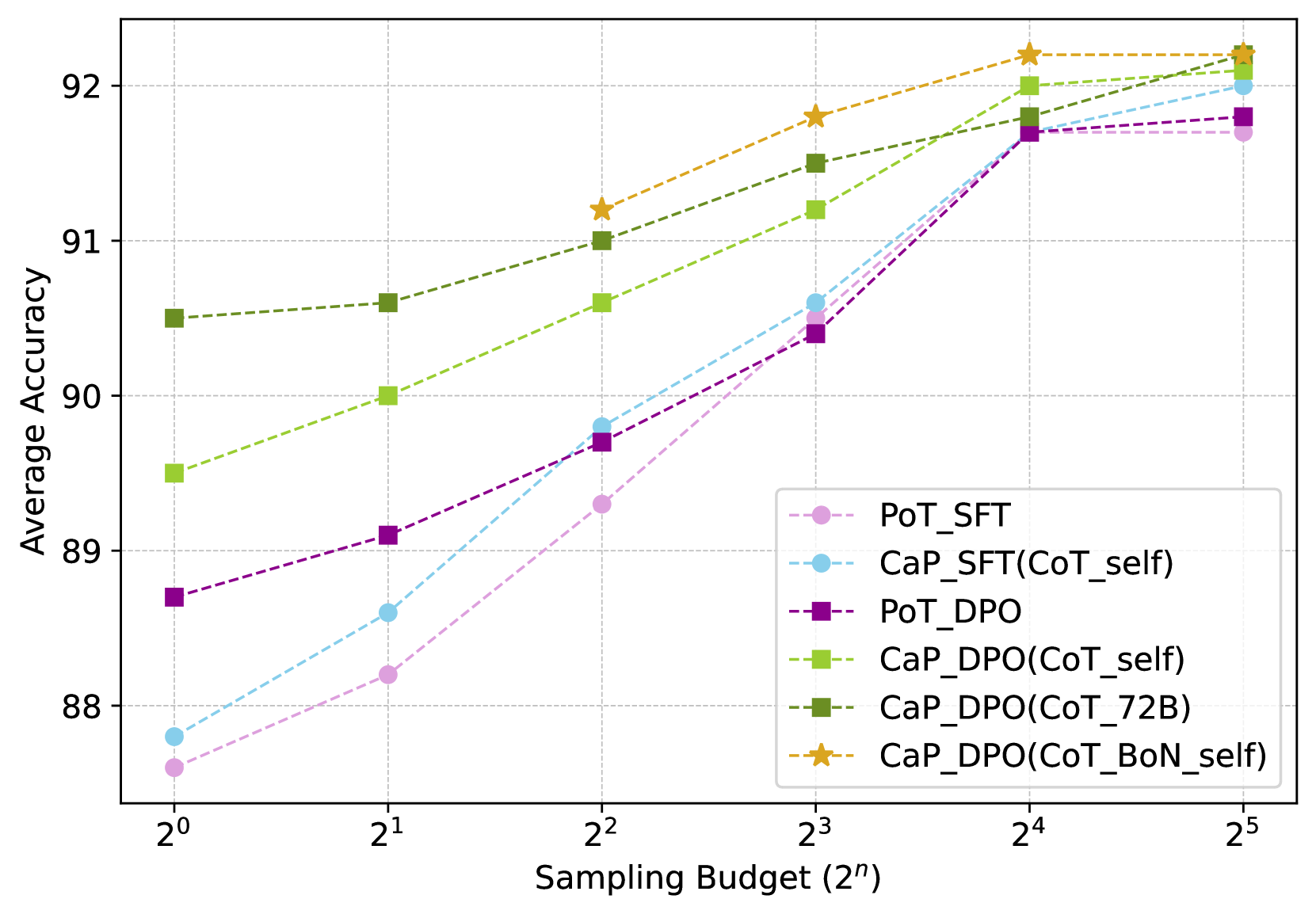
- 实验结果表明,CaP方法在跨推理改进和高效推理方面具有潜力,偏好优化至关重要。
📝 摘要(中文)
大型语言模型(LLMs)能够基于反馈改进其响应,通过迭代训练或测试时优化实现自我提升。然而,现有方法主要关注同一推理格式内的改进,可能导致无法纠正错误。我们提出CaP,一种新颖的方法,它使用外部工具来改进由相同或不同LLM生成的思维链(CoT)响应。CaP采用两阶段训练过程:监督式微调,然后是使用DPO变体的偏好优化。我们的观察强调了偏好优化在实现有效改进中的关键作用。此外,我们比较了几种采样策略,以在推理时利用CoT和工具。实验结果表明CaP在有效跨推理改进和高效推理方面的潜力。
🔬 方法详解
问题定义:现有的大型语言模型在进行自我改进时,通常局限于在相同的推理格式下进行优化。这种方式的局限性在于,如果初始的推理过程存在根本性的错误,那么后续的改进也难以纠正这些错误,导致模型无法真正提升其解决问题的能力。因此,如何让LLM能够利用不同的推理方式,并借助外部工具来发现和纠正自身错误,是一个亟待解决的问题。
核心思路:CaP方法的核心思路是利用外部工具来辅助LLM进行推理改进。具体来说,CaP首先让LLM生成一个基于思维链(CoT)的初始答案,然后利用外部工具(例如计算器、搜索引擎等)来验证或修正这个答案。通过比较初始答案和工具辅助下的答案,LLM可以学习到如何更好地利用工具来改进其推理过程。这种跨推理方式的改进能够更有效地纠正LLM的错误,提升其解决问题的能力。
