Deliberative Alignment: Reasoning Enables Safer Language Models
作者: Melody Y. Guan, Manas Joglekar, Eric Wallace, Saachi Jain, Boaz Barak, Alec Helyar, Rachel Dias, Andrea Vallone, Hongyu Ren, Jason Wei, Hyung Won Chung, Sam Toyer, Johannes Heidecke, Alex Beutel, Amelia Glaese
分类: cs.CL, cs.AI, cs.CY, cs.LG
发布日期: 2024-12-20 (更新: 2025-01-08)
备注: 24 pages
💡 一句话要点
提出审慎对齐方法,通过推理提升语言模型安全性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型安全 对齐方法 推理能力 鲁棒性 泛化能力 安全策略 显式推理
📋 核心要点
- 现有大规模语言模型难以可靠地遵守安全原则,尤其是在安全攸关领域。
- 审慎对齐方法直接教导模型安全规范,并训练模型在回答前进行显式回忆和推理。
- 实验表明,该方法提高了模型对安全策略的遵守,并增强了鲁棒性和泛化能力。
📝 摘要(中文)
随着大规模语言模型在安全攸关领域的影响日益增加,确保它们可靠地遵守明确定义的原则仍然是一项根本性挑战。我们介绍了一种新的范式——审慎对齐,它直接教导模型安全规范,并训练模型在回答之前显式地回忆和准确地推理这些规范。我们使用这种方法来对齐 OpenAI 的 o-series 模型,并在不需要人工编写的思维链或答案的情况下,实现了对 OpenAI 安全策略的高度精确的遵守。审慎对齐通过同时提高对越狱的鲁棒性和降低过度拒绝率来推动帕累托前沿,并且还提高了分布外泛化能力。我们证明,对明确指定的策略进行推理能够实现更具可扩展性、可信性和可解释性的对齐。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在安全关键领域应用时,难以可靠遵守预定义安全策略的问题。现有方法,如基于人工标注数据的微调,往往泛化能力不足,容易被对抗性攻击(jailbreak)绕过,并且过度拒绝(overrefusal)合法请求。
