Chained Tuning Leads to Biased Forgetting
作者: Megan Ung, Alicia Sun, Samuel J. Bell, Bhaktipriya Radharapu, Levent Sagun, Adina Williams
分类: cs.CL
发布日期: 2024-12-21 (更新: 2024-12-24)
💡 一句话要点
链式调优导致大语言模型产生偏差性遗忘,安全性受损
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 链式微调 灾难性遗忘 安全性对齐 偏差性遗忘
📋 核心要点
- 现有大语言模型微调易发生灾难性遗忘,损害模型安全性,尤其是在链式微调场景下。
- 论文核心在于发现并量化了链式微调中存在的偏差性遗忘现象,即对特定群体安全信息的遗忘程度更高。
- 通过系统评估任务顺序对遗忘的影响,并提出缓解措施,以期改善模型安全性,减少毒性。
📝 摘要(中文)
大型语言模型(LLM)通常针对下游任务进行微调,但这可能会降低先前训练中学习到的能力。这种现象通常被称为灾难性遗忘,对已部署模型的安全性具有重要的潜在影响。在这项工作中,我们首先表明,在下游任务上训练的模型比以相反顺序训练的模型更容易忘记其安全性调整。其次,我们表明,遗忘对某些群体的安全信息的影响不成比例。为了量化这种现象,我们定义了一个新的指标,我们称之为偏差性遗忘。我们对任务排序对遗忘的影响进行了系统评估,并应用了可以帮助模型从观察到的遗忘中恢复的缓解措施。我们希望我们的发现能够更好地为持续学习环境中链式微调LLM的方法提供信息,从而实现更安全、毒性更小的模型的训练。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在链式微调过程中出现的偏差性遗忘问题。现有方法在微调过程中容易导致模型忘记先前学习到的知识,特别是安全性相关的知识,从而降低模型的安全性和可靠性。这种遗忘现象对不同群体的影响程度不同,导致模型产生偏差。
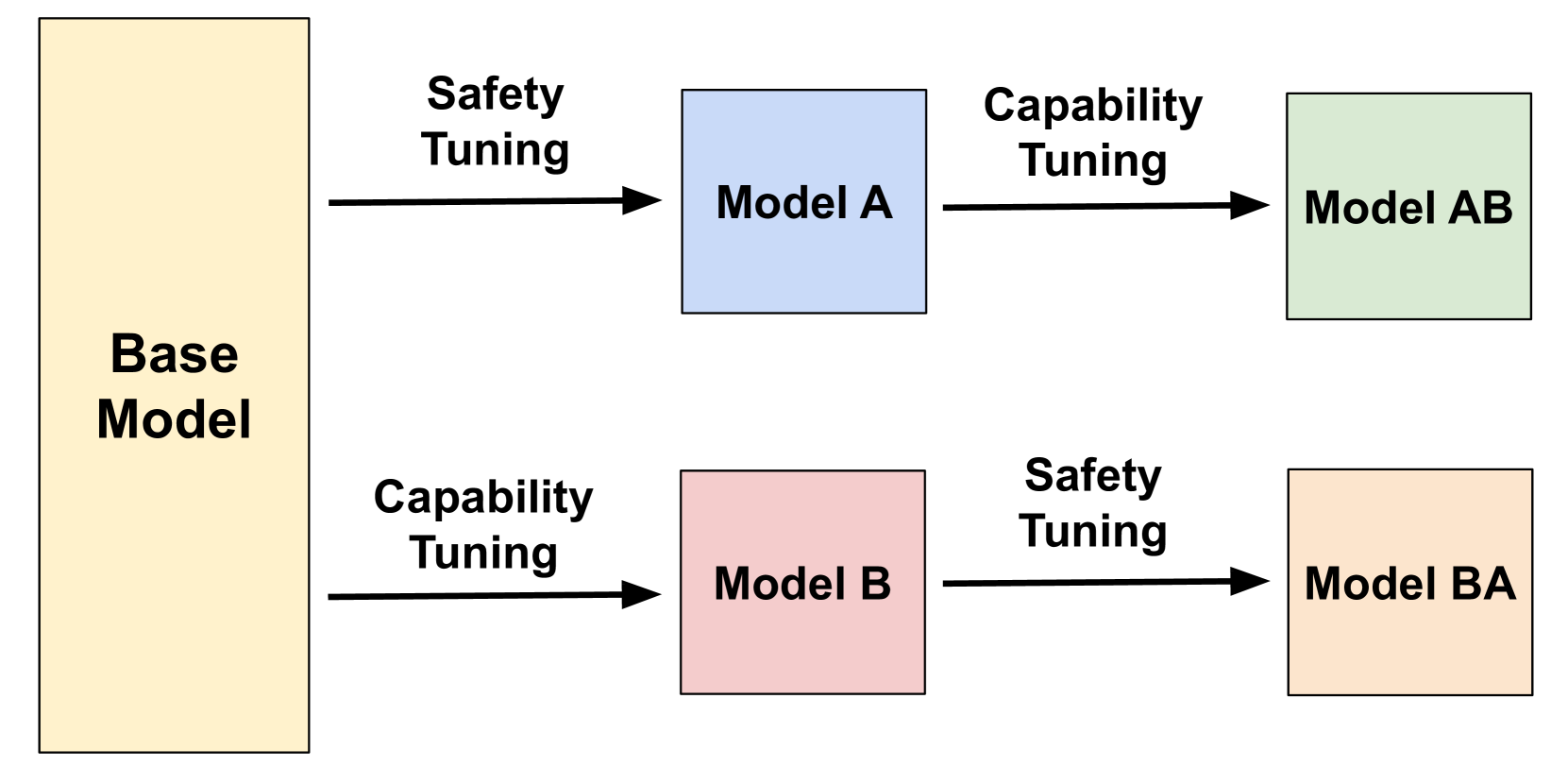
核心思路:论文的核心思路是研究任务顺序对遗忘的影响,并提出相应的缓解措施。通过改变微调任务的顺序,例如先进行安全性调整再进行下游任务训练,可以减轻模型对安全性知识的遗忘。此外,论文还提出了一个名为“偏差性遗忘”的新指标,用于量化模型对不同群体安全信息的遗忘程度。
技术框架:论文的技术框架主要包括以下几个部分:1) 定义偏差性遗忘指标,用于量化模型对不同群体安全信息的遗忘程度;2) 设计实验,系统评估任务顺序对遗忘的影响;3) 提出缓解措施,例如改变微调任务的顺序,以减轻模型对安全性知识的遗忘;4) 分析实验结果,验证缓解措施的有效性。
关键创新:论文最重要的技术创新点在于提出了“偏差性遗忘”这一新指标,该指标能够量化模型对不同群体安全信息的遗忘程度,为研究链式微调中的遗忘现象提供了一种新的视角。此外,论文还系统地研究了任务顺序对遗忘的影响,并提出了相应的缓解措施,为改善模型的安全性和可靠性提供了有价值的参考。
