On the Suitability of pre-trained foundational LLMs for Analysis in German Legal Education
作者: Lorenz Wendlinger, Christian Braun, Abdullah Al Zubaer, Simon Alexander Nonn, Sarah Großkopf, Christofer Fellicious, Michael Granitzer
分类: cs.CL, cs.AI
发布日期: 2024-12-20
备注: 11 pages
💡 一句话要点
评估预训练LLM在德国法律教育分析中的适用性,并提出RAG改进方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 法律教育 检索增强生成 提示工程 法律分析
📋 核心要点
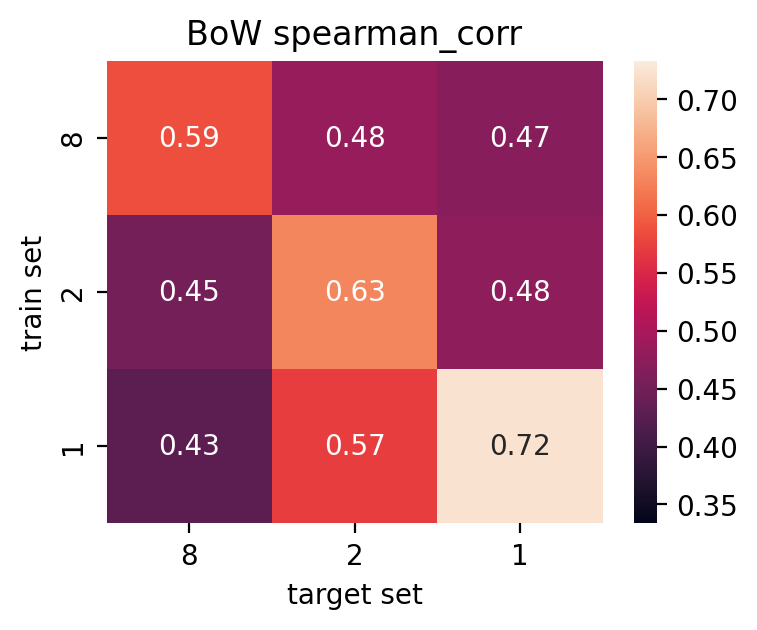
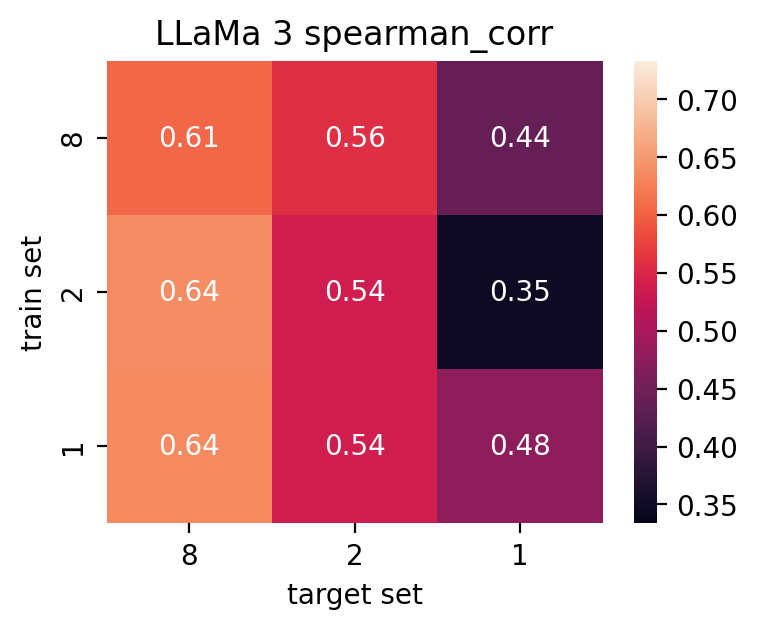
- 现有方法在处理特定法律任务(如“Gutachtenstil”分类)和复杂法律意见时表现不佳,无法满足法律教育分析的需求。
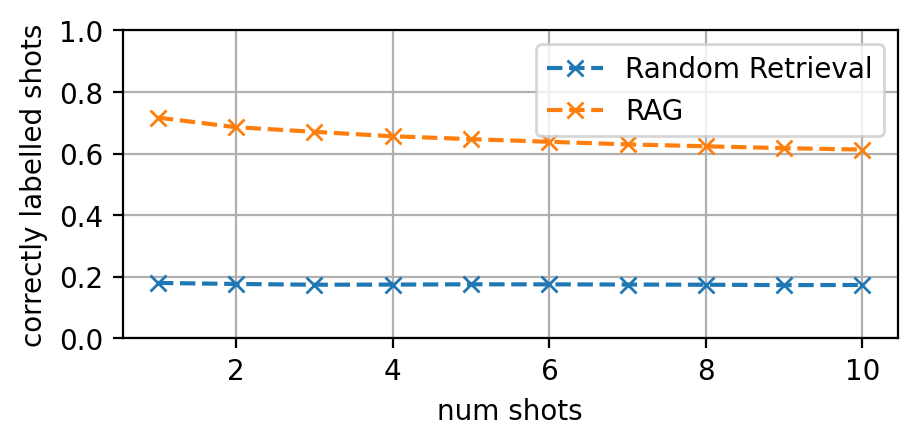
- 提出一种基于检索增强生成(RAG)的提示示例选择方法,通过检索相似案例来增强LLM的法律分析能力。
- 实验表明,RAG方法在数据充足的情况下显著提高了预测性能,并且预训练LLM在少样本或零样本场景下优于基线模型。
📝 摘要(中文)
本文评估了当前开源基础LLM在德国法律教育背景下进行法律分析的适用性。研究表明,这些模型具备一定的指令理解能力和德国法律背景知识,足以胜任部分法律分析任务。然而,在特定任务中,例如“Gutachtenstil”评估风格成分的分类,或处理复杂的法律意见时,模型能力会下降,甚至不如词袋模型。为了解决这个问题,本文提出了一种基于检索增强生成(RAG)的提示示例选择方法,该方法在数据充足的情况下显著提高了预测性能。此外,本文还评估了预训练LLM在论证挖掘和自动作文评分这两个标准任务上的表现,发现其表现更为出色。总而言之,预训练LLM在少样本或零样本场景下优于基线模型,而思维链提示进一步提升了零样本性能。
🔬 方法详解
问题定义:论文旨在评估预训练大型语言模型(LLM)在德国法律教育分析中的适用性。现有方法,如传统的机器学习模型(例如词袋模型),在处理复杂的法律文本和理解法律推理方面存在局限性。此外,即使是预训练的LLM,在特定法律任务(例如“Gutachtenstil”评估风格成分的分类)和处理复杂的法律意见时,其性能也会显著下降。因此,需要研究如何利用LLM的优势,并克服其在法律领域中的局限性。
核心思路:论文的核心思路是利用检索增强生成(RAG)来提升LLM在法律分析任务中的表现。RAG通过从外部知识库中检索相关信息,并将其融入到LLM的输入中,从而增强LLM的知识和推理能力。具体来说,论文提出了一种基于RAG的提示示例选择方法,该方法根据输入文本的相似性,从已有的法律案例库中选择合适的提示示例,并将其提供给LLM,以指导LLM进行法律分析。
技术框架:整体框架包括以下几个主要模块:1) 法律文本输入模块:接收需要分析的法律文本。2) 检索模块:根据输入文本,从法律案例库中检索相似的案例。3) 提示示例选择模块:根据检索结果,选择合适的提示示例。4) LLM推理模块:将输入文本和提示示例输入到LLM中,进行法律分析。5) 结果输出模块:输出LLM的分析结果。