核心思路:论文的核心思路是让模型在生成答案之前,显式地回忆并推理安全策略。通过将安全策略作为模型的输入,并训练模型基于这些策略进行推理,从而提高模型对安全规范的理解和遵守程度。这种方法旨在增强模型的鲁棒性、泛化能力和可解释性。
技术框架:审慎对齐方法包含以下主要阶段:1) 安全规范编码:将安全策略以文本形式输入模型。2) 推理训练:训练模型基于安全规范进行推理,判断给定输入是否违反安全策略。3) 答案生成:根据推理结果,生成符合安全规范的答案。整个过程可以看作是一个“回忆-推理-生成”的流程。
关键创新:该方法最重要的创新点在于引入了显式的安全策略推理步骤。与传统的隐式对齐方法不同,审慎对齐方法让模型能够明确地意识到安全规范的存在,并基于这些规范进行决策。这种显式推理过程提高了模型的可解释性和可控性,并增强了模型的鲁棒性。
关键设计:论文使用 OpenAI 的 o-series 模型作为基础模型。在训练过程中,使用了对比学习损失函数,鼓励模型将符合安全规范的输入与安全策略对齐,并将违反安全规范的输入与安全策略分离。此外,论文还探索了不同的安全策略编码方式,例如使用自然语言描述或形式化规则。
🖼️ 关键图片
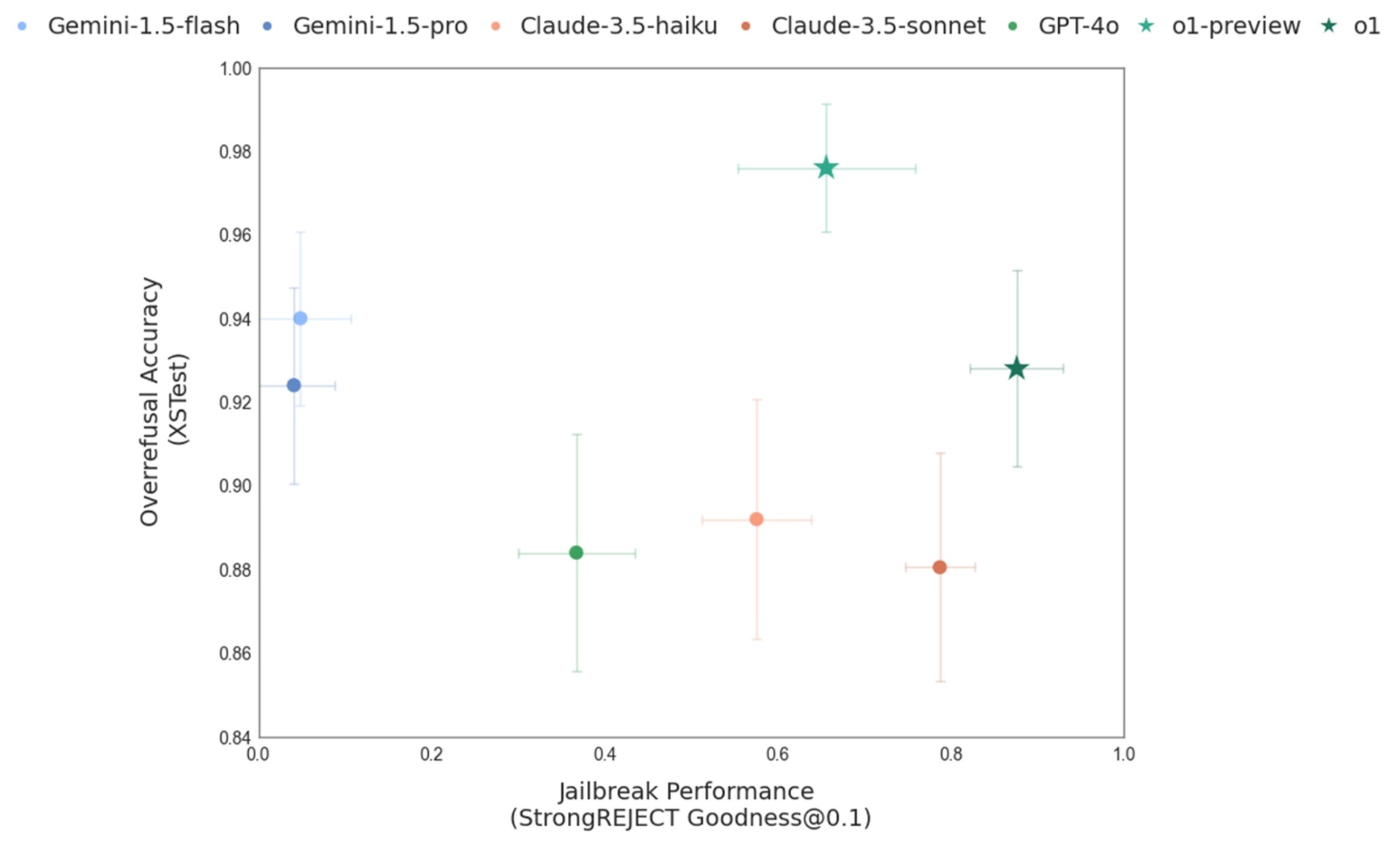

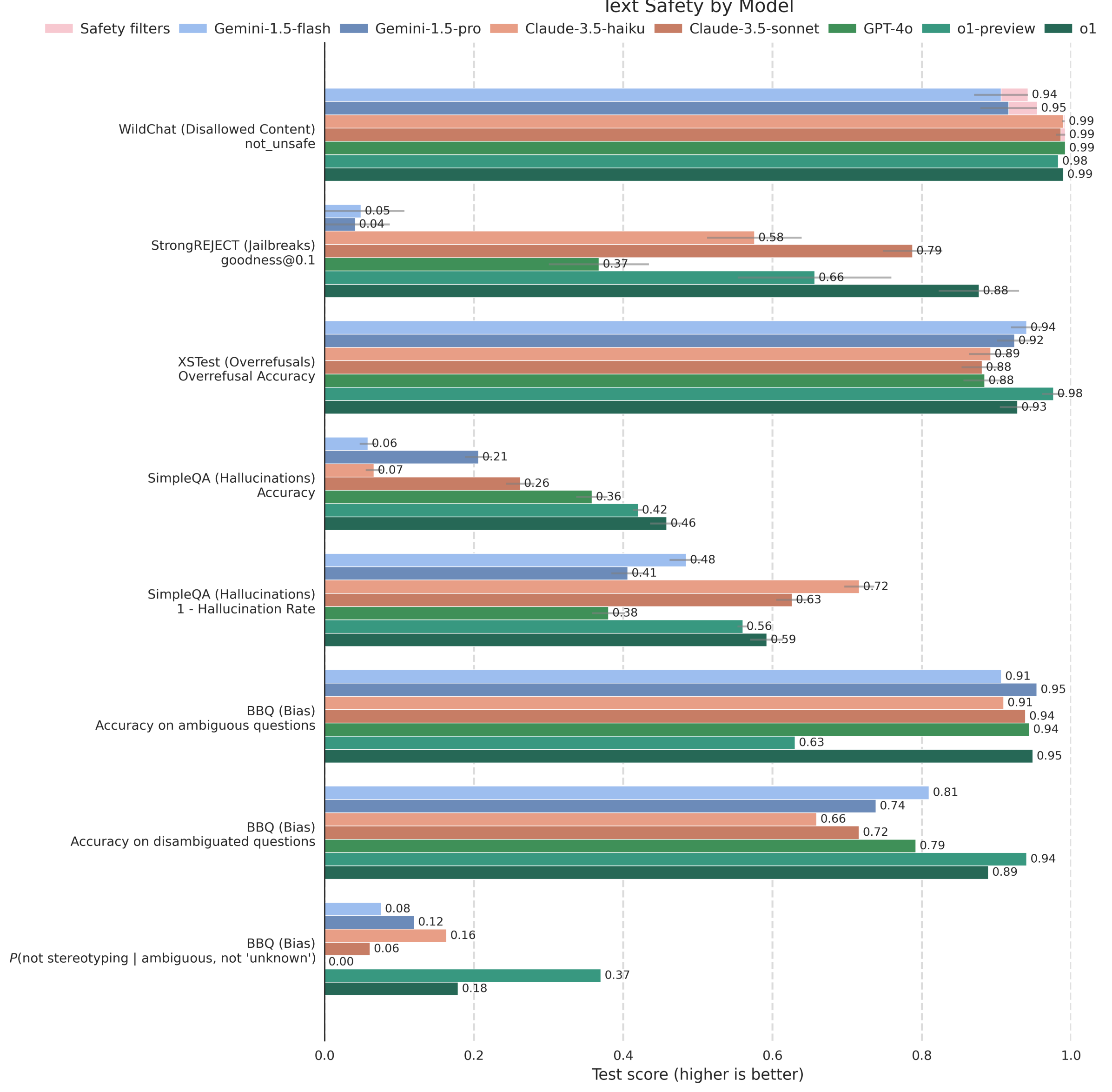
📊 实验亮点
实验结果表明,审慎对齐方法在提高模型对 OpenAI 安全策略的遵守程度方面取得了显著效果。与现有方法相比,该方法在提高对越狱攻击的鲁棒性的同时,降低了过度拒绝率。此外,该方法还提高了模型在分布外数据上的泛化能力,表明其具有更强的适应性。
🎯 应用场景
该研究成果可应用于各种需要安全保障的语言模型应用场景,例如:自动驾驶、医疗诊断、金融风控等。通过提高语言模型对安全规范的遵守程度,可以降低模型在这些领域应用时可能带来的风险,并增强用户对模型的信任度。未来,该方法还可以扩展到其他类型的规范和约束,例如道德规范、法律法规等。
📄 摘要(原文)
As large-scale language models increasingly impact safety-critical domains, ensuring their reliable adherence to well-defined principles remains a fundamental challenge. We introduce Deliberative Alignment, a new paradigm that directly teaches the model safety specifications and trains it to explicitly recall and accurately reason over the specifications before answering. We used this approach to align OpenAI's o-series models, and achieved highly precise adherence to OpenAI's safety policies, without requiring human-written chain-of-thoughts or answers. Deliberative Alignment pushes the Pareto frontier by simultaneously increasing robustness to jailbreaks while decreasing overrefusal rates, and also improves out-of-distribution generalization. We demonstrate that reasoning over explicitly specified policies enables more scalable, trustworthy, and interpretable alignment.