Distilling Large Language Models for Efficient Clinical Information Extraction
作者: Karthik S. Vedula, Annika Gupta, Akshay Swaminathan, Ivan Lopez, Suhana Bedi, Nigam H. Shah
分类: cs.CL
发布日期: 2024-12-21
备注: 19 pages, 1 figure, 10 tables
💡 一句话要点
利用知识蒸馏,高效提取临床信息,降低LLM计算成本。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识蒸馏 临床信息提取 命名实体识别 大型语言模型 BERT 医学本体 计算效率
📋 核心要点
- 大型语言模型在临床信息提取中表现优异,但其高昂的计算成本阻碍了实际应用。
- 论文提出利用知识蒸馏技术,将大型语言模型的知识迁移到小型BERT模型,降低计算需求。
- 实验表明,蒸馏后的BERT模型在NER任务上性能与LLM相当,但速度更快、成本更低。
📝 摘要(中文)
大型语言模型(LLM)在临床信息提取方面表现出色,但其计算需求限制了实际部署。知识蒸馏提供了一种潜在的解决方案,即将知识从较大的模型转移到较小的模型。本文评估了蒸馏BERT模型在临床命名实体识别(NER)任务中的性能,这些模型比现代LLM小约1000倍。我们利用最先进的LLM(Gemini和OpenAI模型)和医学本体(RxNorm和SNOMED)作为教师标签器,用于药物、疾病和症状提取。我们将该方法应用于超过3300份临床笔记,涵盖五个公开可用的数据集,并将蒸馏BERT模型与教师标签器以及在人工标签上微调的BERT模型进行了比较。使用MedAlign数据集的临床笔记进行了外部验证。结果表明,蒸馏BERT模型在NER任务上实现了与大型LLM相似的性能,同时推理速度更快(最高快12倍)且成本更低(最高便宜101倍)。知识蒸馏为临床信息提取提供了一种计算高效且可扩展的替代方案。
🔬 方法详解
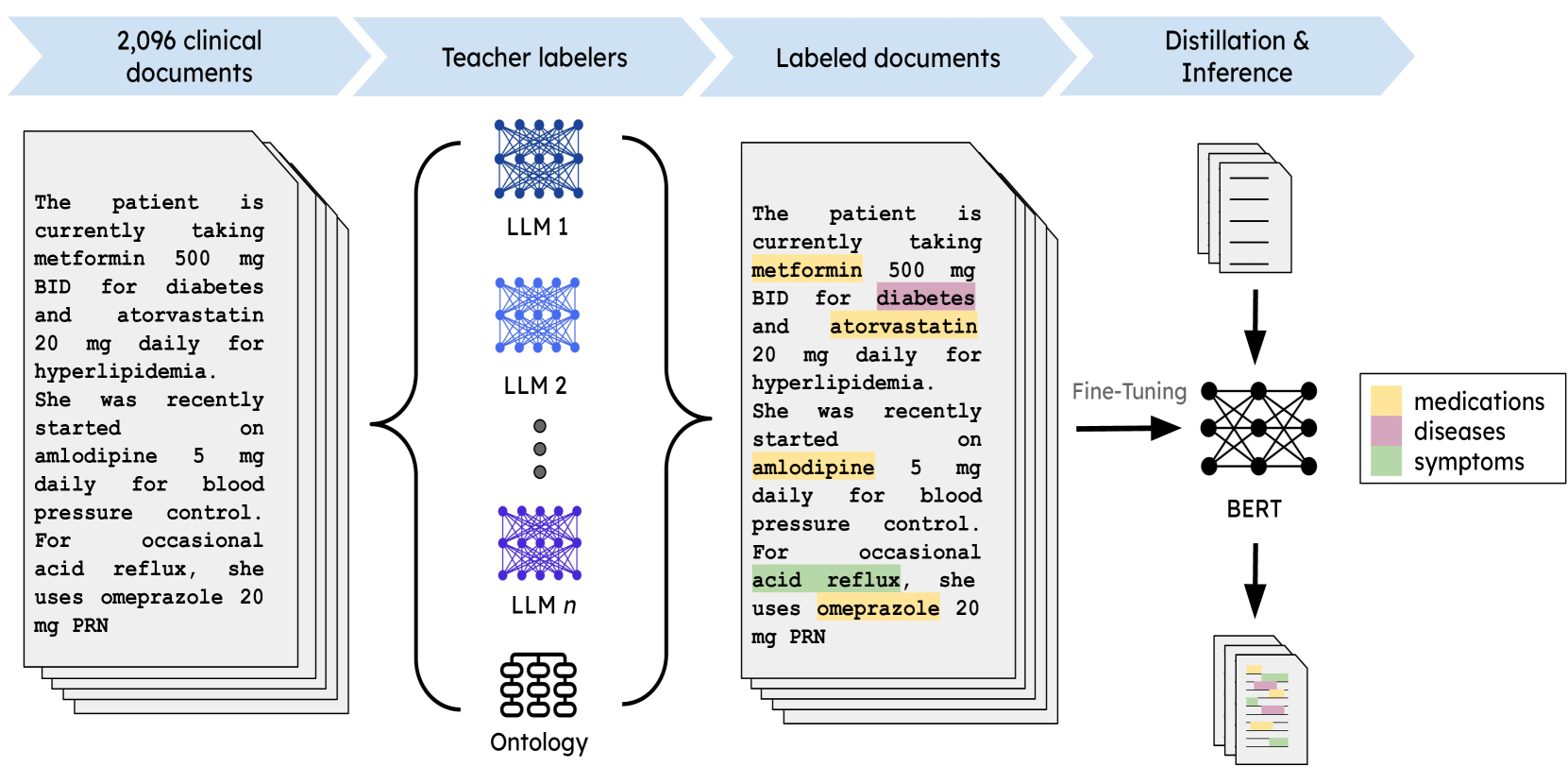
问题定义:论文旨在解决大型语言模型(LLM)在临床信息提取中计算成本过高的问题。现有方法依赖于计算资源密集型的LLM,限制了其在资源受限环境中的部署和应用。
核心思路:核心思路是利用知识蒸馏技术,将大型LLM(教师模型)的知识迁移到小型BERT模型(学生模型)。通过让学生模型学习教师模型的输出分布,使其在保持较高性能的同时,显著降低计算复杂度。
技术框架:整体框架包括以下几个主要阶段:1) 使用大型LLM(如Gemini和OpenAI模型)和医学本体(RxNorm和SNOMED)作为教师标签器,对临床文本进行标注;2) 使用教师标签器生成的标签训练小型BERT模型(学生模型);3) 在多个公开可用的临床数据集上评估蒸馏BERT模型的性能,并与教师模型和在人工标注数据上微调的BERT模型进行比较;4) 使用MedAlign数据集进行外部验证。
关键创新:关键创新在于利用LLM和医学本体作为教师标签器,自动生成大规模的训练数据,从而避免了人工标注的成本和局限性。此外,通过知识蒸馏,成功地将LLM的知识迁移到小型BERT模型,实现了性能与效率的平衡。
关键设计:论文使用了BioBERT作为学生模型的骨干网络,并采用交叉熵损失函数进行训练。教师模型的输出概率分布被用作软标签,引导学生模型的学习。具体参数设置和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,蒸馏后的BERT模型在疾病提取任务中F1值为0.84,药物提取任务中F1值为0.87,症状提取任务中F1值为0.68。与教师模型(LLM)相比,性能接近甚至略有提升。更重要的是,蒸馏BERT模型的推理速度比GPT-4o快12倍,比o1-mini快4倍,比Gemini Flash快8倍,成本分别降低了85倍、101倍和2倍。在外部验证数据集上,蒸馏BERT模型在药物、疾病和症状提取任务中分别取得了0.883、0.726和0.699的F1值。
🎯 应用场景
该研究成果可广泛应用于临床信息提取领域,例如电子病历分析、药物警戒、疾病监测等。通过降低计算成本,使得在资源受限的环境中部署高性能的临床信息提取系统成为可能,从而提升医疗服务的效率和质量。未来,可以将该方法应用于更多临床任务和语言,进一步拓展其应用范围。