关键设计:论文的关键设计包括:1) 偏差性遗忘指标的定义,需要考虑不同群体的安全信息以及模型在微调前后的表现;2) 实验设计,需要选择合适的下游任务和安全性调整任务,并控制其他变量;3) 缓解措施的设计,需要考虑如何有效地减轻模型对安全性知识的遗忘,同时保持模型在下游任务上的性能。
🖼️ 关键图片


📊 实验亮点
论文实验结果表明,先进行下游任务训练再进行安全性调整的模型,比以相反顺序训练的模型更容易忘记其安全性调整。此外,遗忘对某些群体的安全信息的影响不成比例,表明存在偏差性遗忘。通过采用提出的缓解措施,可以有效减轻模型对安全性知识的遗忘,提高模型的安全性。
🎯 应用场景
该研究成果可应用于大语言模型的持续学习和安全对齐。通过优化微调任务的顺序和采用相应的缓解措施,可以训练出更安全、毒性更小的模型,降低模型在实际应用中产生有害或不当行为的风险。该研究对于构建负责任的人工智能系统具有重要意义。
📄 摘要(原文)
Large language models (LLMs) are often fine-tuned for use on downstream tasks, though this can degrade capabilities learned during previous training. This phenomenon, often referred to as catastrophic forgetting, has important potential implications for the safety of deployed models. In this work, we first show that models trained on downstream tasks forget their safety tuning to a greater extent than models trained in the opposite order. Second, we show that forgetting disproportionately impacts safety information about certain groups. To quantify this phenomenon, we define a new metric we term biased forgetting. We conduct a systematic evaluation of the effects of task ordering on forgetting and apply mitigations that can help the model recover from the forgetting observed. We hope our findings can better inform methods for chaining the finetuning of LLMs in continual learning settings to enable training of safer and less toxic models.