BabyHGRN: Exploring RNNs for Sample-Efficient Training of Language Models
作者: Patrick Haller, Jonas Golde, Alan Akbik
分类: cs.CL
发布日期: 2024-12-20
备注: 7 pages, 7 figures and tables, Published in Proceedings of the BabyLM Challenge 2025
期刊: In Proceedings of the 2nd BabyLM Challenge at the 28th Conference on Computational Natural Language Learning, CoNLL 2024, pages 82 to 94, Miami, FL, USA. Association for Computational Linguistics
💡 一句话要点
BabyHGRN:探索RNN在低资源语言模型训练中的高效性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 循环神经网络 低资源学习 语言建模 HGRN2 知识蒸馏
📋 核心要点
- Transformer模型在语言建模中占据主导地位,但在资源受限场景下训练成本高昂,效率较低。
- 论文提出基于HGRN2的BABYHGRN模型,利用RNN的特性,旨在实现低资源下的高效语言建模。
- 实验结果表明,BABYHGRN在多个基准测试中优于Transformer模型,验证了RNN在低资源场景下的潜力。
📝 摘要(中文)
本文探讨了循环神经网络(RNN)和其他亚二次复杂度架构在低资源语言建模场景中作为Transformer模型替代方案的潜力。我们利用了最近提出的基于RNN的架构HGRN2(Qin et al., 2024),并将其与基于Transformer的基线模型和其他亚二次复杂度架构(LSTM、xLSTM、Mamba)进行了比较评估。实验结果表明,我们的HGRN2语言模型BABYHGRN在BLiMP、EWoK、GLUE和BEAR基准测试中,优于10M和100M词汇量挑战中的Transformer模型。此外,我们展示了知识蒸馏的积极影响。我们的发现挑战了当前对Transformer架构的过度关注,并表明基于RNN的模型,特别是在资源受限的环境中,是可行的。
🔬 方法详解
问题定义:论文旨在解决低资源语言建模场景下,Transformer模型训练成本高、效率低的问题。现有方法依赖于大规模数据集和计算资源,难以在资源受限的环境中应用。
核心思路:论文的核心思路是探索RNN架构在低资源语言建模中的潜力,特别是利用HGRN2这种新型RNN架构,以期在计算效率和模型性能之间取得更好的平衡。通过更高效的架构设计,降低训练成本,提升模型在小数据集上的泛化能力。
技术框架:BABYHGRN模型基于HGRN2架构,具体的技术框架细节在论文中没有详细展开,但可以推断其包含以下主要模块:输入嵌入层、HGRN2循环层、输出层。训练过程可能包括预训练和微调阶段,并采用了知识蒸馏等技术来进一步提升性能。