关键创新:论文的关键创新在于提出了基于RAG的提示示例选择方法。与传统的提示方法相比,该方法能够根据输入文本的特点,动态地选择合适的提示示例,从而更好地指导LLM进行法律分析。此外,该方法还能够利用外部知识库中的信息,增强LLM的知识和推理能力。
关键设计:在RAG的实现中,使用了余弦相似度来衡量输入文本和法律案例之间的相似性。在提示示例选择方面,选择了与输入文本最相似的K个案例作为提示示例。在LLM推理方面,使用了Chain-of-Thought prompting来提升LLM的推理能力。具体使用的LLM模型信息未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,提出的RAG方法在数据充足的情况下显著提高了预测性能。在“Gutachtenstil”评估风格成分分类任务中,RAG方法优于传统的词袋模型。此外,预训练LLM在少样本或零样本场景下优于基线模型,而思维链提示进一步提升了零样本性能。具体的性能提升幅度未知。
🎯 应用场景
该研究成果可应用于法律教育、法律咨询、法律信息检索等领域。通过利用预训练LLM和RAG技术,可以提高法律分析的效率和准确性,为法律从业者和学生提供更好的支持。未来,可以将该方法应用于更广泛的法律领域,例如合同审查、法律风险评估等。
📄 摘要(原文)
We show that current open-source foundational LLMs possess instruction capability and German legal background knowledge that is sufficient for some legal analysis in an educational context. However, model capability breaks down in very specific tasks, such as the classification of "Gutachtenstil" appraisal style components, or with complex contexts, such as complete legal opinions. Even with extended context and effective prompting strategies, they cannot match the Bag-of-Words baseline. To combat this, we introduce a Retrieval Augmented Generation based prompt example selection method that substantially improves predictions in high data availability scenarios. We further evaluate the performance of pre-trained LLMs on two standard tasks for argument mining and automated essay scoring and find it to be more adequate. Throughout, pre-trained LLMs improve upon the baseline in scenarios with little or no labeled data with Chain-of-Thought prompting further helping in the zero-shot case.