NILE: Internal Consistency Alignment in Large Language Models
作者: Minda Hu, Qiyuan Zhang, Yufei Wang, Bowei He, Hongru Wang, Jingyan Zhou, Liangyou Li, Yasheng Wang, Chen Ma, Irwin King
分类: cs.CL
发布日期: 2024-12-21 (更新: 2025-09-20)
备注: This work has been accepted by EMNLP 2025
💡 一句话要点
NILE:通过内部一致性对齐提升大型语言模型指令微调效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 指令微调 内部一致性 数据集优化 知识对齐
📋 核心要点
- 现有指令微调数据集与LLM预训练获得的内部知识不一致,降低了微调效果,成为提升LLM性能的瓶颈。
- NILE框架通过提取LLM内部知识来修正指令微调数据集,并提出内部一致性过滤方法筛选训练样本,保证数据一致性。
- 实验表明,使用NILE对齐的数据集进行指令微调,在多个评估数据集上显著提升了LLM的性能,最高提升达68.5%。
📝 摘要(中文)
指令微调(IFT)是增强LLM与人类意图对齐的关键步骤,对数据集质量有很高要求。然而,现有的IFT数据集通常包含与LLM在预训练阶段学习到的内部知识不一致的知识,这会严重影响IFT的效果。为了解决这个问题,我们提出了NILE(iNternal consIstency aLignmEnt)框架,旨在优化IFT数据集,以进一步释放LLM的能力。NILE通过引出目标预训练LLM对应于指令数据的内部知识来运行。内部知识被用来修改IFT数据集中的答案。此外,我们提出了一种新颖的内部一致性过滤(ICF)方法来过滤训练样本,确保其与LLM的内部知识高度一致。实验表明,NILE对齐的IFT数据集显著提高了LLM在多个LLM能力评估数据集上的性能,在Arena-Hard上实现了高达66.6%的增益,在Alpaca-Eval V2上实现了68.5%的增益。进一步的分析证实了NILE框架的每个组成部分都对这些显著的性能改进做出了贡献,并提供了令人信服的证据,表明数据集与预训练内部知识的一致性对于最大化LLM的潜力至关重要。
🔬 方法详解
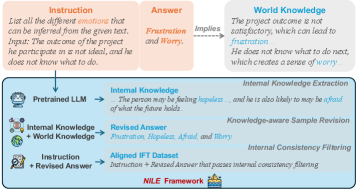
问题定义:论文旨在解决指令微调(IFT)数据集与大型语言模型(LLM)预训练知识不一致的问题。现有的IFT数据集可能包含与LLM内部知识冲突的信息,导致微调后的模型性能受限,无法充分发挥LLM的潜力。因此,如何构建与LLM内部知识一致的高质量IFT数据集是亟待解决的问题。
核心思路:论文的核心思路是利用LLM自身预训练获得的内部知识来指导IFT数据集的构建。具体来说,首先从LLM中提取与指令相关的内部知识,然后利用这些知识来修正或过滤IFT数据集中的样本,从而确保数据集与LLM的内部知识保持一致。这种方法的核心在于认为LLM的内部知识是高质量的,应该被用来指导微调过程。
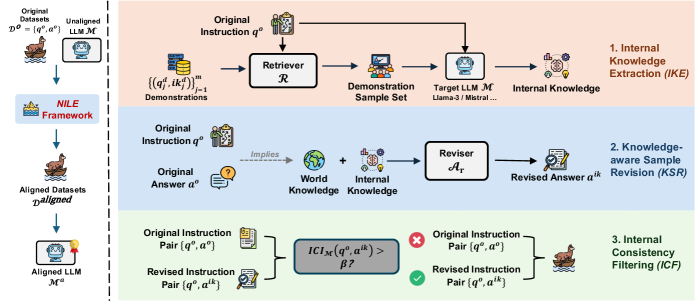
技术框架:NILE框架包含两个主要组成部分:1) 基于内部知识的答案修正:针对IFT数据集中的每个指令,首先从预训练的LLM中提取相应的内部知识。然后,利用这些内部知识来修正数据集中的答案,使其与LLM的内部知识保持一致。2) 内部一致性过滤(ICF):设计了一种过滤方法,用于筛选IFT数据集中的训练样本。该方法基于样本与LLM内部知识的一致性程度来判断样本的质量,并过滤掉与内部知识不一致的样本。
关键创新:该论文的关键创新在于提出了一个利用LLM自身内部知识来优化IFT数据集的框架。与以往依赖人工标注或外部知识库的方法不同,NILE直接利用LLM的预训练知识来指导数据集的构建,从而避免了引入外部噪声或与LLM内部知识冲突的信息。此外,ICF方法提供了一种自动化的数据清洗方式,能够有效提高IFT数据集的质量。
关键设计:在答案修正阶段,论文可能采用了某种形式的知识提取技术,例如提示工程(Prompt Engineering)或知识探测(Knowledge Probing)来从LLM中获取内部知识。在ICF阶段,可能设计了一种一致性评分函数,用于衡量样本与LLM内部知识的一致性程度。具体的参数设置、损失函数和网络结构等技术细节未知,需要参考论文原文。
🖼️ 关键图片
📊 实验亮点
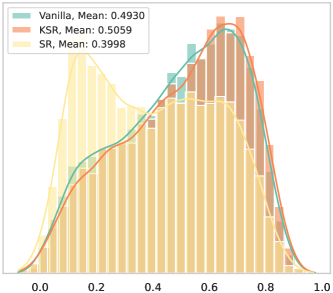
实验结果表明,使用NILE框架对齐的IFT数据集能够显著提升LLM的性能。在Arena-Hard数据集上,性能提升高达66.6%,在Alpaca-Eval V2数据集上,性能提升高达68.5%。这些结果表明,与LLM内部知识一致的数据集对于充分发挥LLM的潜力至关重要。
🎯 应用场景
该研究成果可广泛应用于各种需要指令微调的大型语言模型,例如对话系统、文本生成、问答系统等。通过提升指令微调数据集的质量,可以显著提高LLM在各种任务上的性能,使其更好地理解和执行人类指令,从而实现更智能、更可靠的人工智能应用。
📄 摘要(原文)
As a crucial step to enhance LLMs alignment with human intentions, Instruction Fine-Tuning (IFT) has a high demand on dataset quality. However, existing IFT datasets often contain knowledge that is inconsistent with LLMs' internal knowledge learned from the pre-training phase, which can greatly affect the efficacy of IFT. To address this issue, we introduce NILE (iNternal consIstency aLignmEnt) framework, aimed at optimizing IFT datasets to unlock LLMs' capability further. NILE operates by eliciting target pre-trained LLM's internal knowledge corresponding to instruction data. The internal knowledge is leveraged to revise the answer in IFT datasets. Additionally, we propose a novel Internal Consistency Filtering (ICF) method to filter training samples, ensuring its high consistency with LLM's internal knowledge. Our experiments demonstrate that NILE-aligned IFT datasets sharply boost LLM performance across multiple LLM ability evaluation datasets, achieving up to 66.6% gain on Arena-Hard and 68.5% on Alpaca-Eval V2. Further analysis confirms that each component of the NILE}framework contributes to these substantial performance improvements, and provides compelling evidence that dataset consistency with pre-trained internal knowledge is pivotal for maximizing LLM potential.