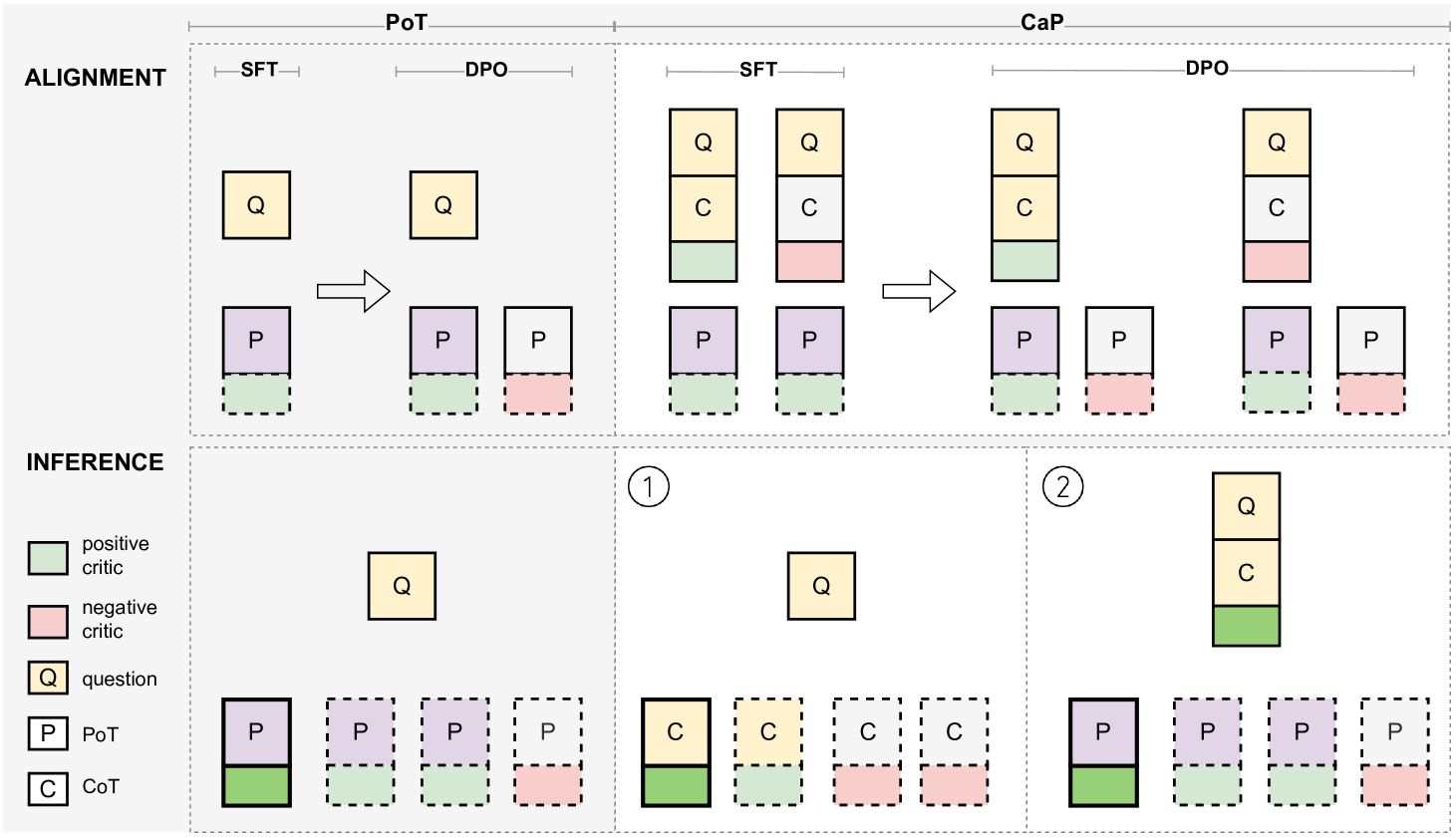
技术框架:CaP方法的技术框架主要包括两个阶段:监督式微调(SFT)和偏好优化。在SFT阶段,CaP使用标注数据对LLM进行微调,使其能够生成高质量的CoT推理过程和利用工具进行验证。在偏好优化阶段,CaP使用DPO(Direct Preference Optimization)的变体来训练LLM,使其能够区分不同的推理过程的优劣,并选择更有效的推理方式。在推理阶段,CaP采用不同的采样策略,例如只使用CoT、只使用工具、或者结合CoT和工具,来生成最终的答案。
关键创新:CaP方法最重要的技术创新点在于它实现了跨推理方式的改进。与以往的方法只关注同一推理格式内的改进不同,CaP利用外部工具来辅助LLM进行推理,从而能够更有效地纠正LLM的错误。此外,CaP还采用了偏好优化技术,使得LLM能够学习到如何更好地利用工具来改进其推理过程。
关键设计:CaP的关键设计包括以下几个方面:1) 使用CoT作为初始推理方式,CoT能够提供更清晰的推理过程,方便LLM进行改进;2) 使用外部工具来验证或修正CoT推理过程,工具能够提供更准确的答案,帮助LLM发现错误;3) 采用DPO变体进行偏好优化,DPO能够更有效地训练LLM,使其能够区分不同的推理过程的优劣;4) 设计不同的采样策略,例如只使用CoT、只使用工具、或者结合CoT和工具,来生成最终的答案。