关键创新:论文的关键创新在于探索了HGRN2这种新型RNN架构在低资源语言建模中的应用,并证明了其优于Transformer模型的潜力。这挑战了当前对Transformer架构的过度依赖,为低资源场景下的语言建模提供了新的思路。
关键设计:论文中没有详细描述BABYHGRN模型的具体参数设置、损失函数和网络结构等技术细节。但提到使用了HGRN2架构,这表明模型可能采用了HGRN2特有的门控机制和循环结构。此外,知识蒸馏的使用也是一个关键设计,通过将大型模型的知识迁移到小型模型,可以提升BABYHGRN的性能。
🖼️ 关键图片
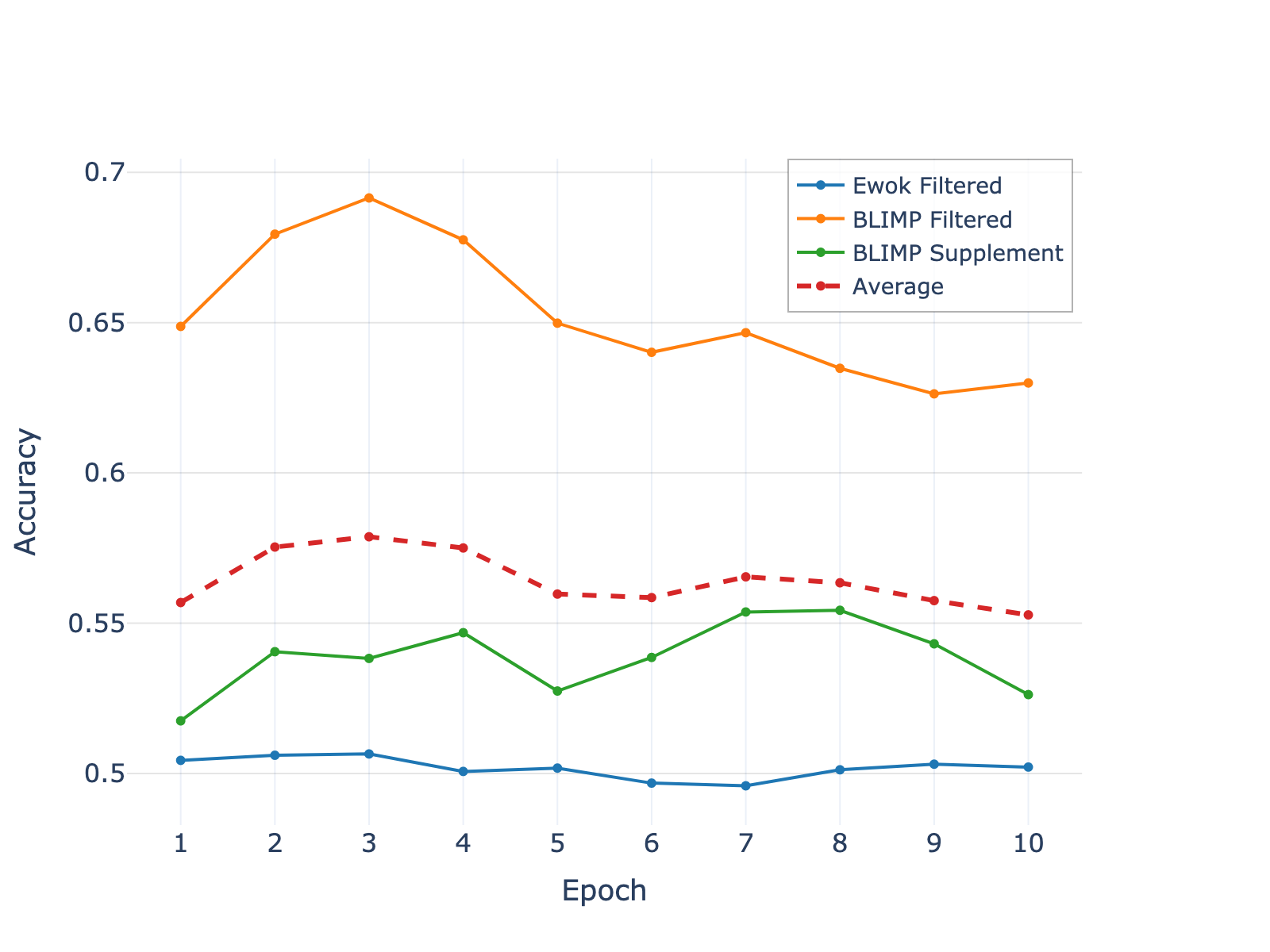

📊 实验亮点
BABYHGRN在10M和100M词汇量挑战中,于BLiMP、EWoK、GLUE和BEAR基准测试上,性能超越了Transformer模型。这表明在低资源环境下,RNN架构具有与Transformer架构竞争的潜力,并为未来的研究方向提供了新的思路。
🎯 应用场景
该研究成果可应用于资源受限的语言建模场景,例如移动设备上的本地语言处理、嵌入式系统中的语音识别、以及针对小语种的机器翻译等。通过降低模型训练和部署的成本,可以促进人工智能技术在更广泛领域的应用。
📄 摘要(原文)
This paper explores the potential of recurrent neural networks (RNNs) and other subquadratic architectures as competitive alternatives to transformer-based models in low-resource language modeling scenarios. We utilize HGRN2 (Qin et al., 2024), a recently proposed RNN-based architecture, and comparatively evaluate its effectiveness against transformer-based baselines and other subquadratic architectures (LSTM, xLSTM, Mamba). Our experimental results show that BABYHGRN, our HGRN2 language model, outperforms transformer-based models in both the 10M and 100M word tracks of the challenge, as measured by their performance on the BLiMP, EWoK, GLUE and BEAR benchmarks. Further, we show the positive impact of knowledge distillation. Our findings challenge the prevailing focus on transformer architectures and indicate the viability of RNN-based models, particularly in resource-constrained environments.