📄 摘要(原文)
Large language models (LLMs) excel at clinical information extraction but their computational demands limit practical deployment. Knowledge distillation--the process of transferring knowledge from larger to smaller models--offers a potential solution. We evaluate the performance of distilled BERT models, which are approximately 1,000 times smaller than modern LLMs, for clinical named entity recognition (NER) tasks. We leveraged state-of-the-art LLMs (Gemini and OpenAI models) and medical ontologies (RxNorm and SNOMED) as teacher labelers for medication, disease, and symptom extraction. We applied our approach to over 3,300 clinical notes spanning five publicly available datasets, comparing distilled BERT models against both their teacher labelers and BERT models fine-tuned on human labels. External validation was conducted using clinical notes from the MedAlign dataset. For disease extraction, F1 scores were 0.82 (teacher model), 0.89 (BioBERT trained on human labels), and 0.84 (BioBERT-distilled). For medication, F1 scores were 0.84 (teacher model), 0.91 (BioBERT-human), and 0.87 (BioBERT-distilled). For symptoms: F1 score of 0.73 (teacher model) and 0.68 (BioBERT-distilled). Distilled BERT models had faster inference (12x, 4x, 8x faster than GPT-4o, o1-mini, and Gemini Flash respectively) and lower costs (85x, 101x, 2x cheaper than GPT-4o, o1-mini, and Gemini Flash respectively). On the external validation dataset, the distilled BERT model achieved F1 scores of 0.883 (medication), 0.726 (disease), and 0.699 (symptom). Distilled BERT models were up to 101x cheaper and 12x faster than state-of-the-art LLMs while achieving similar performance on NER tasks. Distillation offers a computationally efficient and scalable alternative to large LLMs for clinical information extraction.