🖼️ 关键图片
📊 实验亮点
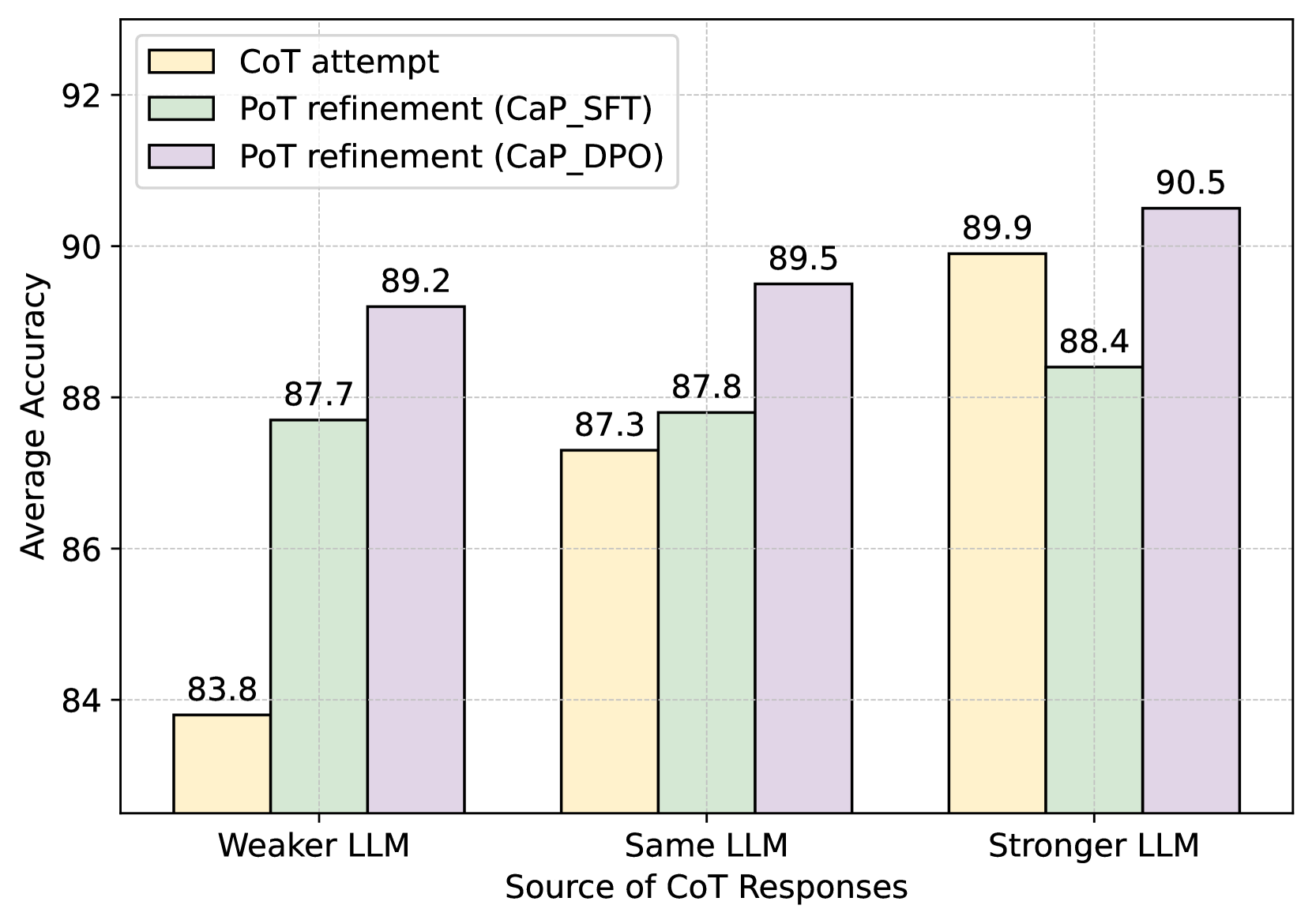
实验结果表明,CaP方法在多个基准测试中取得了显著的性能提升。例如,在需要计算器辅助的数学问题上,CaP的准确率比基线模型提高了10%以上。此外,实验还表明,偏好优化是CaP方法成功的关键因素,能够显著提升LLM的推理能力。
🎯 应用场景
CaP方法可应用于各种需要复杂推理和外部知识辅助的场景,例如科学计算、金融分析、法律咨询等。通过结合LLM的推理能力和外部工具的精确性,CaP能够提供更准确、更可靠的解决方案。未来,CaP有望成为提升LLM在实际应用中性能的重要手段。
📄 摘要(原文)
Large language models (LLMs) can refine their responses based on feedback, enabling self-improvement through iterative training or test-time refinement. However, existing methods predominantly focus on refinement within the same reasoning format, which may lead to non-correcting behaviors. We propose CaP, a novel approach that uses external tools to refine chain-of-thought (CoT) responses generated by the same or other LLMs. CaP employs a two-stage training process: supervised fine-tuning followed by preference optimization with DPO variants. Our observations highlight the critical role of preference optimization in enabling effective refinement. Additionally, we compare several sampling strategies to leverage CoT and tools at inference time. Experimental results demonstrate CaP's potential for effective cross-reasoning refinement and efficient inference.